 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stationarity-and-Coupling Criterion for Training-Free Time-Lagged Spectral Embeddings of Multivariate Time Series
Jun 11, 2026We study training-free fixed-length descriptors for multivariate time series and ask not merely whether such a descriptor performs well, but when it can be expected to work at all. Our object of study is $D(τ)$, built from a time-lagged correlation matrix truncated at the Marchenko-Pastur edge so that only signal-bearing eigenvalues survive and classified by cosine similarity to class centroids with zero learned parameters. The central contribution is not the descriptor but a falsifiable applicability criterion for it. Working from a stationary Gaussian VAR(1) model, we argue that $D(τ)$ separates two classes when the signals are approximately stationary and the class information lives in their cross-channel temporal coupling rather than in marginal per-channel power. We derive, semi-formally, three consequences: a distinguishability condition, why the static ($τ=0$) covariance collapses to chance, and why a stationary but power-discriminated paradigm defeats the descriptor. The criterion is operational: a two-part pre-flight test -- an augmented Dickey-Fuller stationarity check and a power-baseline saturation check -- predicts applicability before any training. We validate both halves on a mixed assortment. On four paradigms that satisfy the criterion (Sleep-EDF, BCI-IV-2a, MIT-BIH, ESC-50) the descriptor is competitive with strong baselines at a fraction of their cost, reaching $88.5\pm4.5\%$ under 20-subject leave-one-subject-out on Sleep-EDF on a single CPU thread. On three that violate it -- non-stationary ERPs, and financial-volatility and wearable-stress regimes that are power-discriminated -- it fails exactly as the pre-flight predicts, and these negatives are the more informative half. We are explicit that $D(τ)$ is not the most accurate representation; its value is a compact, training-free embedding whose domain of validity is known in advance.
RAGulating Compliance: A Multi-Agent Knowledge Graph for Regulatory QA
Aug 13, 2025Regulatory compliance question answering (QA) requires precise, verifiable information, and domain-specific expertise, posing challenges for Large Language Models (LLMs). In this work, we present a novel multi-agent framework that integrates a Knowledge Graph (KG) of Regulatory triplets with Retrieval-Augmented Generation (RAG) to address these demands. First, agents build and maintain an ontology-free KG by extracting subject--predicate--object (SPO) triplets from regulatory documents and systematically cleaning, normalizing, deduplicating, and updating them. Second, these triplets are embedded and stored along with their corresponding textual sections and metadata in a single enriched vector database, allowing for both graph-based reasoning and efficient information retrieval. Third, an orchestrated agent pipeline leverages triplet-level retrieval for question answering, ensuring high semantic alignment between user queries and the factual "who-did-what-to-whom" core captured by the graph. Our hybrid system outperforms conventional methods in complex regulatory queries, ensuring factual correctness with embedded triplets, enabling traceability through a unified vector database, and enhancing understanding through subgraph visualization, providing a robust foundation for compliance-driven and broader audit-focused applications.
Think Inside the JSON: Reinforcement Strategy for Strict LLM Schema Adherence
Feb 18, 2025
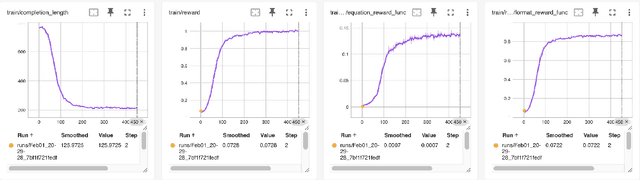


In this paper, we address the challenge of enforcing strict schema adherence in large language model (LLM) generation by leveraging LLM reasoning capabilities. Building on the DeepSeek R1 reinforcement learning framework, our approach trains structured reasoning skills of a 1.5B parameter model through a novel pipeline that combines synthetic reasoning dataset construction with custom reward functions under Group Relative Policy Optimization (GRPO). Specifically, we first perform R1 reinforcement learning on a 20K sample unstructured-to-structured dataset, mirroring the original DeepSeek R1 methods, to establish core reasoning abilities. Subsequently, we performed supervised fine-tuning on a separate 10K reasoning sample dataset, focusing on refining schema adherence for downstream tasks. Despite the relatively modest training scope, requiring approximately 20 hours on an 8xH100 GPU cluster for GRPO training and 3 hours on 1xA100 for SFT, our model demonstrates robust performance in enforcing schema consistency. We compare our ThinkJSON approach against the original DeepSeek R1 (671B), distilled versions of DeepSeek R1 (Qwen-1.5B and Qwen-7B), and Gemini 2.0 Flash (70B), showcasing its effectiveness in real-world applications. Our results underscore the practical utility of a resource-efficient framework for schema-constrained text generation.