 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Matching Principle: A Geometric Theory of Loss Functions for Nuisance-Robust Representation Learning
May 21, 2026Robustness, domain adaptation, photometric and occlusion invariance, compositional generalisation, temporal robustness, alignment safety, and classical anisotropic regularisation are usually treated as separate problems with separate method families. This paper argues that much of their shared structure is one statistical problem: estimate the covariance of label-preserving deployment nuisance, then regularise the encoder Jacobian along a matrix whose range covers that covariance (the matching principle). CORAL, adversarial training, IRM, augmentation, metric learning, Jacobian penalties, and alignment-style constraints are different estimators of that object, not independent robustness tricks. In the linear-Gaussian model we prove closed-form optimality (Theorem A), including cube-root water-filling within the matched range; necessity of range coverage for quadratic Jacobian penalties (Theorem G); the same range dichotomy at deep global minima; and two falsification controls (Lemma C; Corollaries E), with seven conditional consistency lemmas (D1-D7) for estimation under standard identifiability assumptions. We introduce the Trajectory Deviation Index (TDI), a label-free probe of embedding sensitivity when task accuracy or Jacobian Frobenius norm is insufficient. Thirteen pre-registered blocks from classical ML through Qwen2.5-7B test the predicted matched, then isotropic, then wrong-W ordering on geometry and deployment drift; twelve pass, and the sole exception (Office-31) is an eigengap failure named before the run. At 7B scale, matched style-PMH improves selective honesty and preserves Style TDI where standard DPO degrades it. The contribution is naming the deployment nuisance covariance, stating what the regulariser must do, and supplying a closed-form falsifiable theory once that object is identified, not universality on every leaderboard.
Supervised Learning Has a Necessary Geometric Blind Spot: Theory, Consequences, and Minimal Repair
Apr 23, 2026We prove that empirical risk minimisation (ERM) imposes a necessary geometric constraint on learned representations: any encoder that minimises supervised loss must retain non-zero Jacobian sensitivity in directions that are label-correlated in training data but nuisance at test time. This is not a contingent failure of current methods; it is a mathematical consequence of the supervised objective itself. We call this the geometric blind spot of supervised learning (Theorem 1), and show it holds across proper scoring rules, architectures, and dataset sizes. This single theorem unifies four lines of prior empirical work that were previously treated separately: non-robust predictive features, texture bias, corruption fragility, and the robustness-accuracy tradeoff. In this framing, adversarial vulnerability is one consequence of a broader structural fact about supervised learning geometry. We introduce Trajectory Deviation Index (TDI), a diagnostic that measures the theorem's bounded quantity directly, and show why common alternatives miss the key failure mode. PGD adversarial training reaches Jacobian Frobenius 2.91 yet has the worst clean-input geometry (TDI 1.336), while PMH achieves TDI 0.904. TDI is the only metric that detects this dissociation because it measures isotropic path-length distortion -- the exact quantity Theorem 1 bounds. Across seven vision tasks, BERT/SST-2, and ImageNet ViT-B/16 backbones used by CLIP, DINO, and SAM, the blind spot is measurable and repairable. It is present at foundation-model scale, worsens monotonically across language-model sizes (blind-spot ratio 0.860 to 0.765 to 0.742 from 66M to 340M), and is amplified by task-specific ERM fine-tuning (+54%), while PMH repairs it by 11x with one additional training term whose Gaussian form Proposition 5 proves is the unique perturbation law that uniformly penalises the encoder Jacobian.
Robustness of different loss functions and their impact on networks learning capability
Nov 09, 2021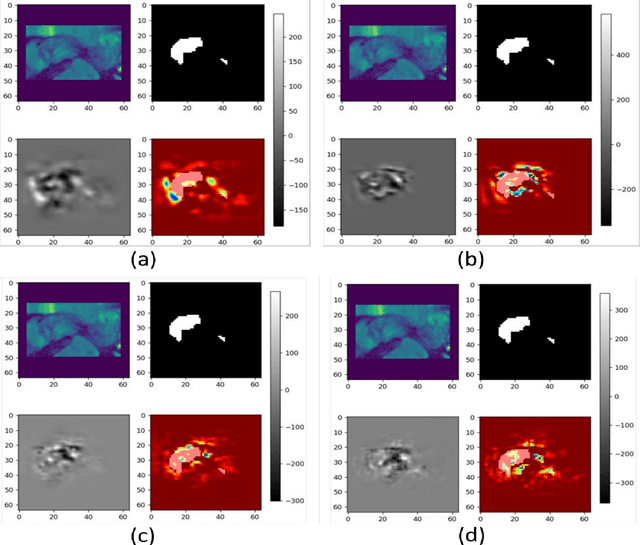
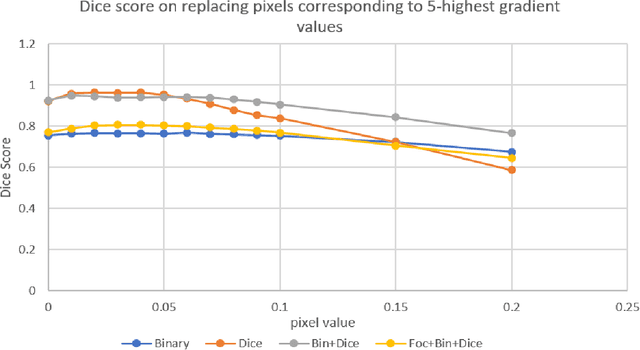
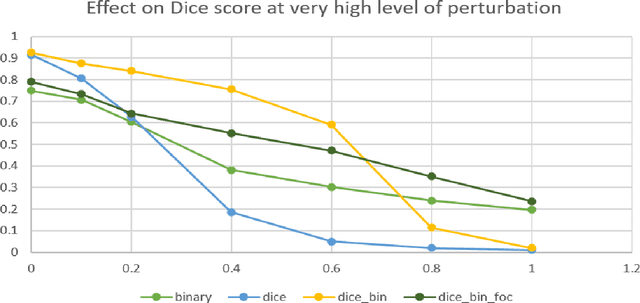
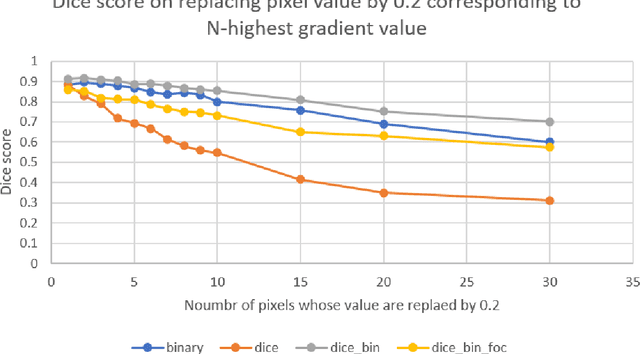
Recent developments in AI have made it ubiquitous, every industry is trying to adopt some form of intelligent processing of their data. Despite so many advances in the field, AIs full capability is yet to be exploited by the industry. Industries that involve some risk factors still remain cautious about the usage of AI due to the lack of trust in such autonomous systems. Present-day AI might be very good in a lot of things but it is very bad in reasoning and this behavior of AI can lead to catastrophic results. Autonomous cars crashing into a person or a drone getting stuck in a tree are a few examples where AI decisions lead to catastrophic results. To develop insight and generate an explanation about the learning capability of AI, we will try to analyze the working of loss functions. For our case, we will use two sets of loss functions, generalized loss functions like Binary cross-entropy or BCE and specialized loss functions like Dice loss or focal loss. Through a series of experiments, we will establish whether combining different loss functions is better than using a single loss function and if yes, then what is the reason behind it. In order to establish the difference between generalized loss and specialized losses, we will train several models using the above-mentioned losses and then compare their robustness on adversarial examples. In particular, we will look at how fast the accuracy of different models decreases when we change the pixels corresponding to the most salient gradients.