 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRice Grain Size Measurement using Image Processing
Mar 05, 2025The rice grain quality can be determined from its size and chalkiness. The traditional approach to measure the rice grain size involves manual inspection, which is inefficient and leads to inconsistent results. To address this issue, an image processing based approach is proposed and developed in this research. The approach takes image of rice grains as input and outputs the number of rice grains and size of each rice grain. The different steps, such as extraction of region of interest, segmentation of rice grains, and sub-contours removal, involved in the proposed approach are discussed. The approach was tested on rice grain images captured from different height using mobile phone camera. The obtained results show that the proposed approach successfully detected 95\% of the rice grains and achieved 90\% accuracy for length and width measurement.
Find Matching Faces Based On Face Parameters
Mar 05, 2025This paper presents an innovative approach that enables the user to find matching faces based on the user-selected face parameters. Through gradio-based user interface, the users can interactively select the face parameters they want in their desired partner. These user-selected face parameters are transformed into a text prompt which is used by the Text-To-Image generation model to generate a realistic face image. Further, the generated image along with the images downloaded from the Jeevansathi.com are processed through face detection and feature extraction model, which results in high dimensional vector embedding of 512 dimensions. The vector embeddings generated from the downloaded images are stored into vector database. Now, the similarity search is carried out between the vector embedding of generated image and the stored vector embeddings. As a result, it displays the top five similar faces based on the user-selected face parameters. This contribution holds a significant potential to turn into a high-quality personalized face matching tool.
Taxonomic survey of Hindi Language NLP systems
Jan 30, 2021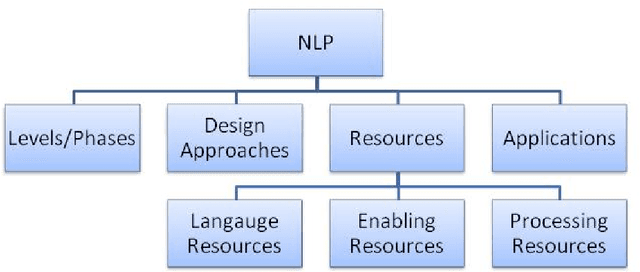
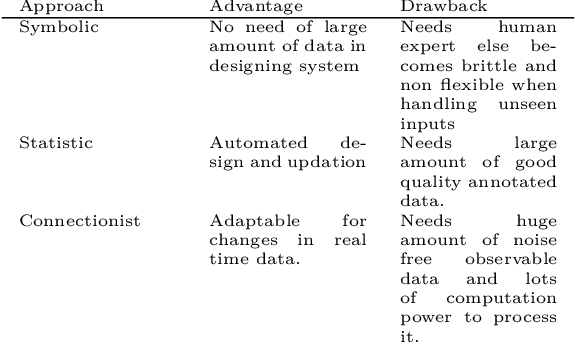
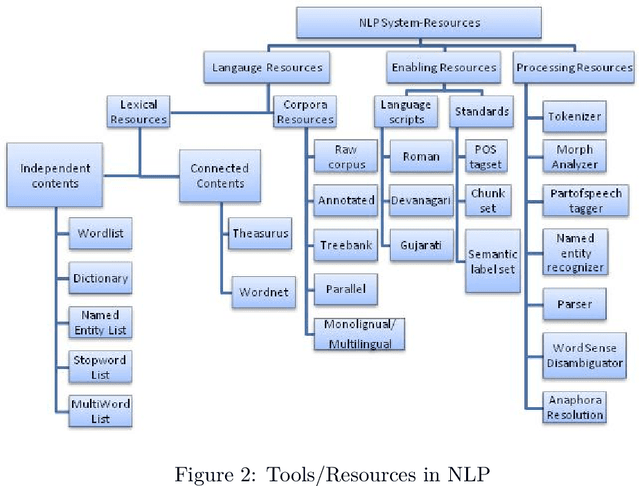
Natural Language processing (NLP) represents the task of automatic handling of natural human language by machines.There is large spectrum of possible applications of NLP which help in automating tasks like translating text from one language to other, retrieving and summarizing data from very huge repositories, spam email filtering, identifying fake news in digital media, find sentiment and feedback of people, find political opinions and views of people on various government policies, provide effective medical assistance based on past history records of patient etc. Hindi is the official language of India with nearly 691 million users in India and 366 million in rest of world. At present, a number of government and private sector projects and researchers in India and abroad, are working towards developing NLP applications and resources for Indian languages. This survey gives a report of the resources and applications available for Hindi language NLP.
Developing Postfix-GP Framework for Symbolic Regression Problems
Jul 07, 2015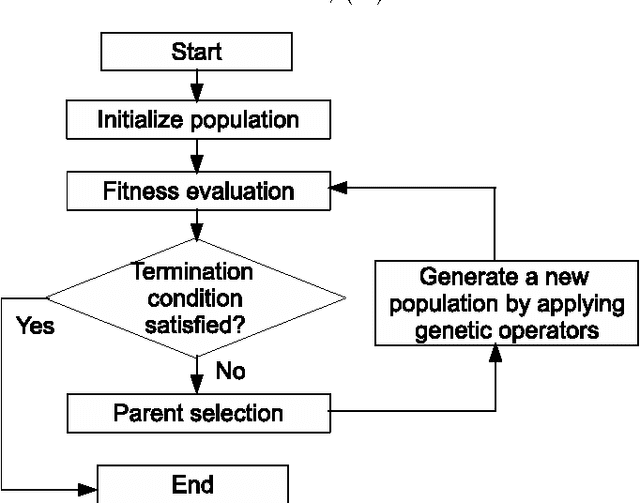
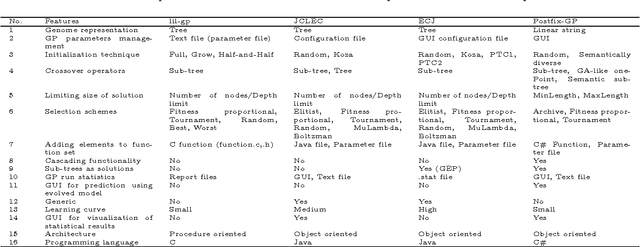
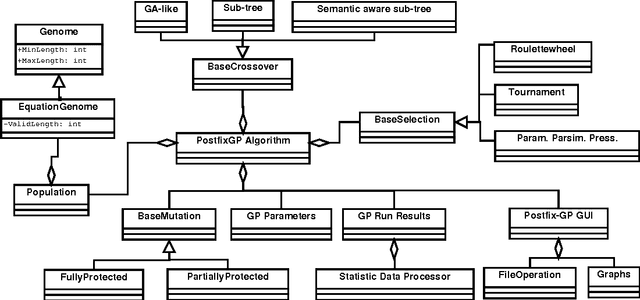
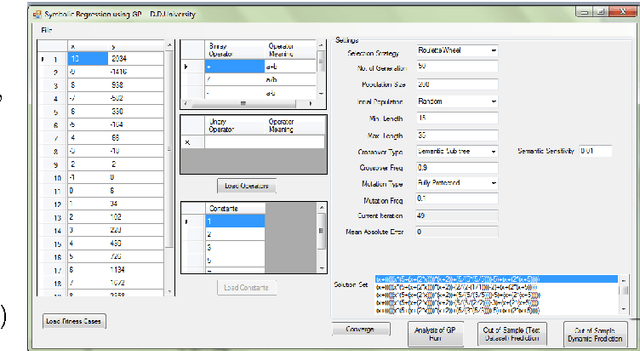
This paper describes Postfix-GP system, postfix notation based Genetic Programming (GP), for solving symbolic regression problems. It presents an object-oriented architecture of Postfix-GP framework. It assists the user in understanding of the implementation details of various components of Postfix-GP. Postfix-GP provides graphical user interface which allows user to configure the experiment, to visualize evolved solutions, to analyze GP run, and to perform out-of-sample predictions. The use of Postfix-GP is demonstrated by solving the benchmark symbolic regression problem. Finally, features of Postfix-GP framework are compared with that of other GP systems.
Improving Generalization Ability of Genetic Programming: Comparative Study
Apr 13, 2013
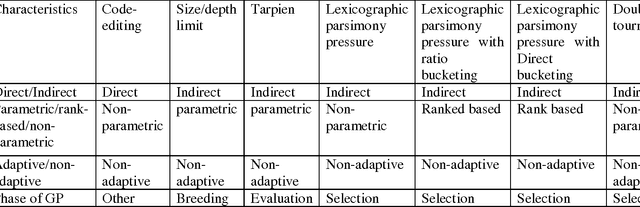
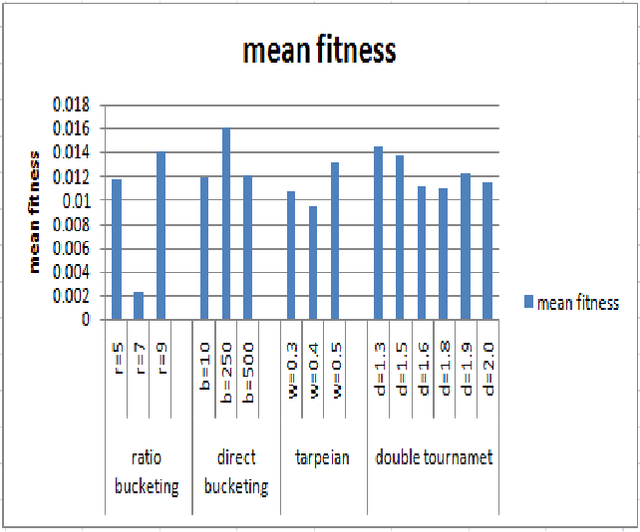
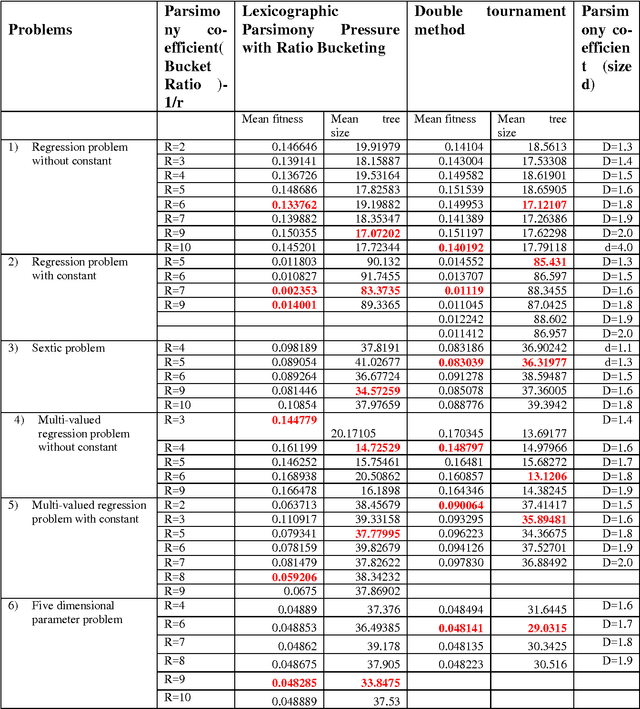
In the field of empirical modeling using Genetic Programming (GP), it is important to evolve solution with good generalization ability. Generalization ability of GP solutions get affected by two important issues: bloat and over-fitting. Bloat is uncontrolled growth of code without any gain in fitness and important issue in GP. We surveyed and classified existing literature related to different techniques used by GP research community to deal with the issue of bloat. Moreover, the classifications of different bloat control approaches and measures for bloat are discussed. Next, we tested four bloat control methods: Tarpeian, double tournament, lexicographic parsimony pressure with direct bucketing and ratio bucketing on six different problems and identified where each bloat control method performs well on per problem basis. Based on the analysis of each method, we combined two methods: double tournament (selection method) and Tarpeian method (works before evaluation) to avoid bloated solutions and compared with the results obtained from individual performance of double tournament method. It was found that the results were improved with this combination of two methods.
Modified Soft Brood Crossover in Genetic Programming
Apr 12, 2013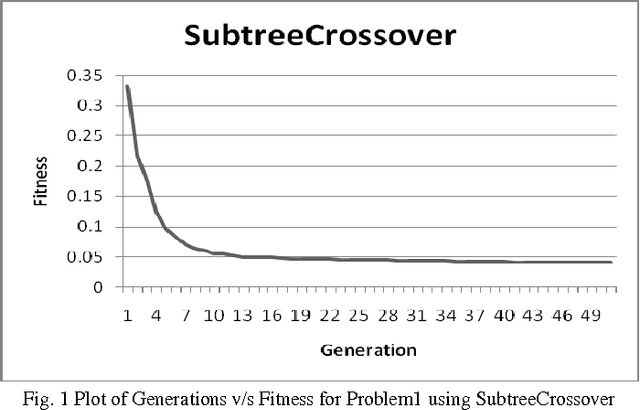
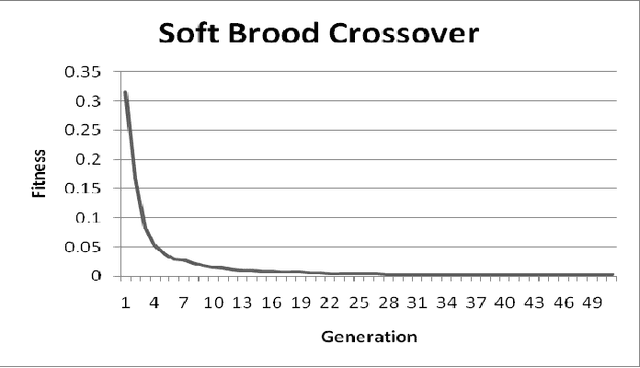
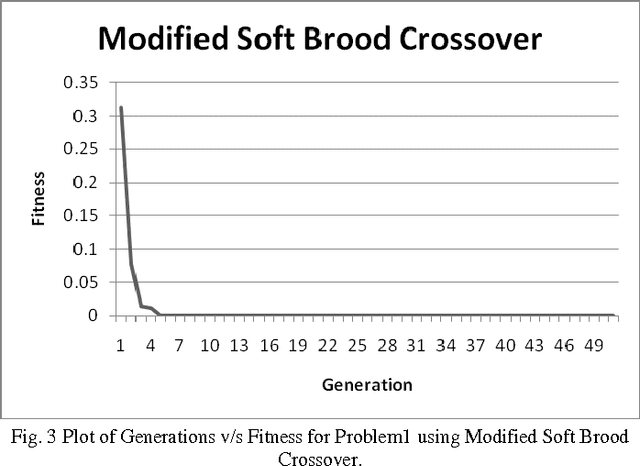
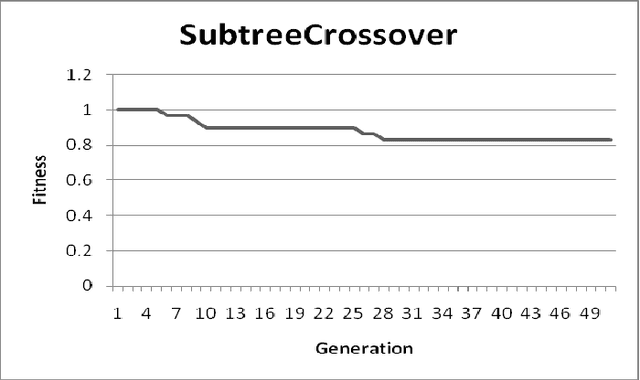
Premature convergence is one of the important issues while using Genetic Programming for data modeling. It can be avoided by improving population diversity. Intelligent genetic operators can help to improve the population diversity. Crossover is an important operator in Genetic Programming. So, we have analyzed number of intelligent crossover operators and proposed an algorithm with the modification of soft brood crossover operator. It will help to improve the population diversity and reduce the premature convergence. We have performed experiments on three different symbolic regression problems. Then we made the performance comparison of our proposed crossover (Modified Soft Brood Crossover) with the existing soft brood crossover and subtree crossover operators.
A Survey on Techniques of Improving Generalization Ability of Genetic Programming Solutions
Nov 06, 2012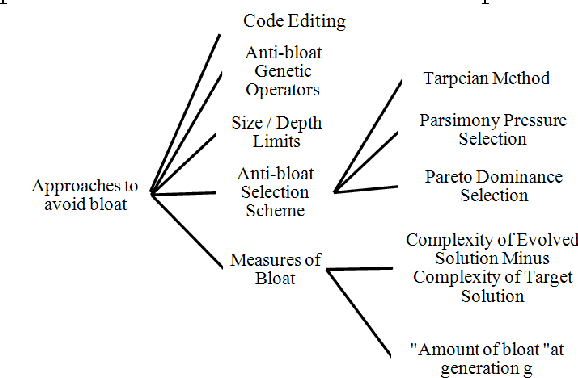
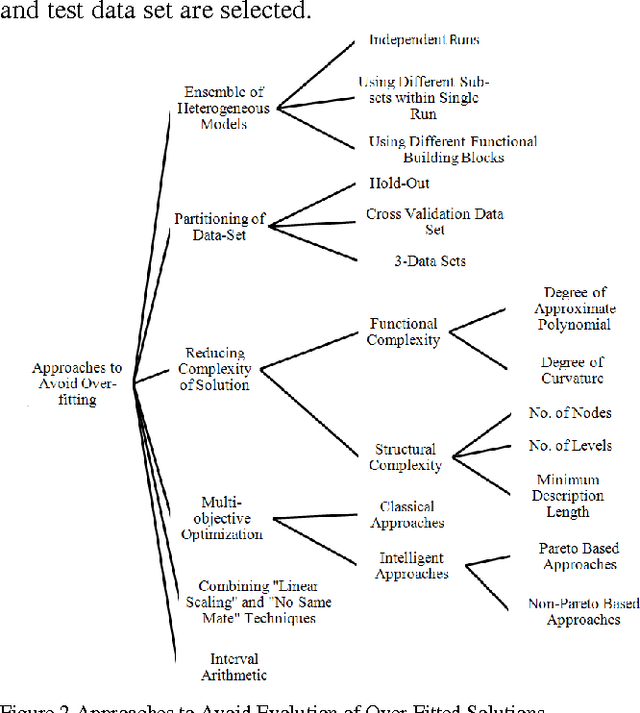
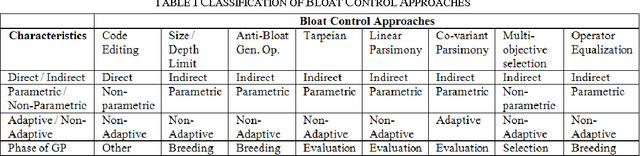
In the field of empirical modeling using Genetic Programming (GP), it is important to evolve solution with good generalization ability. Generalization ability of GP solutions get affected by two important issues: bloat and over-fitting. We surveyed and classified existing literature related to different techniques used by GP research community to deal with these issues. We also point out limitation of these techniques, if any. Moreover, the classification of different bloat control approaches and measures for bloat and over-fitting are also discussed. We believe that this work will be useful to GP practitioners in following ways: (i) to better understand concepts of generalization in GP (ii) comparing existing bloat and over-fitting control techniques and (iii) selecting appropriate approach to improve generalization ability of GP evolved solutions.