 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn, Unlearn and Relearn: An Online Learning Paradigm for Deep Neural Networks
Mar 18, 2023Deep neural networks (DNNs) are often trained on the premise that the complete training data set is provided ahead of time. However, in real-world scenarios, data often arrive in chunks over time. This leads to important considerations about the optimal strategy for training DNNs, such as whether to fine-tune them with each chunk of incoming data (warm-start) or to retrain them from scratch with the entire corpus of data whenever a new chunk is available. While employing the latter for training can be resource-intensive, recent work has pointed out the lack of generalization in warm-start models. Therefore, to strike a balance between efficiency and generalization, we introduce Learn, Unlearn, and Relearn (LURE) an online learning paradigm for DNNs. LURE interchanges between the unlearning phase, which selectively forgets the undesirable information in the model through weight reinitialization in a data-dependent manner, and the relearning phase, which emphasizes learning on generalizable features. We show that our training paradigm provides consistent performance gains across datasets in both classification and few-shot settings. We further show that it leads to more robust and well-calibrated models.
Differencing based Self-supervised pretraining for Scene Change Detection
Aug 11, 2022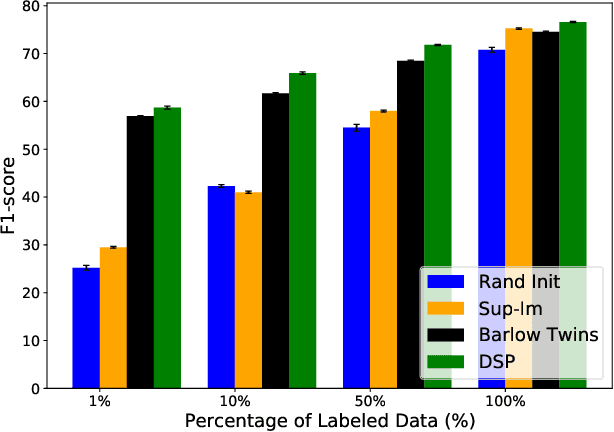
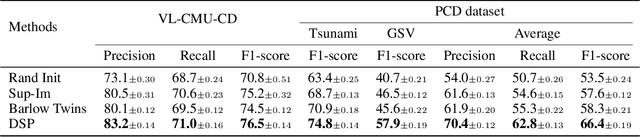
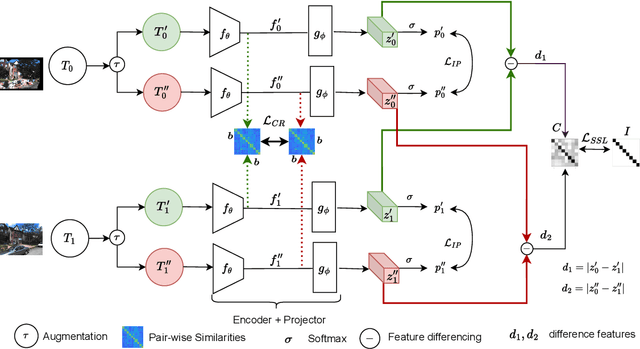
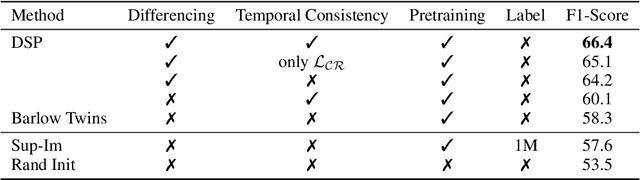
Scene change detection (SCD), a crucial perception task, identifies changes by comparing scenes captured at different times. SCD is challenging due to noisy changes in illumination, seasonal variations, and perspective differences across a pair of views. Deep neural network based solutions require a large quantity of annotated data which is tedious and expensive to obtain. On the other hand, transfer learning from large datasets induces domain shift. To address these challenges, we propose a novel \textit{Differencing self-supervised pretraining (DSP)} method that uses feature differencing to learn discriminatory representations corresponding to the changed regions while simultaneously tackling the noisy changes by enforcing temporal invariance across views. Our experimental results on SCD datasets demonstrate the effectiveness of our method, specifically to differences in camera viewpoints and lighting conditions. Compared against the self-supervised Barlow Twins and the standard ImageNet pretraining that uses more than a million additional labeled images, DSP can surpass it without using any additional data. Our results also demonstrate the robustness of DSP to natural corruptions, distribution shift, and learning under limited labeled data.