 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy of the influence of a biased database on the prediction of standard algorithms for selecting the best candidate for an interview
May 05, 2025Artificial intelligence is used at various stages of the recruitment process to automatically select the best candidate for a position, with companies guaranteeing unbiased recruitment. However, the algorithms used are either trained by humans or are based on learning from past experiences that were biased. In this article, we propose to generate data mimicking external (discrimination) and internal biases (self-censorship) in order to train five classic algorithms and to study the extent to which they do or do not find the best candidates according to objective criteria. In addition, we study the influence of the anonymisation of files on the quality of predictions.
Mixture of segmentation for heterogeneous functional data
Mar 19, 2023



In this paper we consider functional data with heterogeneity in time and in population. We propose a mixture model with segmentation of time to represent this heterogeneity while keeping the functional structure. Maximum likelihood estimator is considered, proved to be identifiable and consistent. In practice, an EM algorithm is used, combined with dynamic programming for the maximization step, to approximate the maximum likelihood estimator. The method is illustrated on a simulated dataset, and used on a real dataset of electricity consumption.
Co-clustering through Optimal Transport
May 19, 2017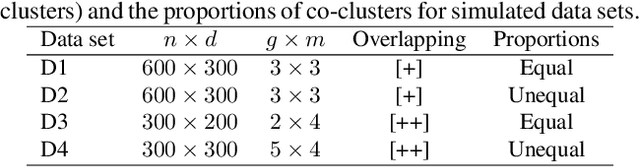
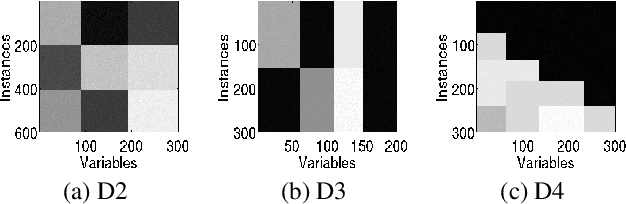

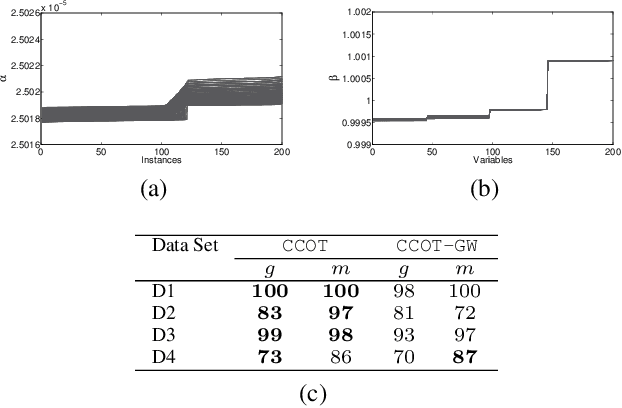
In this paper, we present a novel method for co-clustering, an unsupervised learning approach that aims at discovering homogeneous groups of data instances and features by grouping them simultaneously. The proposed method uses the entropy regularized optimal transport between empirical measures defined on data instances and features in order to obtain an estimated joint probability density function represented by the optimal coupling matrix. This matrix is further factorized to obtain the induced row and columns partitions using multiscale representations approach. To justify our method theoretically, we show how the solution of the regularized optimal transport can be seen from the variational inference perspective thus motivating its use for co-clustering. The algorithm derived for the proposed method and its kernelized version based on the notion of Gromov-Wasserstein distance are fast, accurate and can determine automatically the number of both row and column clusters. These features are vividly demonstrated through extensive experimental evaluations.