 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Baseline Neural Machine Translation System for Indian Languages
Jul 29, 2019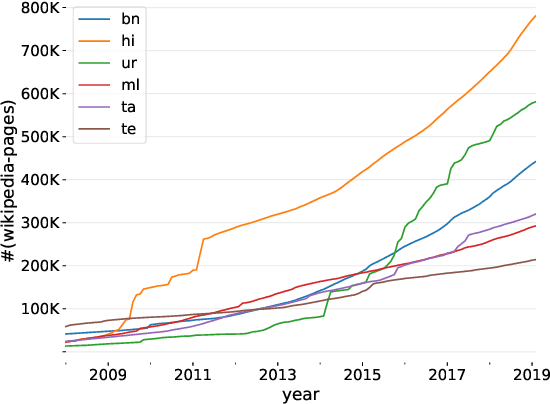
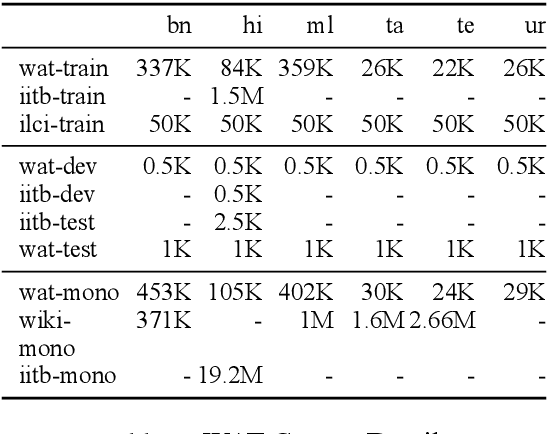
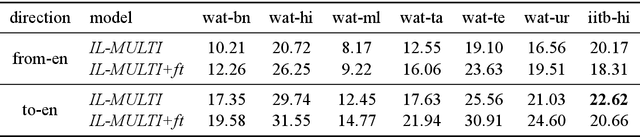

We present a simple, yet effective, Neural Machine Translation system for Indian languages. We demonstrate the feasibility for multiple language pairs, and establish a strong baseline for further research.
InfoRL: Interpretable Reinforcement Learning using Information Maximization
May 24, 2019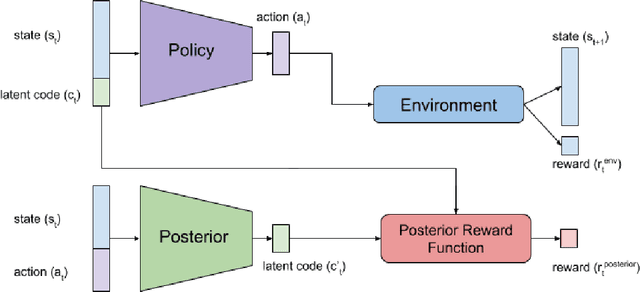

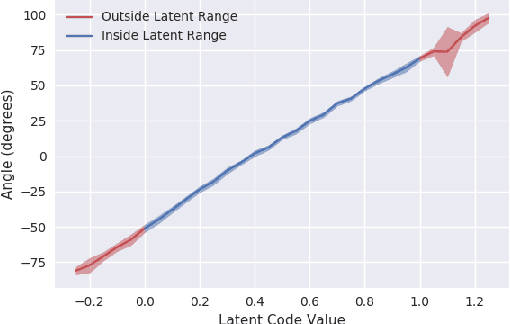
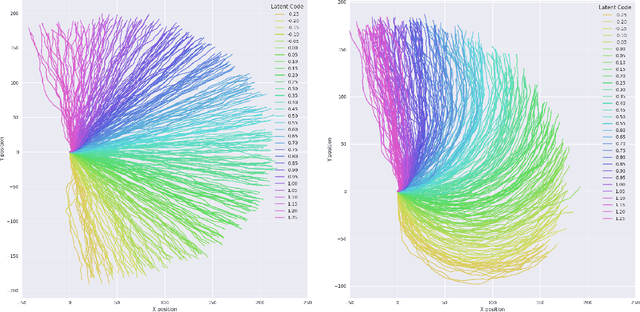
Recent advances in reinforcement learning have proved that given an environment we can learn to perform a task in that environment if we have access to some form of a reward function (dense, sparse or derived from IRL). But most of the algorithms focus on learning a single best policy to perform a given set of tasks. In this paper, we focus on an algorithm that learns to not just perform a task but different ways to perform the same task. As we know when the environment is complex enough there always exists multiple ways to perform a task. We show that using the concept of information maximization it is possible to learn latent codes for discovering multiple ways to perform any given task in an environment.
Play and Prune: Adaptive Filter Pruning for Deep Model Compression
May 11, 2019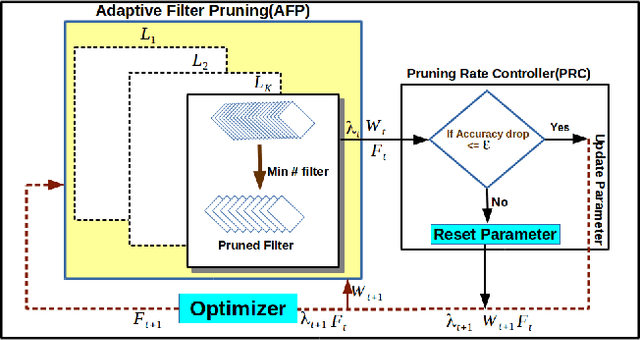
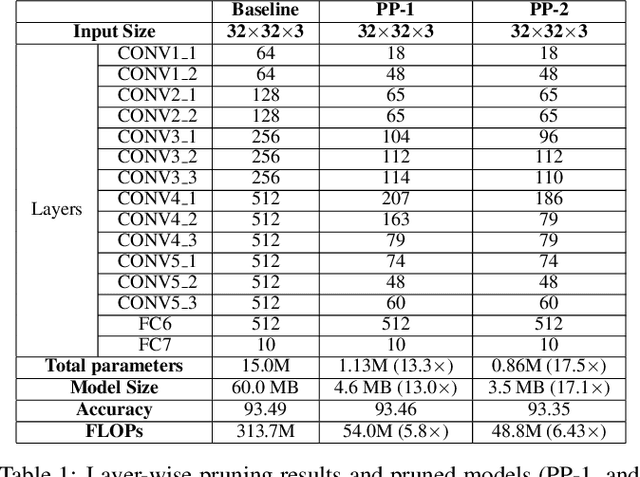
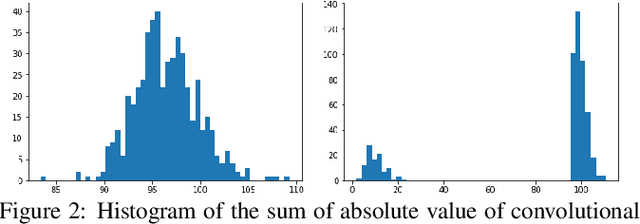
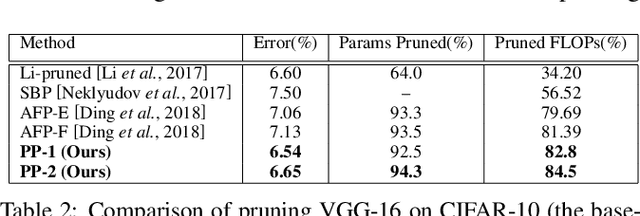
While convolutional neural networks (CNN) have achieved impressive performance on various classification/recognition tasks, they typically consist of a massive number of parameters. This results in significant memory requirement as well as computational overheads. Consequently, there is a growing need for filter-level pruning approaches for compressing CNN based models that not only reduce the total number of parameters but reduce the overall computation as well. We present a new min-max framework for filter-level pruning of CNNs. Our framework, called Play and Prune (PP), jointly prunes and fine-tunes CNN model parameters, with an adaptive pruning rate, while maintaining the model's predictive performance. Our framework consists of two modules: (1) An adaptive filter pruning (AFP) module, which minimizes the number of filters in the model; and (2) A pruning rate controller (PRC) module, which maximizes the accuracy during pruning. Moreover, unlike most previous approaches, our approach allows directly specifying the desired error tolerance instead of pruning level. Our compressed models can be deployed at run-time, without requiring any special libraries or hardware. Our approach reduces the number of parameters of VGG-16 by an impressive factor of 17.5X, and number of FLOPS by 6.43X, with no loss of accuracy, significantly outperforming other state-of-the-art filter pruning methods.
Unsupervised Synthesis of Anomalies in Videos: Transforming the Normal
Apr 14, 2019
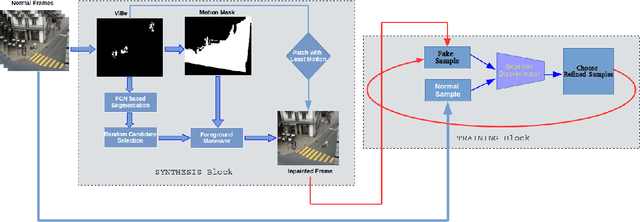


Abnormal activity recognition requires detection of occurrence of anomalous events that suffer from a severe imbalance in data. In a video, normal is used to describe activities that conform to usual events while the irregular events which do not conform to the normal are referred to as abnormal. It is far more common to observe normal data than to obtain abnormal data in visual surveillance. In this paper, we propose an approach where we can obtain abnormal data by transforming normal data. This is a challenging task that is solved through a multi-stage pipeline approach. We utilize a number of techniques from unsupervised segmentation in order to synthesize new samples of data that are transformed from an existing set of normal examples. Further, this synthesis approach has useful applications as a data augmentation technique. An incrementally trained Bayesian convolutional neural network (CNN) is used to carefully select the set of abnormal samples that can be added. Finally through this synthesis approach we obtain a comparable set of abnormal samples that can be used for training the CNN for the classification of normal vs abnormal samples. We show that this method generalizes to multiple settings by evaluating it on two real world datasets and achieves improved performance over other probabilistic techniques that have been used in the past for this task.
Looking back at Labels: A Class based Domain Adaptation Technique
Apr 02, 2019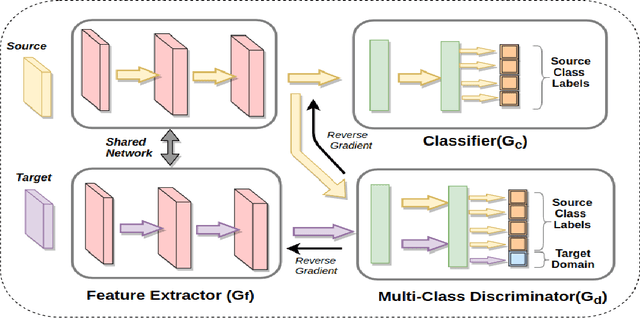
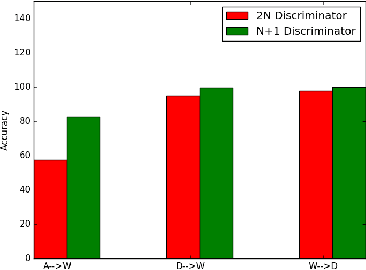
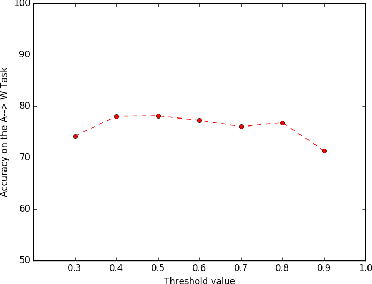
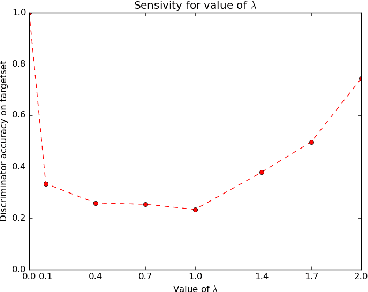
In this paper, we solve the problem of adapting classifiers across domains. We consider the problem of domain adaptation for multi-class classification where we are provided a labeled set of examples in a source dataset and we are provided a target dataset with no supervision. In this setting, we propose an adversarial discriminator based approach. While the approach based on adversarial discriminator has been previously proposed; in this paper, we present an informed adversarial discriminator. Our observation relies on the analysis that shows that if the discriminator has access to all the information available including the class structure present in the source dataset, then it can guide the transformation of features of the target set of classes to a more structure adapted space. Using this formulation, we obtain state-of-the-art results for the standard evaluation on benchmark datasets. We further provide detailed analysis which shows that using all the labeled information results in an improved domain adaptation.
HetConv: Heterogeneous Kernel-Based Convolutions for Deep CNNs
Mar 25, 2019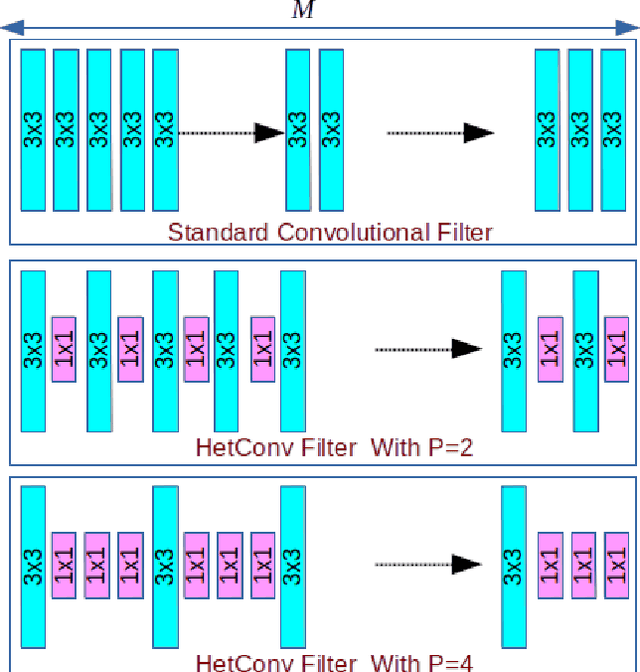
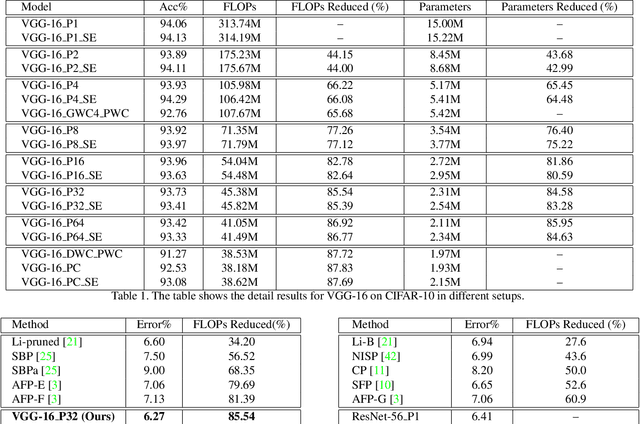
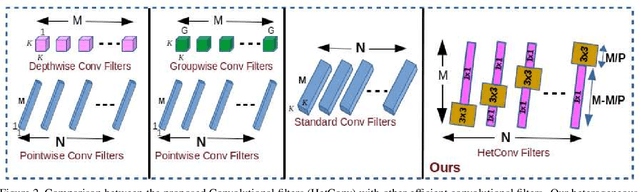
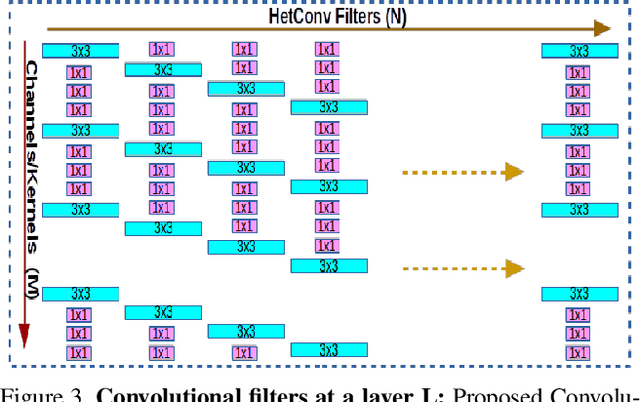
We present a novel deep learning architecture in which the convolution operation leverages heterogeneous kernels. The proposed HetConv (Heterogeneous Kernel-Based Convolution) reduces the computation (FLOPs) and the number of parameters as compared to standard convolution operation while still maintaining representational efficiency. To show the effectiveness of our proposed convolution, we present extensive experimental results on the standard convolutional neural network (CNN) architectures such as VGG \cite{vgg2014very} and ResNet \cite{resnet}. We find that after replacing the standard convolutional filters in these architectures with our proposed HetConv filters, we achieve 3X to 8X FLOPs based improvement in speed while still maintaining (and sometimes improving) the accuracy. We also compare our proposed convolutions with group/depth wise convolutions and show that it achieves more FLOPs reduction with significantly higher accuracy.
CVIT-MT Systems for WAT-2018
Mar 19, 2019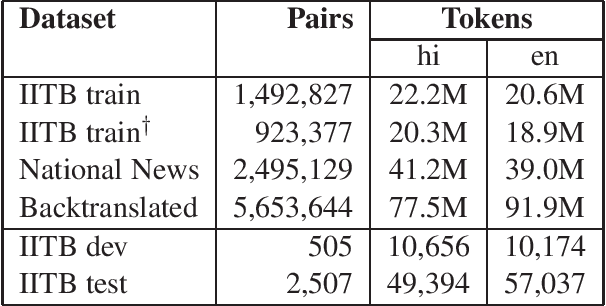
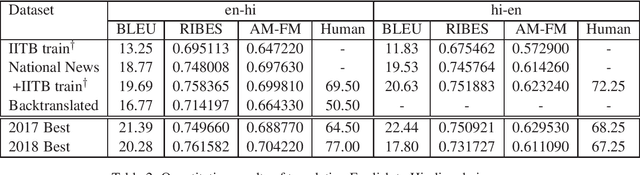
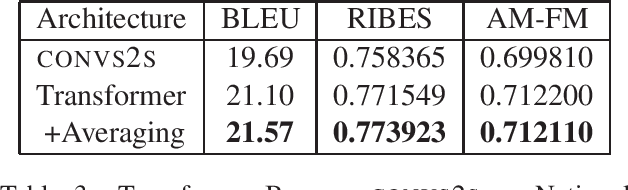
This document describes the machine translation system used in the submissions of IIIT-Hyderabad CVIT-MT for the WAT-2018 English-Hindi translation task. Performance is evaluated on the associated corpus provided by the organizers. We experimented with convolutional sequence to sequence architectures. We also train with additional data obtained through backtranslation.
Accuracy Booster: Performance Boosting using Feature Map Re-calibration
Mar 11, 2019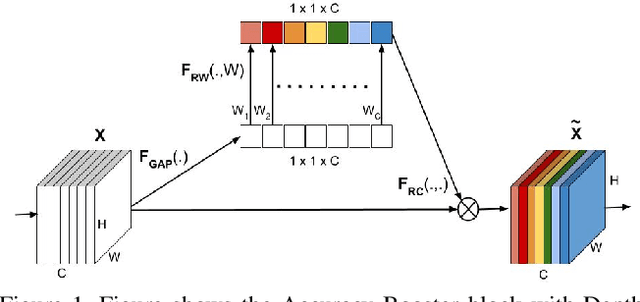

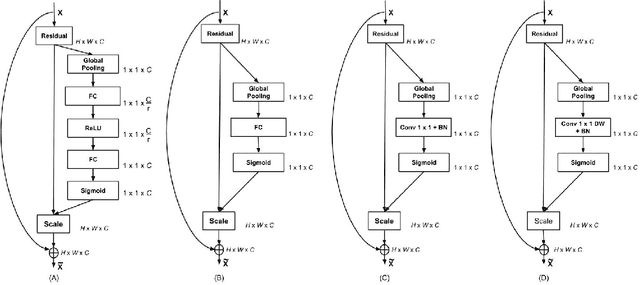
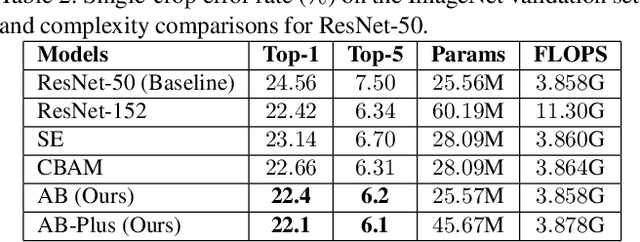
Convolution Neural Networks (CNN) have been extremely successful in solving intensive computer vision tasks. The convolutional filters used in CNNs have played a major role in this success, by extracting useful features from the inputs. Recently researchers have tried to boost the performance of CNNs by re-calibrating the feature maps produced by these filters, e.g., Squeeze-and-Excitation Networks (SENets). These approaches have achieved better performance by \textit{Exciting} up the important channels or feature maps while diminishing the rest. However, in the process, architectural complexity has increased. We propose an architectural block that introduces much lower complexity than the existing methods of CNN performance boosting while performing significantly better than them. We carry out experiments on the CIFAR, ImageNet and MS-COCO datasets, and show that the proposed block can challenge the state-of-the-art results. Our method boosts the ResNet-50 architecture to perform comparably to the ResNet-152 architecture, which is a three times deeper network, on classification. We also show experimentally that our method is not limited to classification but also generalizes well to other tasks such as object detection.
PUTWorkbench: Analysing Privacy in AI-intensive Systems
Feb 05, 2019

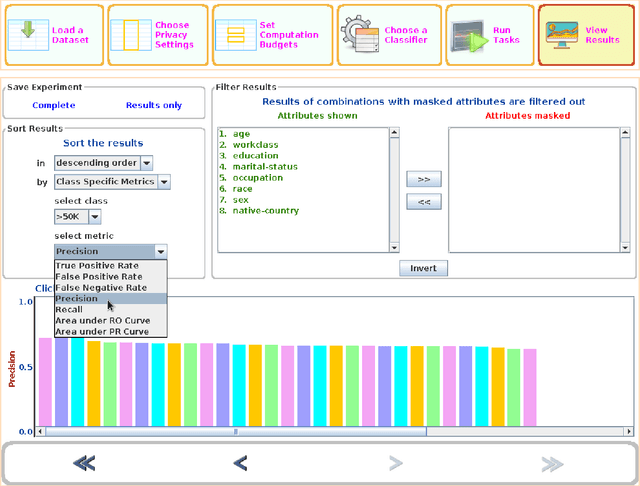

AI intensive systems that operate upon user data face the challenge of balancing data utility with privacy concerns. We propose the idea and present the prototype of an open-source tool called Privacy Utility Trade-off (PUT) Workbench which seeks to aid software practitioners to take such crucial decisions. We pick a simple privacy model that doesn't require any background knowledge in Data Science and show how even that can achieve significant results over standard and real-life datasets. The tool and the source code is made freely available for extensions and usage.
Leveraging Filter Correlations for Deep Model Compression
Nov 26, 2018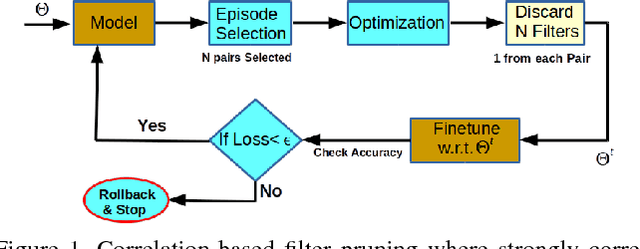
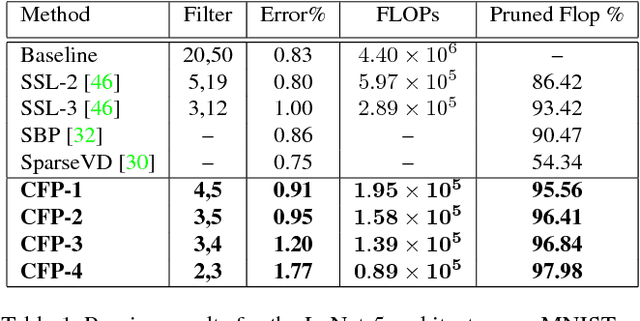
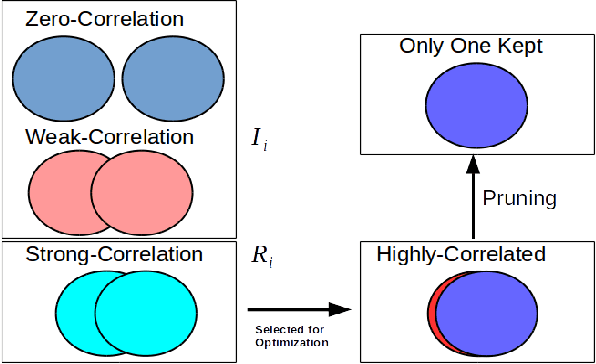
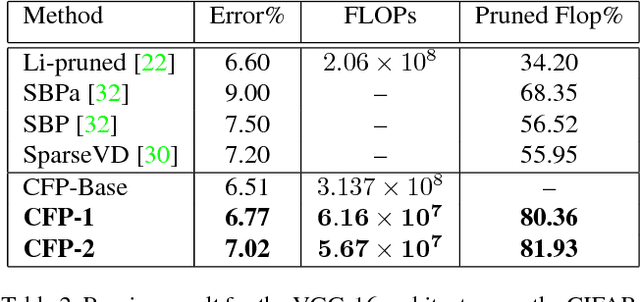
We present a filter correlation based model compression approach for deep convolutional neural networks. Our approach iteratively identifies pairs of filters with largest pairwise correlations and discards one of the filters from each such pair. However, instead of discarding one of the filter from such pairs na\"{i}vely, we further optimize the model so that the two filters from each such pair are as highly correlated as possible so that discarding one of the filters from the pairs results in as little information loss as possible. After discarding the filters in each round, we further finetune the model to recover from the potential small loss incurred by the compression. We evaluate our proposed approach using a comprehensive set of experiments and ablation studies. Our compression method yields state-of-the-art FLOPs compression rates on various benchmarks, such as LeNet-5, VGG-16, and ResNet-50,56, which are still achieving excellent predictive performance for tasks such as object detection on benchmark datasets.