 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Aware Prototype Memory for Face Representation Learning
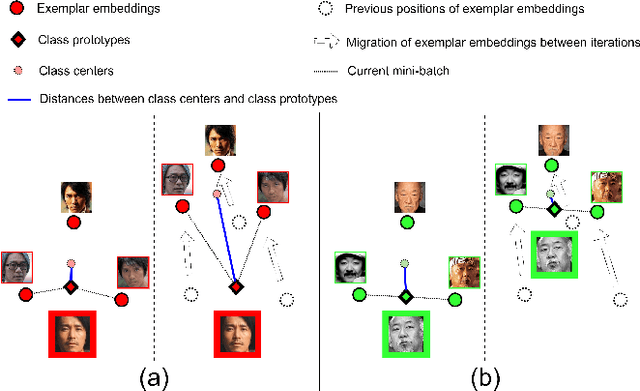
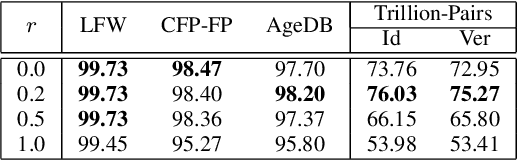
Nov 13, 2023Prototype Memory is a powerful model for face representation learning. It enables the training of face recognition models using datasets of any size, with on-the-fly generation of prototypes (classifier weights) and efficient ways of their utilization. Prototype Memory demonstrated strong results in many face recognition benchmarks. However, the algorithm of prototype generation, used in it, is prone to the problems of imperfectly calculated prototypes in case of low-quality or poorly recognizable faces in the images, selected for the prototype creation. All images of the same person, presented in the mini-batch, used with equal weights, and the resulting averaged prototype could be contaminated with imperfect embeddings of such face images. It can lead to misdirected training signals and impair the performance of the trained face recognition models. In this paper, we propose a simple and effective way to improve Prototype Memory with quality-aware prototype generation. Quality-Aware Prototype Memory uses different weights for images of different quality in the process of prototype generation. With this improvement, prototypes get more valuable information from high-quality images and less hurt by low-quality ones. We propose and compare several methods of quality estimation and usage, perform extensive experiments on the different face recognition benchmarks and demonstrate the advantages of the proposed model compared to the basic version of Prototype Memory.
Prototype Memory for Large-scale Face Representation Learning
May 05, 2021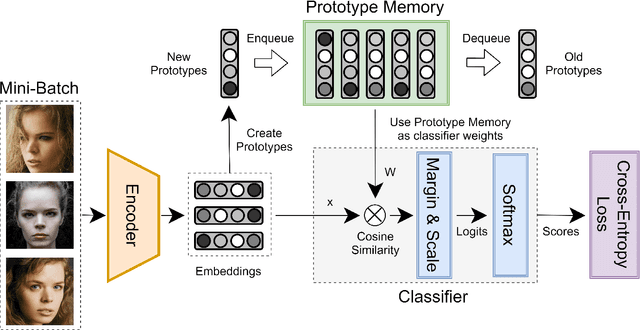

Face representation learning using datasets with massive number of identities requires appropriate training methods. Softmax-based approach, currently the state-of-the-art in face recognition, in its usual "full softmax" form is not suitable for datasets with millions of persons. Several methods, based on the "sampled softmax" approach, were proposed to remove this limitation. These methods, however, have a set of disadvantages. One of them is a problem of "prototype obsolescence": classifier weights (prototypes) of the rarely sampled classes, receive too scarce gradients and become outdated and detached from the current encoder state, resulting in an incorrect training signals. This problem is especially serious in ultra-large-scale datasets. In this paper, we propose a novel face representation learning model called Prototype Memory, which alleviates this problem and allows training on a dataset of any size. Prototype Memory consists of the limited-size memory module for storing recent class prototypes and employs a set of algorithms to update it in appropriate way. New class prototypes are generated on the fly using exemplar embeddings in the current mini-batch. These prototypes are enqueued to the memory and used in a role of classifier weights for usual softmax classification-based training. To prevent obsolescence and keep the memory in close connection with encoder, prototypes are regularly refreshed, and oldest ones are dequeued and disposed. Prototype Memory is computationally efficient and independent of dataset size. It can be used with various loss functions, hard example mining algorithms and encoder architectures. We prove the effectiveness of the proposed model by extensive experiments on popular face recognition benchmarks.