 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable or Deceptive? Investigating Gated Features for Smooth Visual Explanations in CNNs
Apr 30, 2024Deep learning models have achieved remarkable success across diverse domains. However, the intricate nature of these models often impedes a clear understanding of their decision-making processes. This is where Explainable AI (XAI) becomes indispensable, offering intuitive explanations for model decisions. In this work, we propose a simple yet highly effective approach, ScoreCAM++, which introduces modifications to enhance the promising ScoreCAM method for visual explainability. Our proposed approach involves altering the normalization function within the activation layer utilized in ScoreCAM, resulting in significantly improved results compared to previous efforts. Additionally, we apply an activation function to the upsampled activation layers to enhance interpretability. This improvement is achieved by selectively gating lower-priority values within the activation layer. Through extensive experiments and qualitative comparisons, we demonstrate that ScoreCAM++ consistently achieves notably superior performance and fairness in interpreting the decision-making process compared to both ScoreCAM and previous methods.
Q-matrix Unaware Double JPEG Detection using DCT-Domain Deep BiLSTM Network
Apr 10, 2021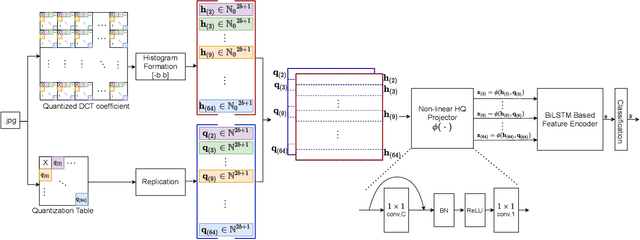
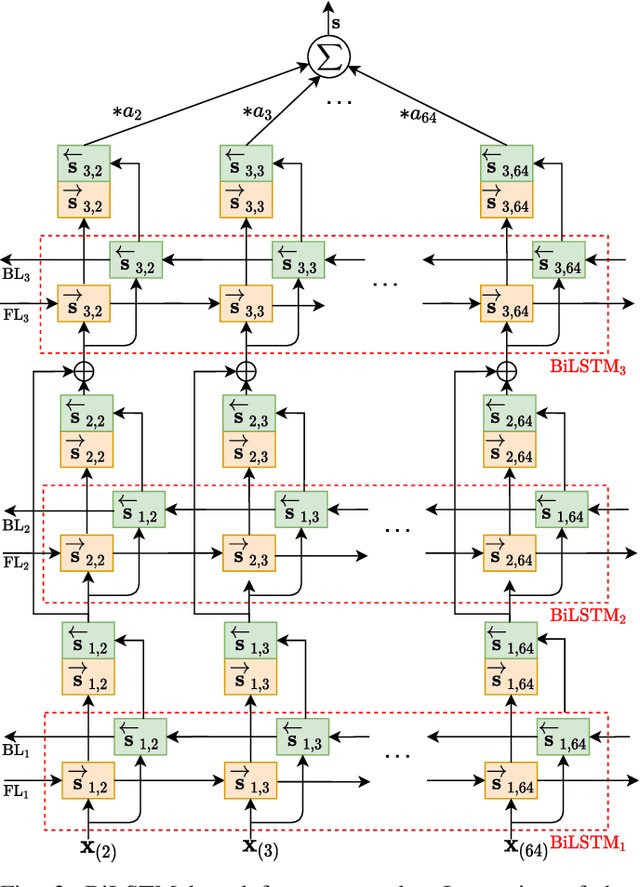

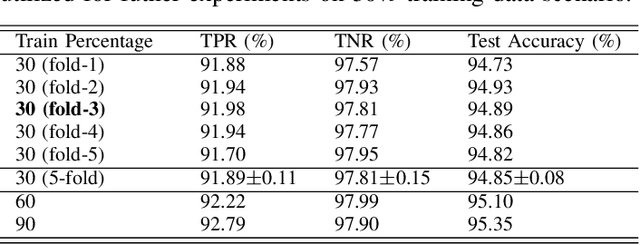
The double JPEG compression detection has received much attention in recent years due to its applicability as a forensic tool for the most widely used JPEG file format. Existing state-of-the-art CNN-based methods either use histograms of all the frequencies or rely on heuristics to select histograms of specific low frequencies to classify single and double compressed images. However, even amidst lower frequencies of double compressed images/patches, histograms of all the frequencies do not have distinguishable features to separate them from single compressed images. This paper directly extracts the quantized DCT coefficients from the JPEG images without decompressing them in the pixel domain, obtains all AC frequencies' histograms, uses a module based on $1\times 1$ depth-wise convolutions to learn the inherent relation between each histogram and corresponding q-factor, and utilizes a tailor-made BiLSTM network for selectively encoding these feature vector sequences. The proposed system outperforms several baseline methods on a relatively large and diverse publicly available dataset of single and double compressed patches. Another essential aspect of any single vs. double JPEG compression detection system is handling the scenario where test patches are compressed with entirely different quantization matrices (Q-matrices) than those used while training; different camera manufacturers and image processing software generally utilize their customized quantization matrices. A set of extensive experiments shows that the proposed system trained on a single dataset generalizes well on other datasets compressed with completely unseen quantization matrices and outperforms the state-of-the-art methods in both seen and unseen quantization matrices scenarios.
Automated Crater Detection from Co-registered Optical Images, Elevation Maps and Slope Maps using Deep Learning
Dec 30, 2020Impact craters are formed as a result of continuous impacts on the surface of planetary bodies. This paper proposes a novel way of simultaneously utilizing optical images, digital elevation maps (DEMs), and slope maps for automatic crater detection on the lunar surface. Mask R-CNN, tuned for the crater detection task, is utilized in this paper. Two catalogs, namely, Head-LROC and Robbins, are used for the performance evaluation. Exhaustive analysis of the detection results on the lunar surface has been performed with respect to both Head-LROC and Robbins catalog. With the Head-LROC catalog, which has relatively strict crater markings and larger possibility of missing craters, recall value of 94.28\% has been obtained as compared to 88.03\% for the baseline method. However, with respect to a manually marked exhaustive crater catalog based on relatively liberal marking, significant precision and recall values are obtained for different crater size ranges. The generalization capability of the proposed method in terms of crater detection on a different terrain with different input data type is also evaluated. We show that the proposed model trained on the lunar surface with optical images, DEMs and corresponding slope maps can be used to detect craters on the Martian surface even with entirely different input data type, such as thermal IR images from the Martian surface.
A Generative Framework for Zero-Shot Learning with Adversarial Domain Adaptation
Jun 07, 2019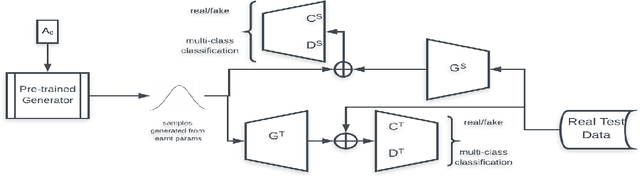
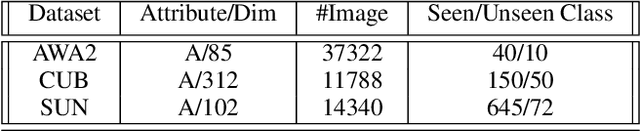
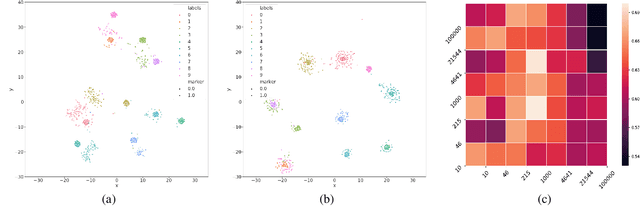
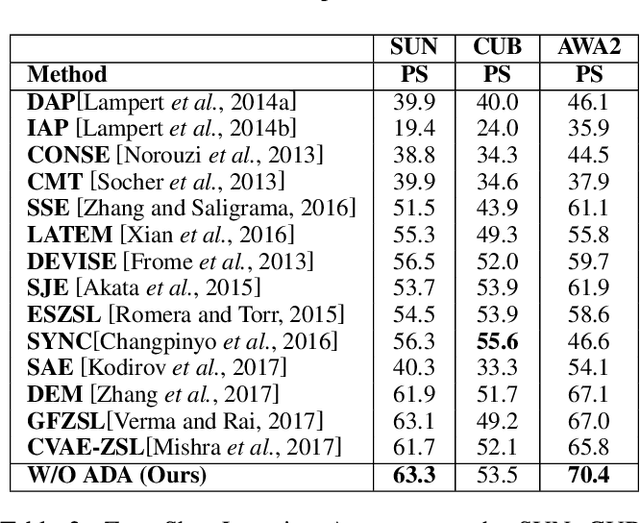
In this paper, we present a domain adaptation based generative framework for Zero-Shot Learning. We explicitly target the problem of domain shift between the seen and unseen class distribution in Zero-Shot Learning (ZSL) and seek to minimize it by developing a generative model and training it via adversarial domain adaptation. Our approach is based on end-to-end learning of the class distributions of seen classes and unseen classes. To enable the model to learn the class distributions of unseen classes, we parameterize these class distributions in terms of the class attribute information (which is available for both seen and unseen classes). This provides a very simple way to learn the class distribution of any unseen class, given only its class attribute information, and no labeled training data. Training this model with adversarial domain adaptation provides robustness against the distribution mismatch between the data from seen and unseen classes. Through a comprehensive set of experiments, we show that our model yields superior accuracies as compared to various state-of-the-art ZSL models, on a variety of benchmark datasets.