 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of Vietnamese Statistical Parametric Speech Synthesis Systems
May 26, 2020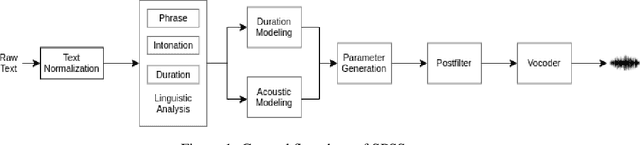
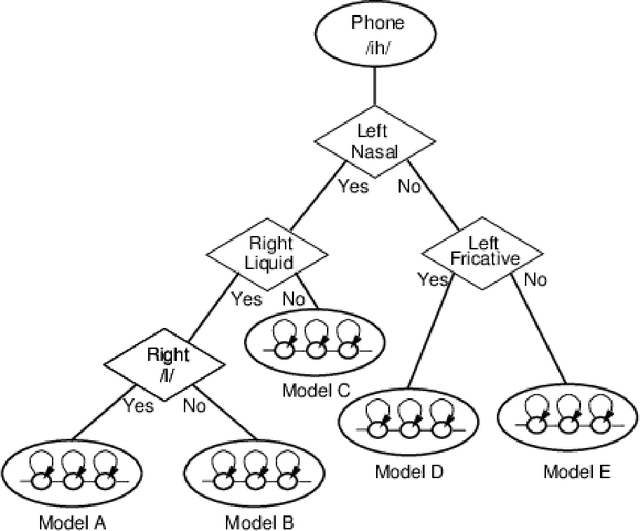
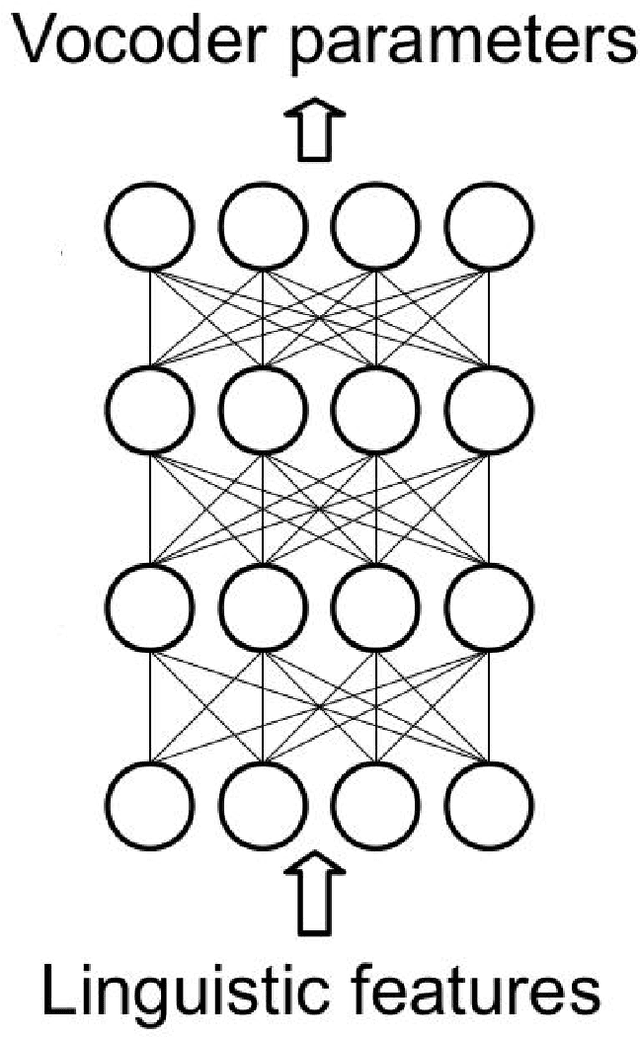
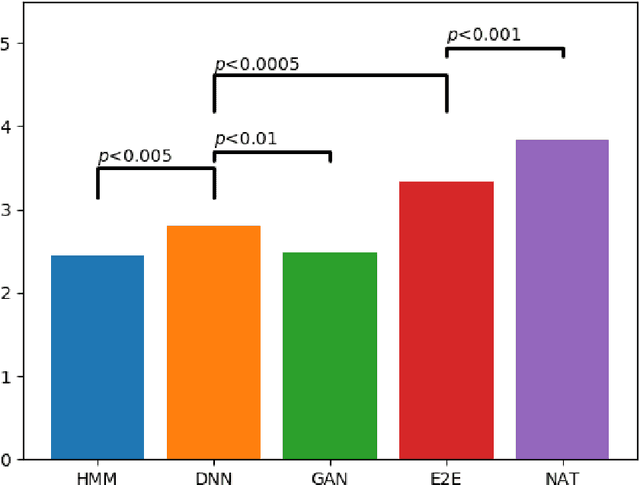
In recent years, statistical parametric speech synthesis (SPSS) systems have been widely utilized in many interactive speech-based systems (e.g.~Amazon's Alexa, Bose's headphones). To select a suitable SPSS system, both speech quality and performance efficiency (e.g.~decoding time) must be taken into account. In the paper, we compared four popular Vietnamese SPSS techniques using: 1) hidden Markov models (HMM), 2) deep neural networks (DNN), 3) generative adversarial networks (GAN), and 4) end-to-end (E2E) architectures, which consists of Tacontron~2 and WaveGlow vocoder in terms of speech quality and performance efficiency. We showed that the E2E systems accomplished the best quality, but required the power of GPU to achieve real-time performance. We also showed that the HMM-based system had inferior speech quality, but it was the most efficient system. Surprisingly, the E2E systems were more efficient than the DNN and GAN in inference on GPU. Surprisingly, the GAN-based system did not outperform the DNN in term of quality.
Data Processing for Optimizing Naturalness of Vietnamese Text-to-speech System
Apr 20, 2020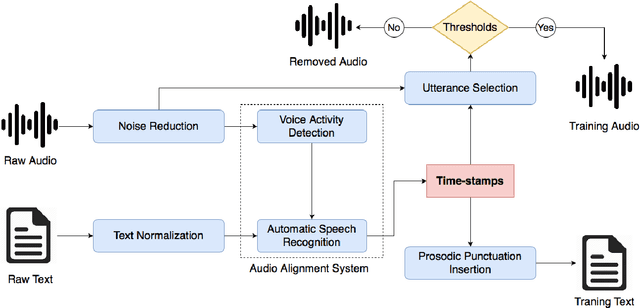
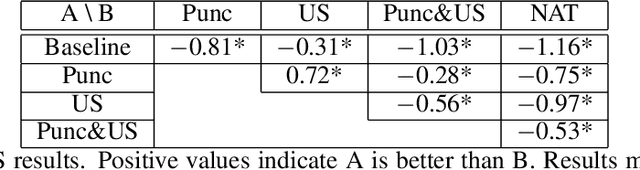
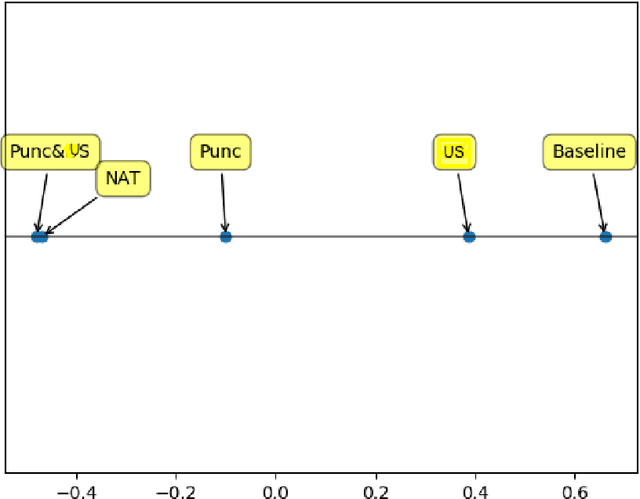
Abstract End-to-end text-to-speech (TTS) systems has proved its great success in the presence of a large amount of high-quality training data recorded in anechoic room with high-quality microphone. Another approach is to use available source of found data like radio broadcast news. We aim to optimize the naturalness of TTS system on the found data using a novel data processing method. The data processing method includes 1) utterance selection and 2) prosodic punctuation insertion to prepare training data which can optimize the naturalness of TTS systems. We showed that using the processing data method, an end-to-end TTS achieved a mean opinion score (MOS) of 4.1 compared to 4.3 of natural speech. We showed that the punctuation insertion contributed the most to the result. To facilitate the research and development of TTS systems, we distributed the processed data of one speaker at https://forms.gle/6Hk5YkqgDxAaC2BU6.