 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLidar Light Scattering Augmentation (LISA): Physics-based Simulation of Adverse Weather Conditions for 3D Object Detection
Jul 14, 2021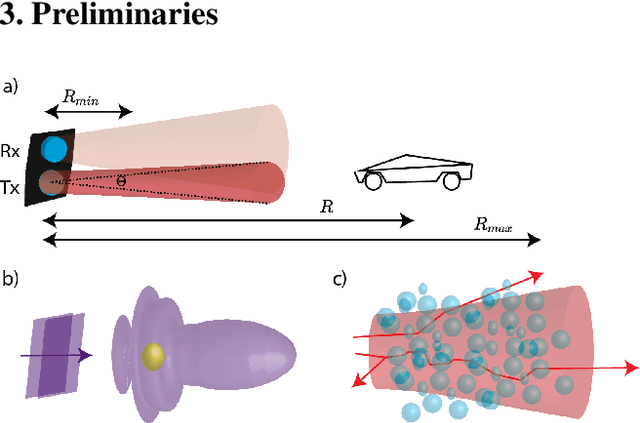
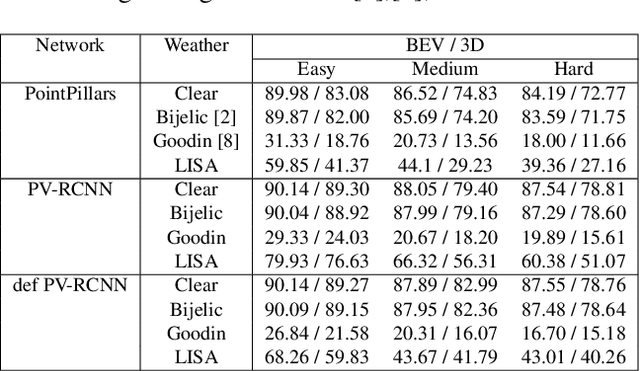
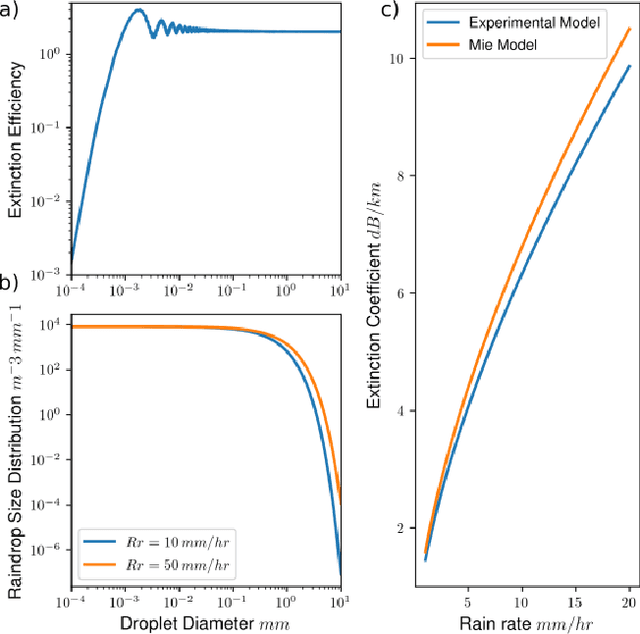
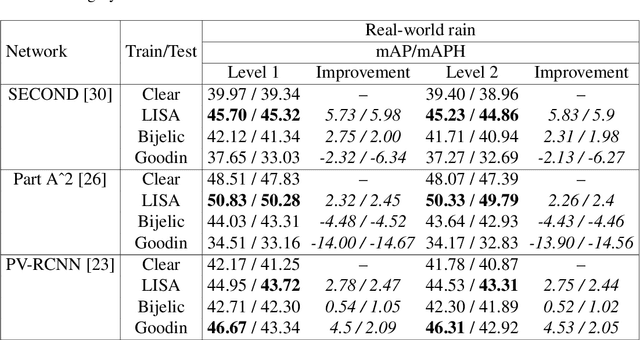
Lidar-based object detectors are critical parts of the 3D perception pipeline in autonomous navigation systems such as self-driving cars. However, they are known to be sensitive to adverse weather conditions such as rain, snow and fog due to reduced signal-to-noise ratio (SNR) and signal-to-background ratio (SBR). As a result, lidar-based object detectors trained on data captured in normal weather tend to perform poorly in such scenarios. However, collecting and labelling sufficient training data in a diverse range of adverse weather conditions is laborious and prohibitively expensive. To address this issue, we propose a physics-based approach to simulate lidar point clouds of scenes in adverse weather conditions. These augmented datasets can then be used to train lidar-based detectors to improve their all-weather reliability. Specifically, we introduce a hybrid Monte-Carlo based approach that treats (i) the effects of large particles by placing them randomly and comparing their back reflected power against the target, and (ii) attenuation effects on average through calculation of scattering efficiencies from the Mie theory and particle size distributions. Retraining networks with this augmented data improves mean average precision evaluated on real world rainy scenes and we observe greater improvement in performance with our model relative to existing models from the literature. Furthermore, we evaluate recent state-of-the-art detectors on the simulated weather conditions and present an in-depth analysis of their performance.
Hyperspectral Pansharpening Based on Improved Deep Image Prior and Residual Reconstruction
Jul 06, 2021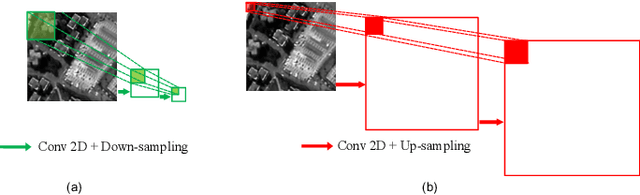


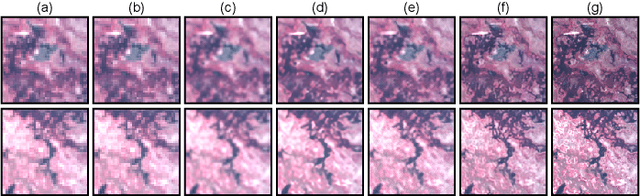
Hyperspectral pansharpening aims to synthesize a low-resolution hyperspectral image (LR-HSI) with a registered panchromatic image (PAN) to generate an enhanced HSI with high spectral and spatial resolution. Recently proposed HS pansharpening methods have obtained remarkable results using deep convolutional networks (ConvNets), which typically consist of three steps: (1) up-sampling the LR-HSI, (2) predicting the residual image via a ConvNet, and (3) obtaining the final fused HSI by adding the outputs from first and second steps. Recent methods have leveraged Deep Image Prior (DIP) to up-sample the LR-HSI due to its excellent ability to preserve both spatial and spectral information, without learning from large data sets. However, we observed that the quality of up-sampled HSIs can be further improved by introducing an additional spatial-domain constraint to the conventional spectral-domain energy function. We define our spatial-domain constraint as the $L_1$ distance between the predicted PAN image and the actual PAN image. To estimate the PAN image of the up-sampled HSI, we also propose a learnable spectral response function (SRF). Moreover, we noticed that the residual image between the up-sampled HSI and the reference HSI mainly consists of edge information and very fine structures. In order to accurately estimate fine information, we propose a novel over-complete network, called HyperKite, which focuses on learning high-level features by constraining the receptive from increasing in the deep layers. We perform experiments on three HSI datasets to demonstrate the superiority of our DIP-HyperKite over the state-of-the-art pansharpening methods. The deployment codes, pre-trained models, and final fusion outputs of our DIP-HyperKite and the methods used for the comparisons will be publicly made available at https://github.com/wgcban/DIP-HyperKite.git.
Over-and-Under Complete Convolutional RNN for MRI Reconstruction
Jun 25, 2021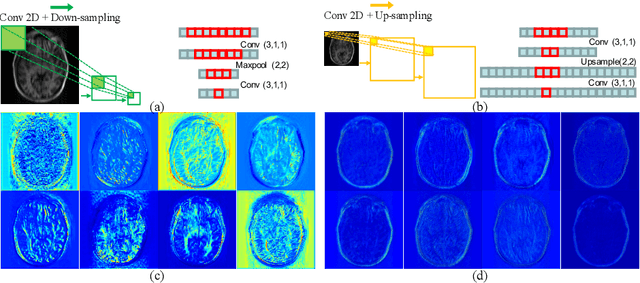
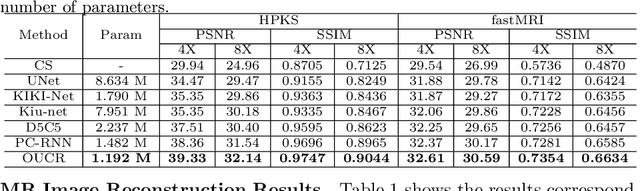
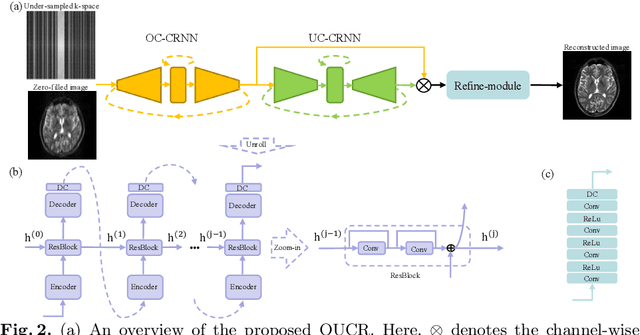
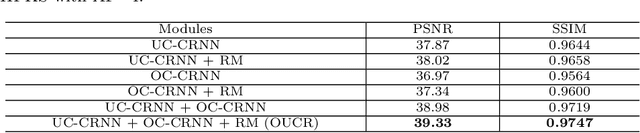
Reconstructing magnetic resonance (MR) images from undersampled data is a challenging problem due to various artifacts introduced by the under-sampling operation. Recent deep learning-based methods for MR image reconstruction usually leverage a generic auto-encoder architecture which captures low-level features at the initial layers and high-level features at the deeper layers. Such networks focus much on global features which may not be optimal to reconstruct the fully-sampled image. In this paper, we propose an Over-and-Under Complete Convolutional Recurrent Neural Network (OUCR), which consists of an overcomplete and an undercomplete Convolutional Recurrent Neural Network(CRNN). The overcomplete branch gives special attention in learning local structures by restraining the receptive field of the network. Combining it with the undercomplete branch leads to a network which focuses more on low-level features without losing out on the global structures. Extensive experiments on two datasets demonstrate that the proposed method achieves significant improvements over the compressed sensing and popular deep learning-based methods with less number of trainable parameters.
Unsupervised Domain Adaption of Object Detectors: A Survey
May 27, 2021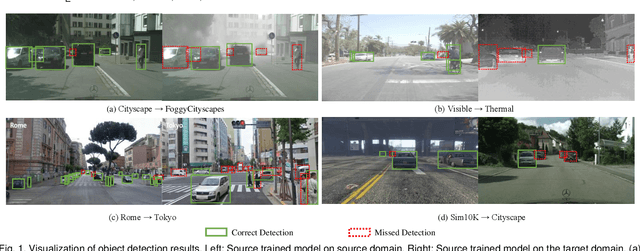
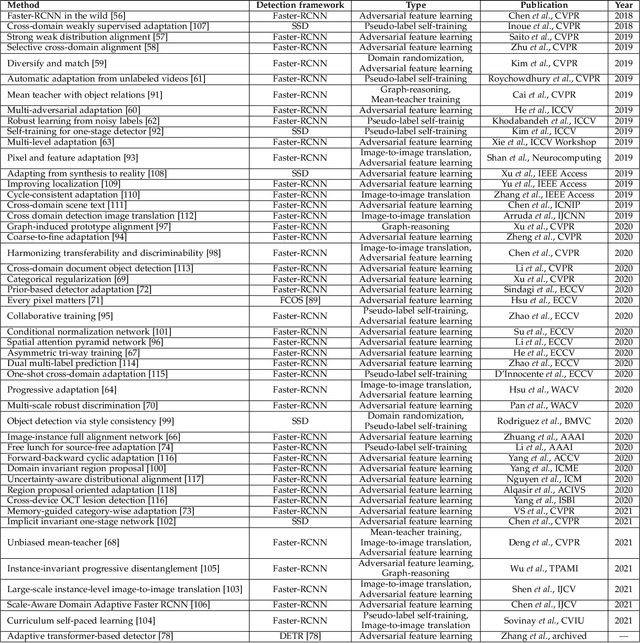
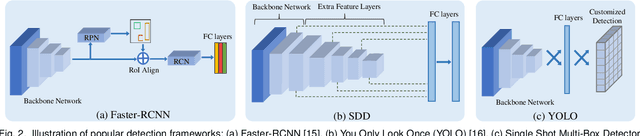
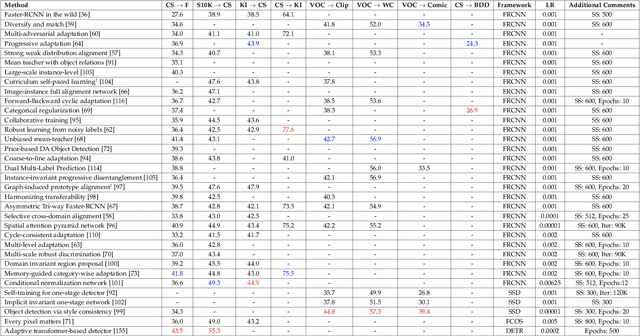
Recent advances in deep learning have led to the development of accurate and efficient models for various computer vision applications such as object classification, semantic segmentation, and object detection. However, learning highly accurate models relies on the availability of datasets with a large number of annotated images. Due to this, model performance drops drastically when evaluated on label-scarce datasets having visually distinct images. This issue is commonly referred to as covariate shift or dataset bias. Domain adaptation attempts to address this problem by leveraging domain shift characteristics from labeled data in a related domain when learning a classifier for label-scarce target dataset. There are a plethora of works to adapt object classification and semantic segmentation models to label-scarce target dataset through unsupervised domain adaptation. Considering that object detection is a fundamental task in computer vision, many recent works have recently focused on addressing the domain adaptation issue for object detection as well. In this paper, we provide a brief introduction to the domain adaptation problem for object detection and present an overview of various methods proposed to date for addressing this problem. Furthermore, we highlight strategies proposed for this problem and the associated shortcomings. Subsequently, we identify multiple aspects of the unsupervised domain adaptive detection problem that are most promising for future research in the area. We believe that this survey shall be valuable to the pattern recognition experts working in the fields of computer vision, biometrics, medical imaging, and autonomous navigation by introducing them to the problem, getting them familiar with the current status of the progress, and providing them with promising direction for future research.
Federated Learning-based Active Authentication on Mobile Devices
Apr 14, 2021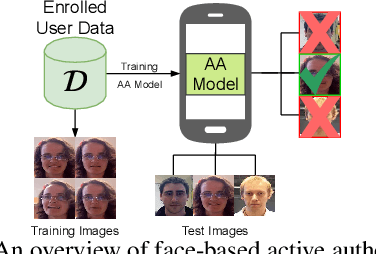
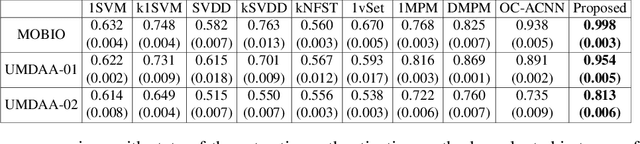
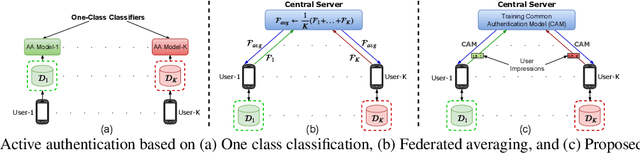
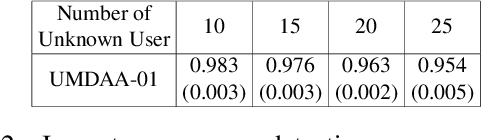
User active authentication on mobile devices aims to learn a model that can correctly recognize the enrolled user based on device sensor information. Due to lack of negative class data, it is often modeled as a one-class classification problem. In practice, mobile devices are connected to a central server, e.g, all android-based devices are connected to Google server through internet. This device-server structure can be exploited by recently proposed Federated Learning (FL) and Split Learning (SL) frameworks to perform collaborative learning over the data distributed among multiple devices. Using FL/SL frameworks, we can alleviate the lack of negative data problem by training a user authentication model over multiple user data distributed across devices. To this end, we propose a novel user active authentication training, termed as Federated Active Authentication (FAA), that utilizes the principles of FL/SL. We first show that existing FL/SL methods are suboptimal for FAA as they rely on the data to be distributed homogeneously (i.e. IID) across devices, which is not true in the case of FAA. Subsequently, we propose a novel method that is able to tackle heterogeneous/non-IID distribution of data in FAA. Specifically, we first extract feature statistics such as mean and variance corresponding to data from each user which are later combined in a central server to learn a multi-class classifier and sent back to the individual devices. We conduct extensive experiments using three active authentication benchmark datasets (MOBIO, UMDAA-01, UMDAA-02) and show that such approach performs better than state-of-the-art one-class based FAA methods and is also able to outperform traditional FL/SL methods.
Federated Generalized Face Presentation Attack Detection
Apr 14, 2021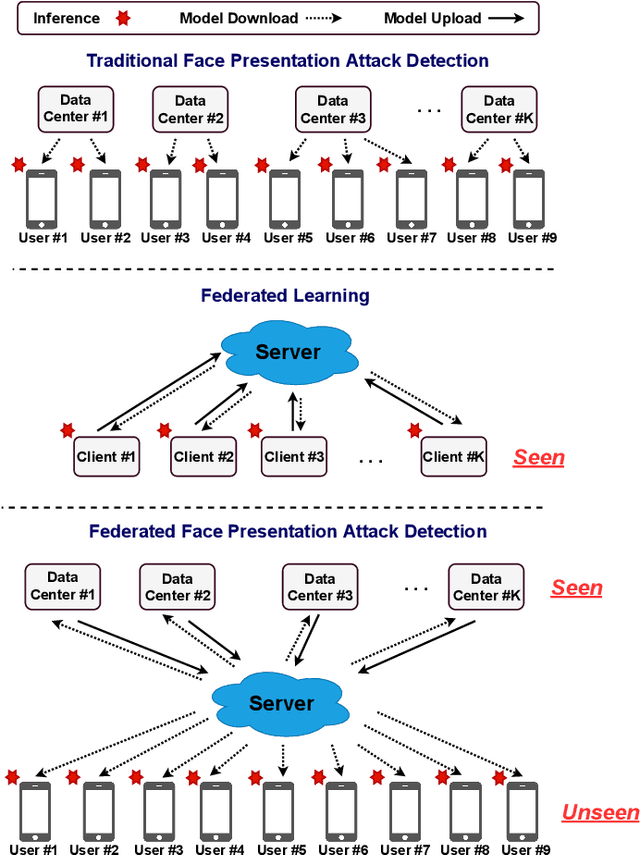
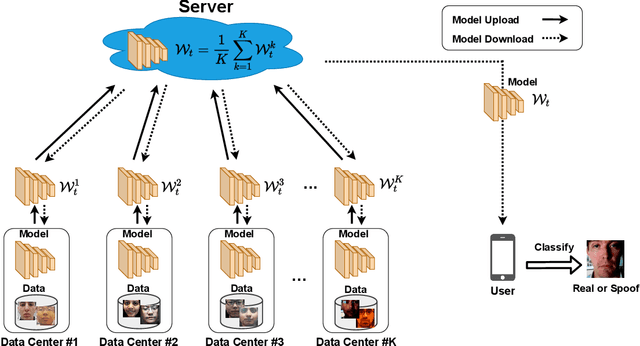
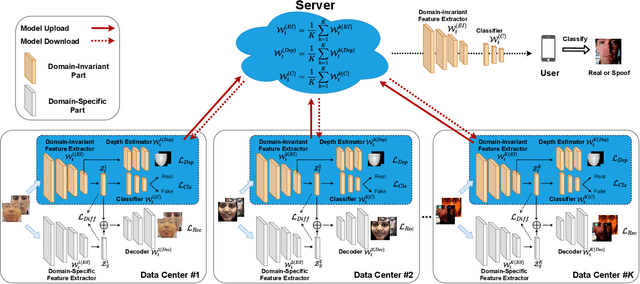

Face presentation attack detection plays a critical role in the modern face recognition pipeline. A face presentation attack detection model with good generalization can be obtained when it is trained with face images from different input distributions and different types of spoof attacks. In reality, training data (both real face images and spoof images) are not directly shared between data owners due to legal and privacy issues. In this paper, with the motivation of circumventing this challenge, we propose a Federated Face Presentation Attack Detection (FedPAD) framework that simultaneously takes advantage of rich fPAD information available at different data owners while preserving data privacy. In the proposed framework, each data center locally trains its own fPAD model. A server learns a global fPAD model by iteratively aggregating model updates from all data centers without accessing private data in each of them. To equip the aggregated fPAD model in the server with better generalization ability to unseen attacks from users, following the basic idea of FedPAD, we further propose a Federated Generalized Face Presentation Attack Detection (FedGPAD) framework. A federated domain disentanglement strategy is introduced in FedGPAD, which treats each data center as one domain and decomposes the fPAD model into domain-invariant and domain-specific parts in each data center. Two parts disentangle the domain-invariant and domain-specific features from images in each local data center, respectively. A server learns a global fPAD model by only aggregating domain-invariant parts of the fPAD models from data centers and thus a more generalized fPAD model can be aggregated in server. We introduce the experimental setting to evaluate the proposed FedPAD and FedGPAD frameworks and carry out extensive experiments to provide various insights about federated learning for fPAD.
Simultaneous Face Hallucination and Translation for Thermal to Visible Face Verification using Axial-GAN
Apr 13, 2021
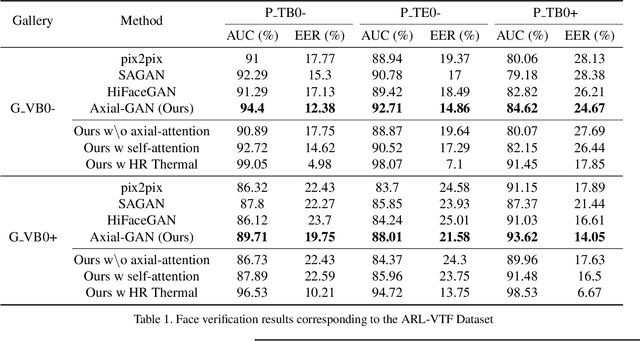
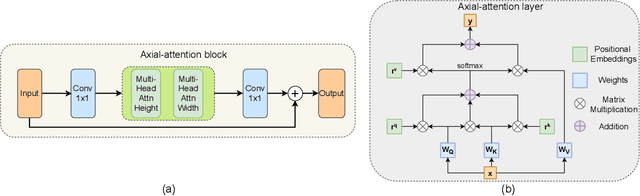
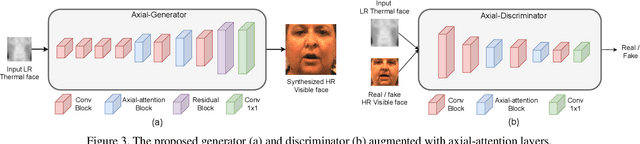
Existing thermal-to-visible face verification approaches expect the thermal and visible face images to be of similar resolution. This is unlikely in real-world long-range surveillance systems, since humans are distant from the cameras. To address this issue, we introduce the task of thermal-to-visible face verification from low-resolution thermal images. Furthermore, we propose Axial-Generative Adversarial Network (Axial-GAN) to synthesize high-resolution visible images for matching. In the proposed approach we augment the GAN framework with axial-attention layers which leverage the recent advances in transformers for modelling long-range dependencies. We demonstrate the effectiveness of the proposed method by evaluating on two different thermal-visible face datasets. When compared to related state-of-the-art works, our results show significant improvements in both image quality and face verification performance, and are also much more efficient.
Multimodal Face Synthesis from Visual Attributes
Apr 09, 2021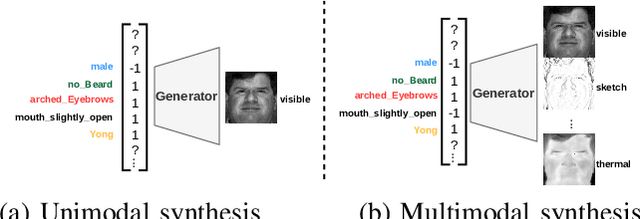



Synthesis of face images from visual attributes is an important problem in computer vision and biometrics due to its applications in law enforcement and entertainment. Recent advances in deep generative networks have made it possible to synthesize high-quality face images from visual attributes. However, existing methods are specifically designed for generating unimodal images (i.e visible faces) from attributes. In this paper, we propose a novel generative adversarial network that simultaneously synthesizes identity preserving multimodal face images (i.e. visible, sketch, thermal, etc.) from visual attributes without requiring paired data in different domains for training the network. We introduce a novel generator with multimodal stretch-out modules to simultaneously synthesize multimodal face images. Additionally, multimodal stretch-in modules are introduced in the discriminator which discriminates between real and fake images. Extensive experiments and comparisons with several state-of-the-art methods are performed to verify the effectiveness of the proposed attribute-based multimodal synthesis method.
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
Apr 03, 2021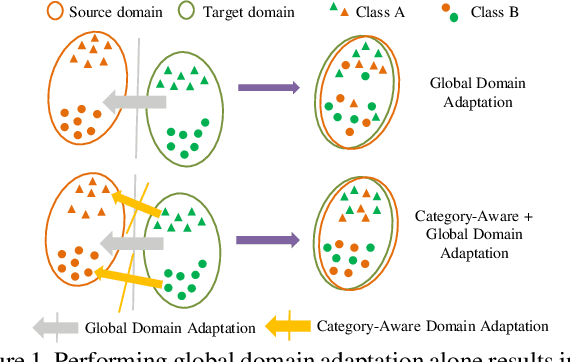
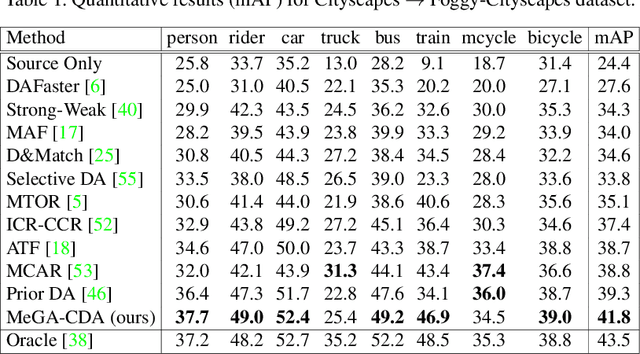
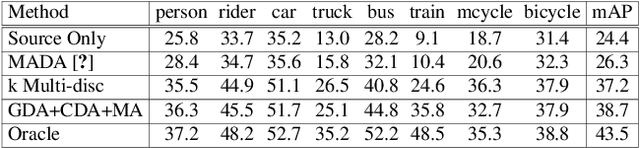
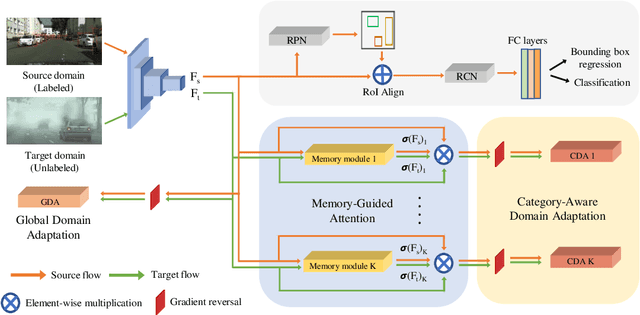
Existing approaches for unsupervised domain adaptive object detection perform feature alignment via adversarial training. While these methods achieve reasonable improvements in performance, they typically perform category-agnostic domain alignment, thereby resulting in negative transfer of features. To overcome this issue, in this work, we attempt to incorporate category information into the domain adaptation process by proposing Memory Guided Attention for Category-Aware Domain Adaptation (MeGA-CDA). The proposed method consists of employing category-wise discriminators to ensure category-aware feature alignment for learning domain-invariant discriminative features. However, since the category information is not available for the target samples, we propose to generate memory-guided category-specific attention maps which are then used to route the features appropriately to the corresponding category discriminator. The proposed method is evaluated on several benchmark datasets and is shown to outperform existing approaches.
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 10, 2021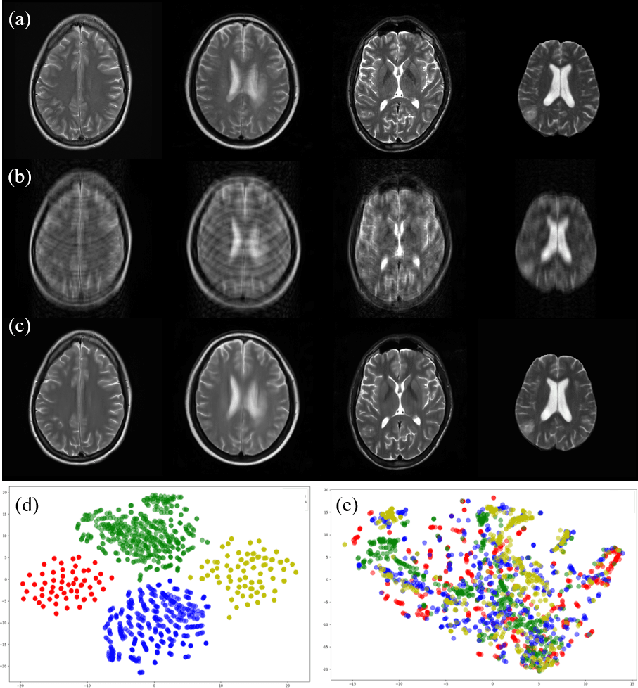
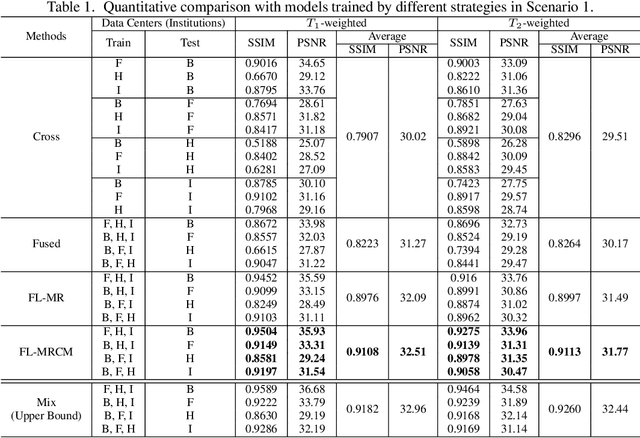
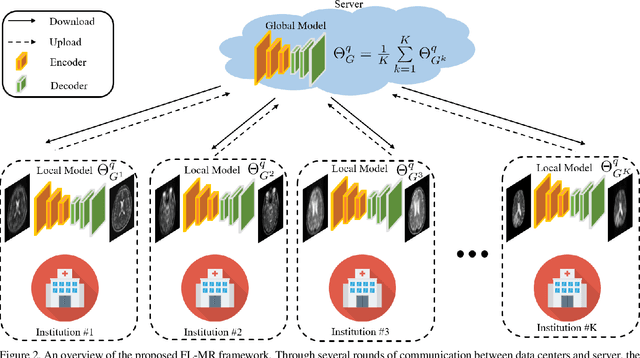
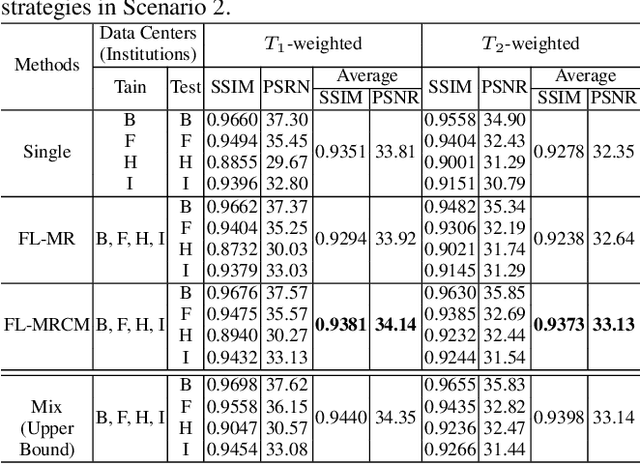
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.