 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Processing of Deep Neural Networks: A Tutorial and Survey
Aug 13, 2017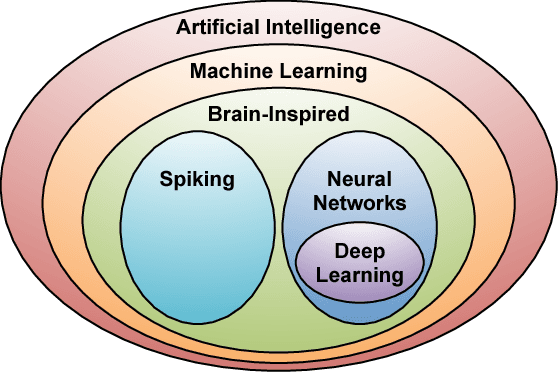
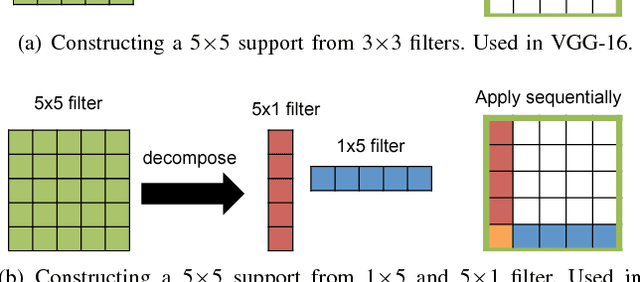
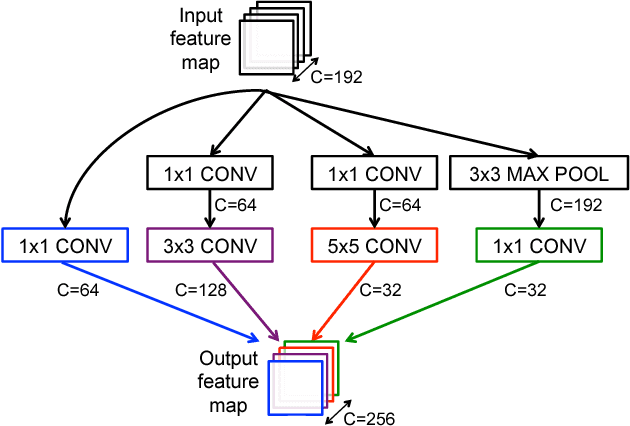
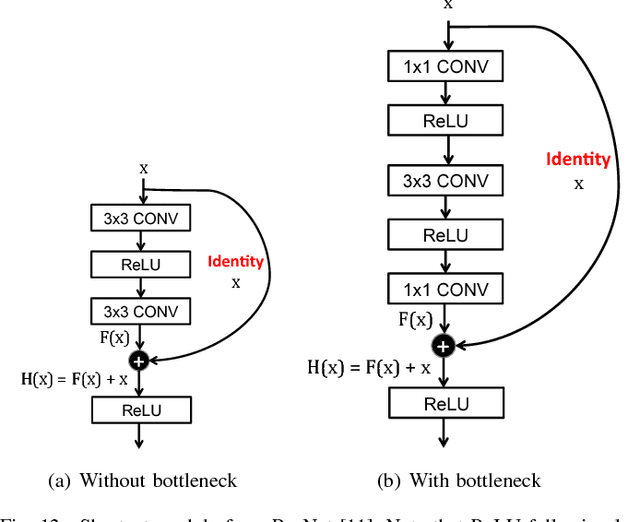
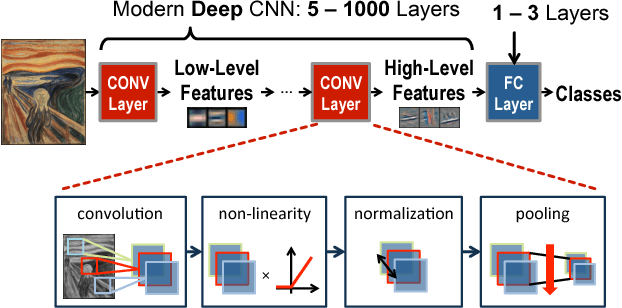
Deep neural networks (DNNs) are currently widely used for many artificial intelligence (AI) applications including computer vision, speech recognition, and robotics. While DNNs deliver state-of-the-art accuracy on many AI tasks, it comes at the cost of high computational complexity. Accordingly, techniques that enable efficient processing of DNNs to improve energy efficiency and throughput without sacrificing application accuracy or increasing hardware cost are critical to the wide deployment of DNNs in AI systems. This article aims to provide a comprehensive tutorial and survey about the recent advances towards the goal of enabling efficient processing of DNNs. Specifically, it will provide an overview of DNNs, discuss various hardware platforms and architectures that support DNNs, and highlight key trends in reducing the computation cost of DNNs either solely via hardware design changes or via joint hardware design and DNN algorithm changes. It will also summarize various development resources that enable researchers and practitioners to quickly get started in this field, and highlight important benchmarking metrics and design considerations that should be used for evaluating the rapidly growing number of DNN hardware designs, optionally including algorithmic co-designs, being proposed in academia and industry. The reader will take away the following concepts from this article: understand the key design considerations for DNNs; be able to evaluate different DNN hardware implementations with benchmarks and comparison metrics; understand the trade-offs between various hardware architectures and platforms; be able to evaluate the utility of various DNN design techniques for efficient processing; and understand recent implementation trends and opportunities.
FAST: A Framework to Accelerate Super-Resolution Processing on Compressed Videos
Aug 04, 2017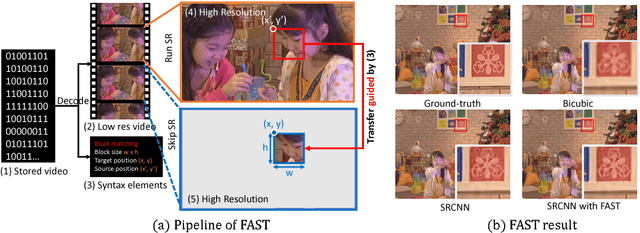
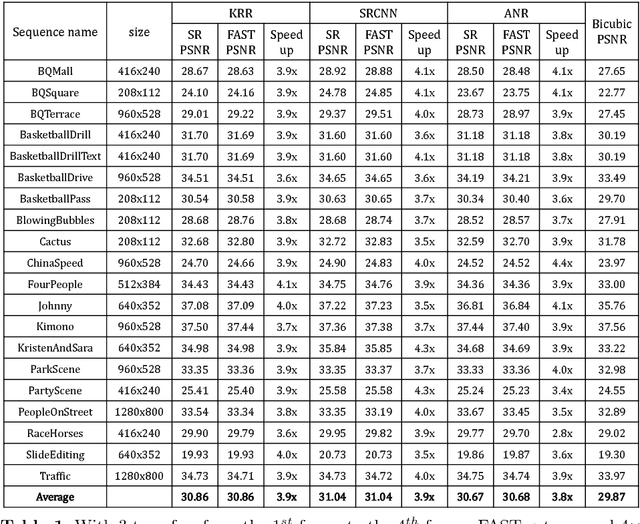
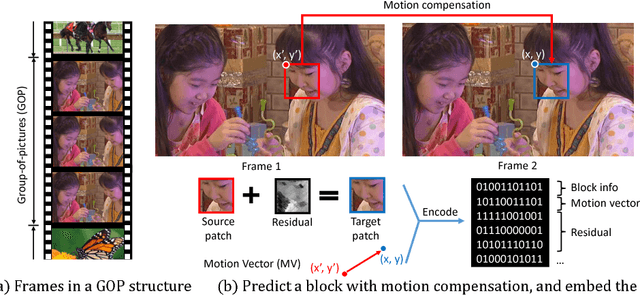
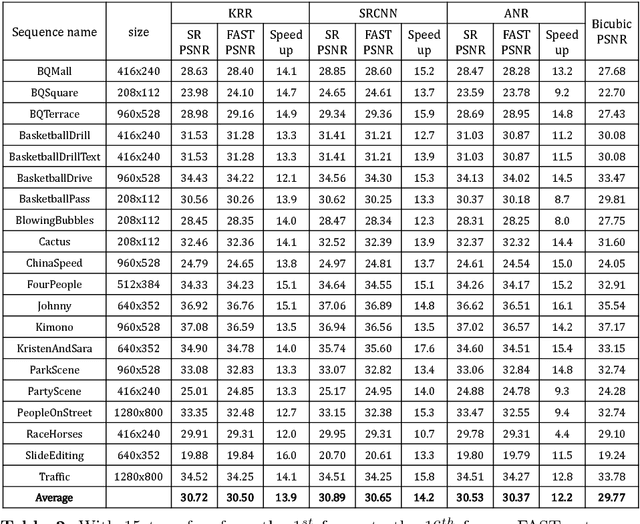
State-of-the-art super-resolution (SR) algorithms require significant computational resources to achieve real-time throughput (e.g., 60Mpixels/s for HD video). This paper introduces FAST (Free Adaptive Super-resolution via Transfer), a framework to accelerate any SR algorithm applied to compressed videos. FAST exploits the temporal correlation between adjacent frames such that SR is only applied to a subset of frames; SR pixels are then transferred to the other frames. The transferring process has negligible computation cost as it uses information already embedded in the compressed video (e.g., motion vectors and residual). Adaptive processing is used to retain accuracy when the temporal correlation is not present (e.g., occlusions). FAST accelerates state-of-the-art SR algorithms by up to 15x with a visual quality loss of 0.2dB. FAST is an important step towards real-time SR algorithms for ultra-HD displays and energy constrained devices (e.g., phones and tablets).
Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning
Apr 18, 2017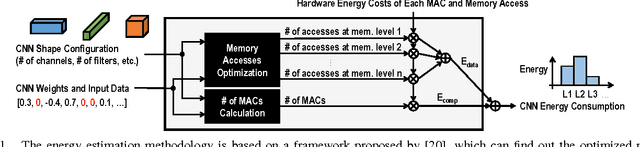
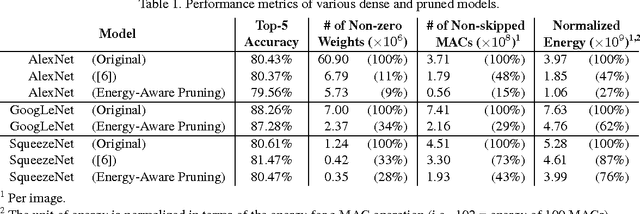
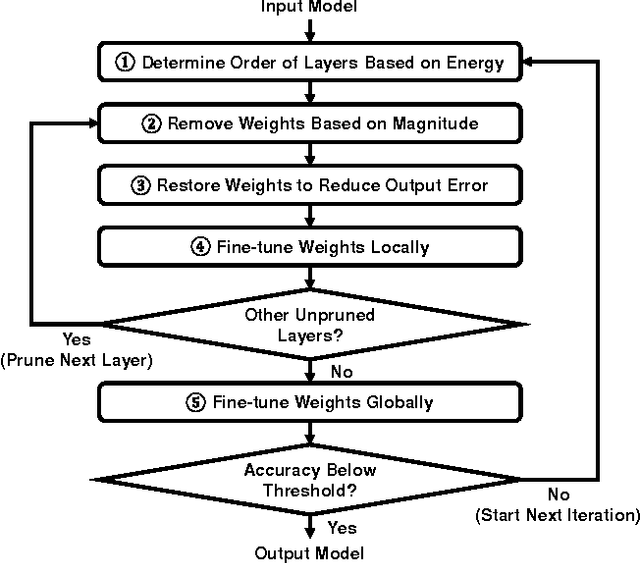
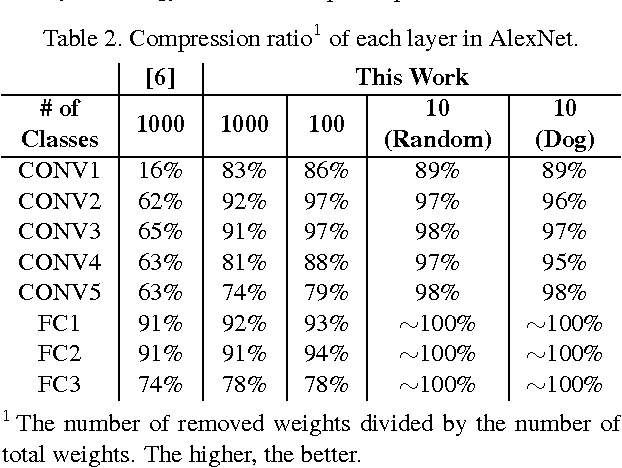
Deep convolutional neural networks (CNNs) are indispensable to state-of-the-art computer vision algorithms. However, they are still rarely deployed on battery-powered mobile devices, such as smartphones and wearable gadgets, where vision algorithms can enable many revolutionary real-world applications. The key limiting factor is the high energy consumption of CNN processing due to its high computational complexity. While there are many previous efforts that try to reduce the CNN model size or amount of computation, we find that they do not necessarily result in lower energy consumption, and therefore do not serve as a good metric for energy cost estimation. To close the gap between CNN design and energy consumption optimization, we propose an energy-aware pruning algorithm for CNNs that directly uses energy consumption estimation of a CNN to guide the pruning process. The energy estimation methodology uses parameters extrapolated from actual hardware measurements that target realistic battery-powered system setups. The proposed layer-by-layer pruning algorithm also prunes more aggressively than previously proposed pruning methods by minimizing the error in output feature maps instead of filter weights. For each layer, the weights are first pruned and then locally fine-tuned with a closed-form least-square solution to quickly restore the accuracy. After all layers are pruned, the entire network is further globally fine-tuned using back-propagation. With the proposed pruning method, the energy consumption of AlexNet and GoogLeNet are reduced by 3.7x and 1.6x, respectively, with less than 1% top-5 accuracy loss. Finally, we show that pruning the AlexNet with a reduced number of target classes can greatly decrease the number of weights but the energy reduction is limited. Energy modeling tool and energy-aware pruned models available at http://eyeriss.mit.edu/energy.html
Towards Closing the Energy Gap Between HOG and CNN Features for Embedded Vision
Mar 17, 2017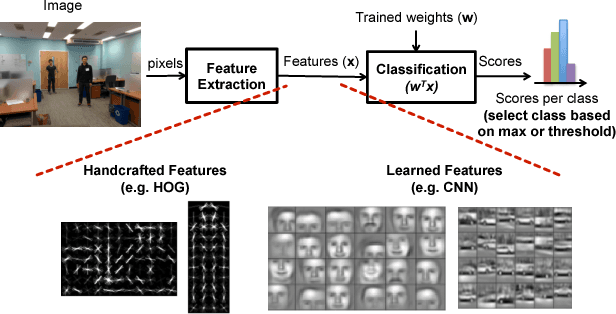
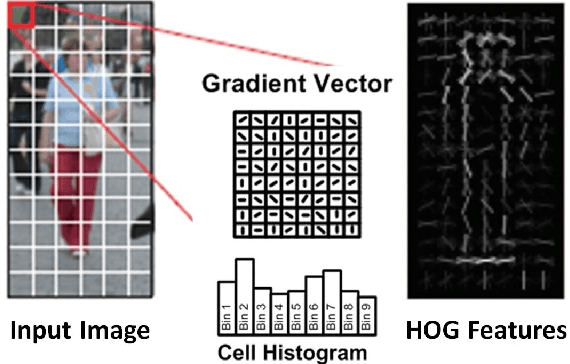
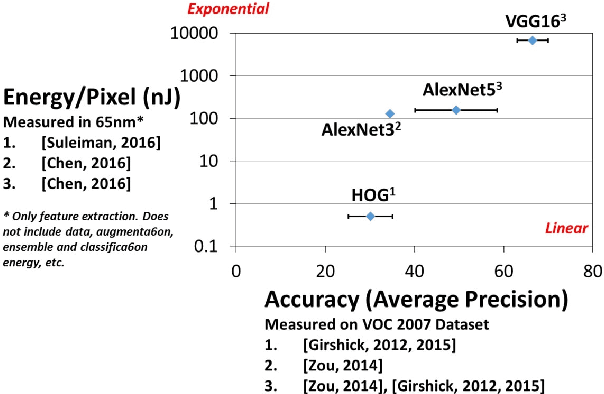
Computer vision enables a wide range of applications in robotics/drones, self-driving cars, smart Internet of Things, and portable/wearable electronics. For many of these applications, local embedded processing is preferred due to privacy and/or latency concerns. Accordingly, energy-efficient embedded vision hardware delivering real-time and robust performance is crucial. While deep learning is gaining popularity in several computer vision algorithms, a significant energy consumption difference exists compared to traditional hand-crafted approaches. In this paper, we provide an in-depth analysis of the computation, energy and accuracy trade-offs between learned features such as deep Convolutional Neural Networks (CNN) and hand-crafted features such as Histogram of Oriented Gradients (HOG). This analysis is supported by measurements from two chips that implement these algorithms. Our goal is to understand the source of the energy discrepancy between the two approaches and to provide insight about the potential areas where CNNs can be improved and eventually approach the energy-efficiency of HOG while maintaining its outstanding performance accuracy.
A 58.6mW Real-Time Programmable Object Detector with Multi-Scale Multi-Object Support Using Deformable Parts Model on 1920x1080 Video at 30fps
Jul 27, 2016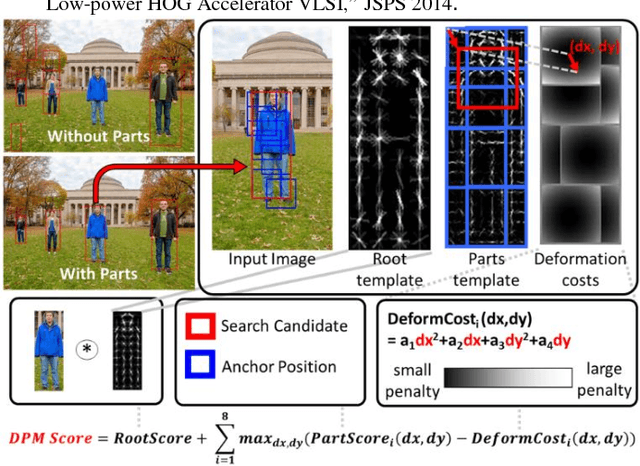
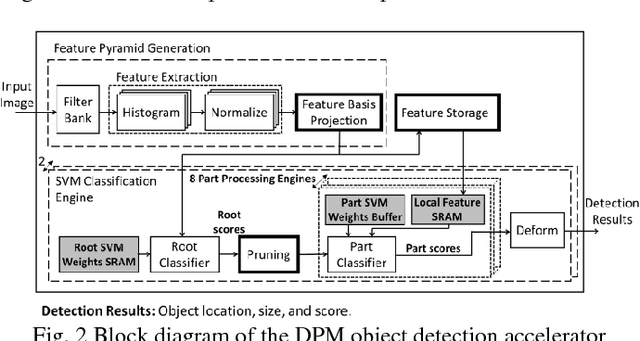
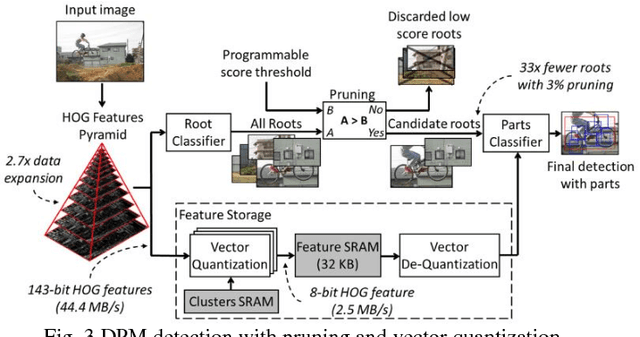
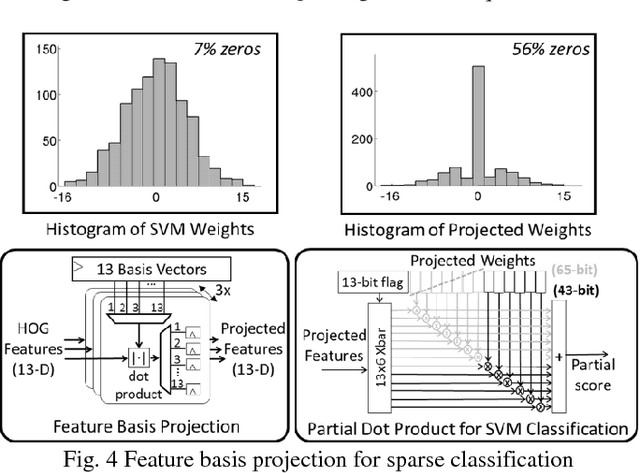
This paper presents a programmable, energy-efficient and real-time object detection accelerator using deformable parts models (DPM), with 2x higher accuracy than traditional rigid body models. With 8 deformable parts detection, three methods are used to address the high computational complexity: classification pruning for 33x fewer parts classification, vector quantization for 15x memory size reduction, and feature basis projection for 2x reduction of the cost of each classification. The chip is implemented in 65nm CMOS technology, and can process HD (1920x1080) images at 30fps without any off-chip storage while consuming only 58.6mW (0.94nJ/pixel, 1168 GOPS/W). The chip has two classification engines to simultaneously detect two different classes of objects. With a tested high throughput of 60fps, the classification engines can be time multiplexed to detect even more than two object classes. It is energy scalable by changing the pruning factor or disabling the parts classification.