 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Conceptualization and Societal Impact of Cross-Cultural Bias
Dec 26, 2025Research has shown that while large language models (LLMs) can generate their responses based on cultural context, they are not perfect and tend to generalize across cultures. However, when evaluating the cultural bias of a language technology on any dataset, researchers may choose not to engage with stakeholders actually using that technology in real life, which evades the very fundamental problem they set out to address. Inspired by the work done by arXiv:2005.14050v2, I set out to analyse recent literature about identifying and evaluating cultural bias in Natural Language Processing (NLP). I picked out 20 papers published in 2025 about cultural bias and came up with a set of observations to allow NLP researchers in the future to conceptualize bias concretely and evaluate its harms effectively. My aim is to advocate for a robust assessment of the societal impact of language technologies exhibiting cross-cultural bias.
On the Challenges of Building Datasets for Hate Speech Detection
Sep 06, 2023Detection of hate speech has been formulated as a standalone application of NLP and different approaches have been adopted for identifying the target groups, obtaining raw data, defining the labeling process, choosing the detection algorithm, and evaluating the performance in the desired setting. However, unlike other downstream tasks, hate speech suffers from the lack of large-sized, carefully curated, generalizable datasets owing to the highly subjective nature of the task. In this paper, we first analyze the issues surrounding hate speech detection through a data-centric lens. We then outline a holistic framework to encapsulate the data creation pipeline across seven broad dimensions by taking the specific example of hate speech towards sexual minorities. We posit that practitioners would benefit from following this framework as a form of best practice when creating hate speech datasets in the future.
bitsa_nlp@LT-EDI-ACL2022: Leveraging Pretrained Language Models for Detecting Homophobia and Transphobia in Social Media Comments
Apr 09, 2022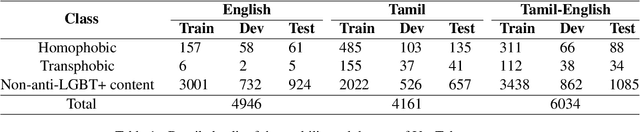


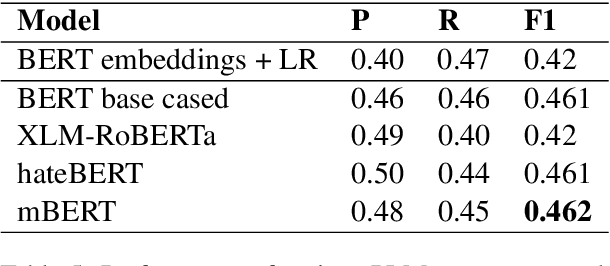
Online social networks are ubiquitous and user-friendly. Nevertheless, it is vital to detect and moderate offensive content to maintain decency and empathy. However, mining social media texts is a complex task since users don't adhere to any fixed patterns. Comments can be written in any combination of languages and many of them may be low-resource. In this paper, we present our system for the LT-EDI shared task on detecting homophobia and transphobia in social media comments. We experiment with a number of monolingual and multilingual transformer based models such as mBERT along with a data augmentation technique for tackling class imbalance. Such pretrained large models have recently shown tremendous success on a variety of benchmark tasks in natural language processing. We observe their performance on a carefully annotated, real life dataset of YouTube comments in English as well as Tamil. Our submission achieved ranks 9, 6 and 3 with a macro-averaged F1-score of 0.42, 0.64 and 0.58 in the English, Tamil and Tamil-English subtasks respectively. The code for the system has been open sourced.