 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrection of Transformer-Based Models with Smoothing Pseudo-Projector
Mar 10, 2026The pseudo-projector is a lightweight modification that can be integrated into existing language models and other neural networks without altering their core architecture. It can be viewed as a hidden-representation corrector that reduces sensitivity to noise by suppressing directions induced by label-irrelevant input content. The design is inspired by the multigrid (MG) paradigm, originally developed to accelerate the convergence of iterative solvers for partial differential equations and boundary value problems, and later extended to more general linear systems through algebraic multigrid methods. We refer to the method as a pseudo-projector because its linear prototype corresponds to a strictly idempotent orthogonal projector, whereas the practical formulation employs learnable restriction and prolongation operators and therefore does not, in general, satisfy the properties of an exact orthogonal projection. We evaluate the proposed approach on transformer-based text classification tasks, as well as controlled synthetic benchmarks, demonstrating its effectiveness in improving training dynamics and robustness. Experimental results, together with supporting theoretical heuristics, indicate consistent improvements in training behavior across a range of settings, with no adverse effects observed otherwise. Our next step will be to extend this approach to language models.
Reasoning-Enhanced Rare-Event Prediction with Balanced Outcome Correction
Jan 23, 2026Rare-event prediction is critical in domains such as healthcare, finance, reliability engineering, customer support, aviation safety, where positive outcomes are infrequent yet potentially catastrophic. Extreme class imbalance biases conventional models toward majority-class predictions, limiting recall, calibration, and operational usefulness. We propose LPCORP (Low-Prevalence CORrector for Prediction)*, a two-stage framework that combines reasoningenhanced prediction with confidence-based outcome correction. A reasoning model first produces enriched predictions from narrative inputs, after which a lightweight logistic-regression classifier evaluates and selectively corrects these outputs to mitigate prevalence-driven bias. We evaluate LPCORP on real-world datasets from medical and consumer service domains. The results show that this method transforms a highly imbalanced setting into a well-balanced one while preserving the original number of samples and without applying any resampling strategies. Test-set evaluation demonstrates substantially improved performance, particularly in precision, which is a known weakness in low-prevalence data. We further provide a costreduction analysis comparing the expenses associated with rare-event damage control without preventive measures to those incurred when low-cost, prediction-based preventive interventions are applied that showed more than 50% reduction in some cases. * Patent pending: U.S. Provisional 63/933,518, filed 8 December 2025.
Optimization of Retrieval-Augmented Generation Context with Outlier Detection
Jul 01, 2024


In this paper, we focus on methods to reduce the size and improve the quality of the prompt context required for question-answering systems. Attempts to increase the number of retrieved chunked documents and thereby enlarge the context related to the query can significantly complicate the processing and decrease the performance of a Large Language Model (LLM) when generating responses to queries. It is well known that a large set of documents retrieved from a database in response to a query may contain irrelevant information, which often leads to hallucinations in the resulting answers. Our goal is to select the most semantically relevant documents, treating the discarded ones as outliers. We propose and evaluate several methods for identifying outliers by creating features that utilize the distances of embedding vectors, retrieved from the vector database, to both the centroid and the query vectors. The methods were evaluated by comparing the similarities of the retrieved LLM responses to ground-truth answers obtained using the OpenAI GPT-4o model. It was found that the greatest improvements were achieved with increasing complexity of the questions and answers.
Dimensionality Reduction in Sentence Transformer Vector Databases with Fast Fourier Transform
Apr 09, 2024



Dimensionality reduction in vector databases is pivotal for streamlining AI data management, enabling efficient storage, faster computation, and improved model performance. This paper explores the benefits of reducing vector database dimensions, with a focus on computational efficiency and overcoming the curse of dimensionality. We introduce a novel application of Fast Fourier Transform (FFT) to dimensionality reduction, a method previously underexploited in this context. By demonstrating its utility across various AI domains, including Retrieval-Augmented Generation (RAG) models and image processing, this FFT-based approach promises to improve data retrieval processes and enhance the efficiency and scalability of AI solutions. The incorporation of FFT may not only optimize operations in real-time processing and recommendation systems but also extend to advanced image processing techniques, where dimensionality reduction can significantly improve performance and analysis efficiency. This paper advocates for the broader adoption of FFT in vector database management, marking a significant stride towards addressing the challenges of data volume and complexity in AI research and applications. Unlike many existing approaches, we directly handle the embedding vectors produced by the model after processing a test input.
Iterative Aggregation Method for Solving Principal Component Analysis Problems
Feb 29, 2016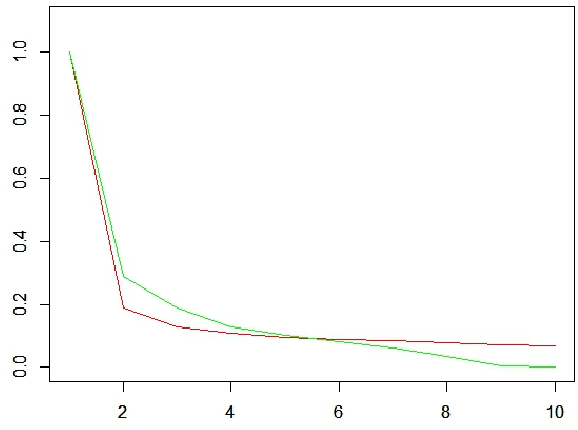
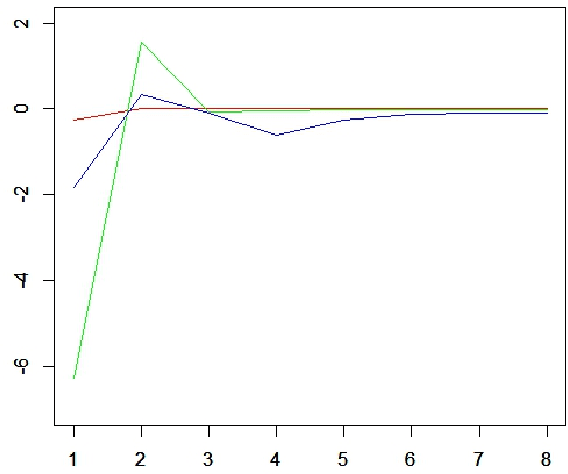
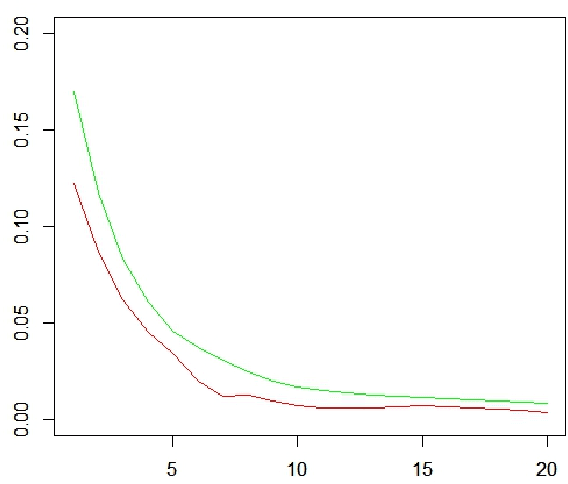
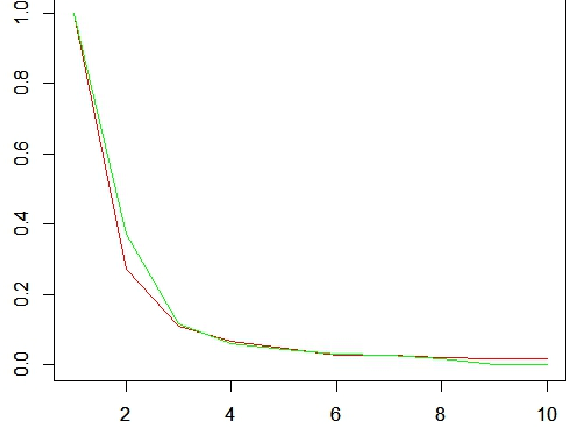
Motivated by the previously developed multilevel aggregation method for solving structural analysis problems a novel two-level aggregation approach for efficient iterative solution of Principal Component Analysis (PCA) problems is proposed. The course aggregation model of the original covariance matrix is used in the iterative solution of the eigenvalue problem by a power iterations method. The method is tested on several data sets consisting of large number of text documents.