 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAC: Admissible-by-Architecture Differentiable Landmark Compression for ALT
Apr 22, 2026We introduce \textbf{AAC} (Architecturally Admissible Compressor), a differentiable landmark-selection module for ALT (A*, Landmarks, and Triangle inequality) shortest-path heuristics whose outputs are admissible by construction: each forward pass is a row-stochastic mixture of triangle-inequality lower bounds, so the heuristic is admissible for \emph{every} parameter setting without requiring convergence, calibration, or projection. At deployment, the module reduces to classical ALT on a learned subset, composing end-to-end with neural encoders while preserving the classical toolchain. The construction is the first differentiable instance of the compress-while-preserving-admissibility tradition in classical heuristic search. Under a matched per-vertex memory protocol, we establish that ALT with farthest-point-sampling landmarks (FPS-ALT) has provably near-optimal coverage on metric graphs, leaving at most a few percentage points of headroom for \emph{any} selector. AAC operates near this ceiling: the gap is $0.9$--$3.9$ percentage points on 9 road networks and ${\leq}1.3$ percentage points on synthetic graphs, with zero admissibility violations across $1{,}500+$ queries and all logged runs. At matched memory, AAC is also $1.2$--$1.5{\times}$ faster than FPS-ALT at the median query on DIMACS road networks, amortizing its offline cost within $170$--$1{,}924$ queries. A controlled ablation isolates the binding constraint: training-objective drift under default initialization, not architectural capacity; identity-on-first-$m$ initialization closes the expansion-count gap entirely. We release the module, a reusable matched-memory benchmarking protocol with paired two-one-sided-test (TOST) equivalence and pre-registration, and a reference compressed-differential-heuristics baseline.
Bayes-Adaptive Deep Model-Based Policy Optimisation
Oct 29, 2020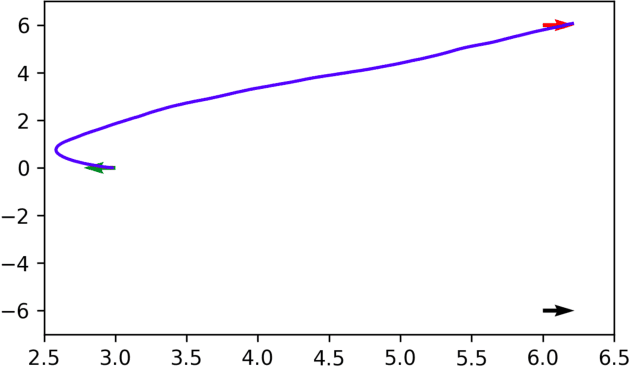
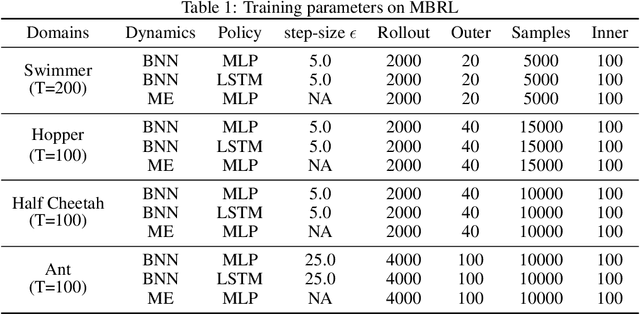
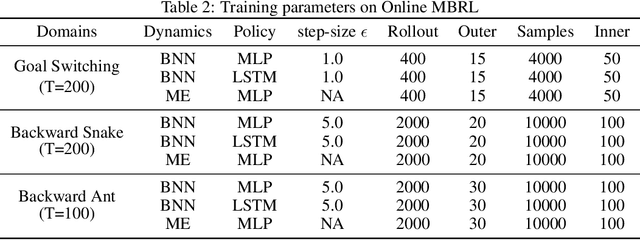
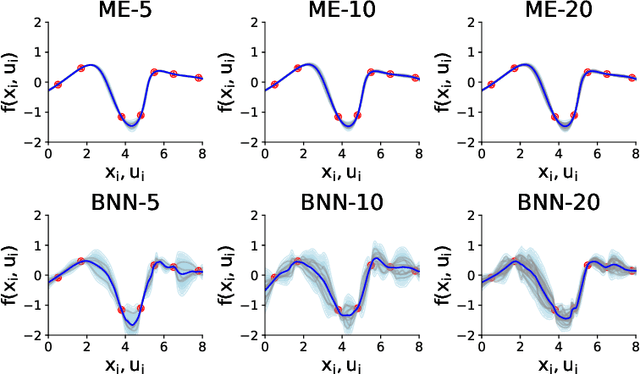
We introduce a Bayesian (deep) model-based reinforcement learning method (RoMBRL) that can capture model uncertainty to achieve sample-efficient policy optimisation. We propose to formulate the model-based policy optimisation problem as a Bayes-adaptive Markov decision process (BAMDP). RoMBRL maintains model uncertainty via belief distributions through a deep Bayesian neural network whose samples are generated via stochastic gradient Hamiltonian Monte Carlo. Uncertainty is propagated through simulations controlled by sampled models and history-based policies. As beliefs are encoded in visited histories, we propose a history-based policy network that can be end-to-end trained to generalise across history space and will be trained using recurrent Trust-Region Policy Optimisation. We show that RoMBRL outperforms existing approaches on many challenging control benchmark tasks in terms of sample complexity and task performance. The source code of this paper is also publicly available on https://github.com/thobotics/RoMBRL.