 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Jun 11, 2026Agent systems are advancing quickly across domains, but their evaluation remains fragmented. Most benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and limit fair comparison across diverse agent designs. The root problem is the lack of an open, agent-agnostic assessment interface. We advocate Agentified Agent Assessment (AAA), where evaluation is performed by judge agents and all participants interact through standardized protocols: A2A for task management and MCP for tool access. Conventional benchmarking defines two separate interfaces, one for the benchmark and one for the agent, while AAA only needs one; this yields a generic, unified framework that separates assessment logic from agent implementation and enables reproducible, interoperable, and multi-agent evaluation. We further introduce AgentBeats as a concrete realization of AAA: we identify five practical operation modes that make standardized assessment compatible with real-world constraints on openness, privacy, and reproducibility. To evaluate our design at scale, we conduct two studies: a five-month open competition that drew 298 judge agents across 12 categories together with 467 subject agents from independent participants, showing that AAA applies across a heterogeneous range of benchmarks; and a case study on coding agents that confirms agentified evaluation preserves fidelity with the public record while surfacing previously missing head-to-head results, yielding research insights about agent design. Combining a community-scale field study and a controlled coding case study, we verify that AAA delivers coverage, practicality, and fidelity across heterogeneous scenarios at scale. Together, AAA and AgentBeats offer a clear path toward open, standardized, and reproducible agent assessment.
$τ$-Voice: Benchmarking Full-Duplex Voice Agents on Real-World Domains
Mar 14, 2026Full-duplex voice agents--systems that listen and speak simultaneously--are rapidly moving from research to production. However, existing evaluations address conversational dynamics and task completion in isolation. We introduce $τ$-voice, a benchmark for evaluating voice agents on grounded tasks with real-world complexity: agents must navigate complex multi-turn conversations, adhere to domain policies, and interact with the environment. The framework extends $τ^2$-bench into a novel voice agent benchmark combining verifiable completion of complex grounded tasks, full-duplex interaction, and realistic audio--enabling direct comparison between voice and text performance. A controllable and realistic voice user simulator provides diverse accents, realistic audio environments, and rich turn-taking dynamics; by decoupling simulation from wall-clock time, the user simulator can use the most capable LLM without real-time constraints. We evaluate task completion (pass@1) and voice interaction quality across 278 tasks: while GPT-5 (reasoning) achieves 85%, voice agents reach only 31--51% under clean conditions and 26--38% under realistic conditions with noise and diverse accents--retaining only 30--45% of text capability; qualitative analysis confirms 79--90% of failures stem from agent behavior, suggesting that observed failures primarily reflect agent behavior under our evaluation setup. $τ$-voice provides a reproducible testbed for measuring progress toward voice agents that are natural, conversational, and reliable.
$τ$-Knowledge: Evaluating Conversational Agents over Unstructured Knowledge
Mar 04, 2026Conversational agents are increasingly deployed in knowledge-intensive settings, where correct behavior depends on retrieving and applying domain-specific knowledge from large, proprietary, and unstructured corpora during live interactions with users. Yet most existing benchmarks evaluate retrieval or tool use independently of each other, creating a gap in realistic, fully agentic evaluation over unstructured data in long-horizon interactions. We introduce $τ$-Knowledge, an extension of $τ$-Bench for evaluating agents in environments where success depends on coordinating external, natural-language knowledge with tool outputs to produce verifiable, policy-compliant state changes. Our new domain, $τ$-Banking, models realistic fintech customer support workflows in which agents must navigate roughly 700 interconnected knowledge documents while executing tool-mediated account updates. Across embedding-based retrieval and terminal-based search, even frontier models with high reasoning budgets achieve only $\sim$25.5% pass^1, with reliability degrading sharply over repeated trials. Agents struggle to retrieve the correct documents from densely interlinked knowledge bases and to reason accurately over complex internal policies. Overall, $τ$-Knowledge provides a realistic testbed for developing agents that integrate unstructured knowledge in human-facing deployments.
$τ^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Jun 09, 2025Existing benchmarks for conversational AI agents simulate single-control environments, where only the AI agent can use tools to interact with the world, while the user remains a passive information provider. This differs from real-world scenarios like technical support, where users need to actively participate in modifying the state of the (shared) world. In order to address this gap, we introduce $\tau^2$-bench, with four key contributions: 1) A novel Telecom dual-control domain modeled as a Dec-POMDP, where both agent and user make use of tools to act in a shared, dynamic environment that tests both agent coordination and communication, 2) A compositional task generator that programmatically creates diverse, verifiable tasks from atomic components, ensuring domain coverage and controlled complexity, 3) A reliable user simulator tightly coupled with the environment, whose behavior is constrained by tools and observable states, improving simulation fidelity, 4) Fine-grained analysis of agent performance through multiple ablations including separating errors arising from reasoning vs communication/coordination. In particular, our experiments show significant performance drops when agents shift from no-user to dual-control, highlighting the challenges of guiding users. Overall, $\tau^2$-bench provides a controlled testbed for agents that must both reason effectively and guide user actions.
Controllable Discovery of Intents: Incremental Deep Clustering Using Semi-Supervised Contrastive Learning
Oct 18, 2024



Deriving value from a conversational AI system depends on the capacity of a user to translate the prior knowledge into a configuration. In most cases, discovering the set of relevant turn-level speaker intents is often one of the key steps. Purely unsupervised algorithms provide a natural way to tackle discovery problems but make it difficult to incorporate constraints and only offer very limited control over the outcomes. Previous work has shown that semi-supervised (deep) clustering techniques can allow the system to incorporate prior knowledge and constraints in the intent discovery process. However they did not address how to allow for control through human feedback. In our Controllable Discovery of Intents (CDI) framework domain and prior knowledge are incorporated using a sequence of unsupervised contrastive learning on unlabeled data followed by fine-tuning on partially labeled data, and finally iterative refinement of clustering and representations through repeated clustering and pseudo-label fine-tuning. In addition, we draw from continual learning literature and use learning-without-forgetting to prevent catastrophic forgetting across those training stages. Finally, we show how this deep-clustering process can become part of an incremental discovery strategy with human-in-the-loop. We report results on both CLINC and BANKING datasets. CDI outperforms previous works by a significant margin: 10.26% and 11.72% respectively.
Multi-step Inference over Unstructured Data
Jul 08, 2024



The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
Multi-step Knowledge Retrieval and Inference over Unstructured Data
Jun 26, 2024The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
LLM-ARC: Enhancing LLMs with an Automated Reasoning Critic
Jun 25, 2024



We introduce LLM-ARC, a neuro-symbolic framework designed to enhance the logical reasoning capabilities of Large Language Models (LLMs), by combining them with an Automated Reasoning Critic (ARC). LLM-ARC employs an Actor-Critic method where the LLM Actor generates declarative logic programs along with tests for semantic correctness, while the Automated Reasoning Critic evaluates the code, runs the tests and provides feedback on test failures for iterative refinement. Implemented using Answer Set Programming (ASP), LLM-ARC achieves a new state-of-the-art accuracy of 88.32% on the FOLIO benchmark which tests complex logical reasoning capabilities. Our experiments demonstrate significant improvements over LLM-only baselines, highlighting the importance of logic test generation and iterative self-refinement. We achieve our best result using a fully automated self-supervised training loop where the Actor is trained on end-to-end dialog traces with Critic feedback. We discuss potential enhancements and provide a detailed error analysis, showcasing the robustness and efficacy of LLM-ARC for complex natural language reasoning tasks.
Real-time Caller Intent Detection In Human-Human Customer Support Spoken Conversations
Aug 14, 2022
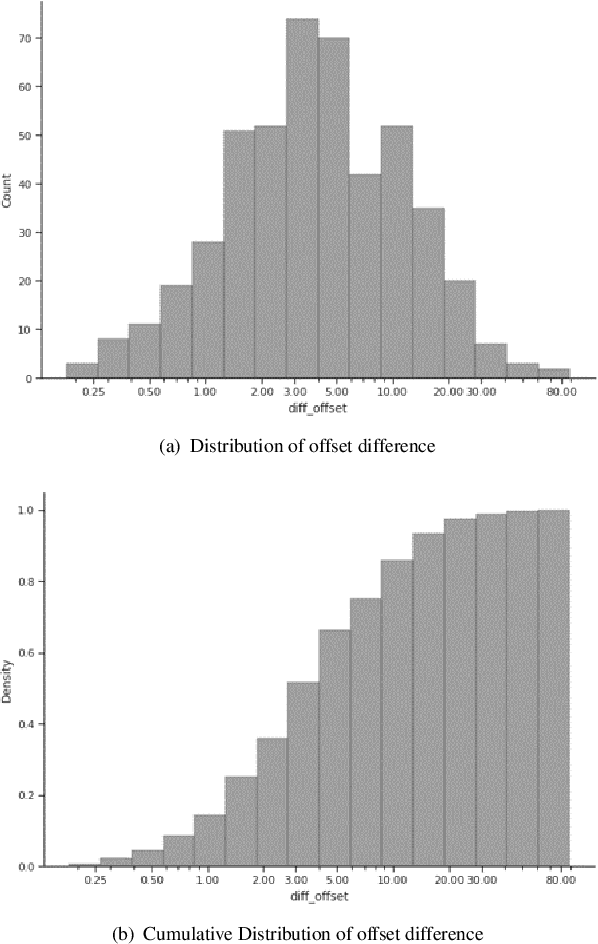
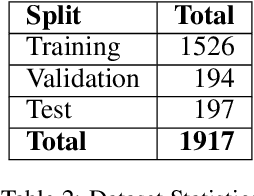
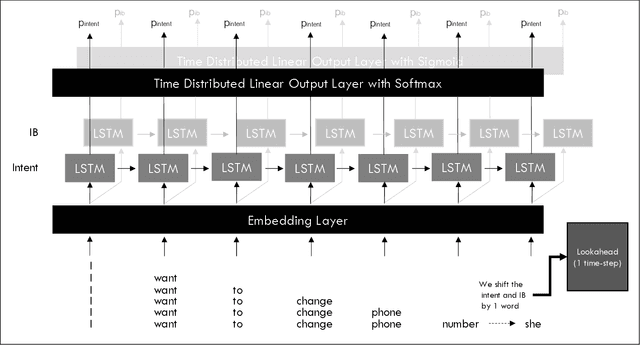
Agent assistance during human-human customer support spoken interactions requires triggering workflows based on the caller's intent (reason for call). Timeliness of prediction is essential for a good user experience. The goal is for a system to detect the caller's intent at the time the agent would have been able to detect it (Intent Boundary). Some approaches focus on predicting the output offline, i.e. once the full spoken input (e.g. the whole conversational turn) has been processed by the ASR system. This introduces an undesirable latency in the prediction each time the intent could have been detected earlier in the turn. Recent work on voice assistants has used incremental real-time predictions at a word-by-word level to detect intent before the end of a command. Human-directed and machine-directed speech however have very different characteristics. In this work, we propose to apply a method developed in the context of voice-assistant to the problem of online real time caller's intent detection in human-human spoken interactions. We use a dual architecture in which two LSTMs are jointly trained: one predicting the Intent Boundary (IB) and then other predicting the intent class at the IB. We conduct our experiments on our private dataset comprising transcripts of human-human telephone conversations from the telecom customer support domain. We report results analyzing both the accuracy of our system as well as the impact of different architectures on the trade off between overall accuracy and prediction latency.