 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode Injection Attacks on Graphs via Reinforcement Learning
Sep 14, 2019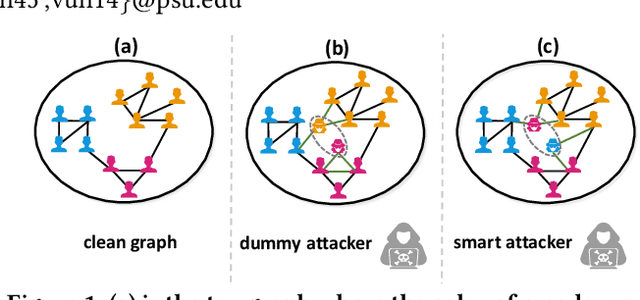
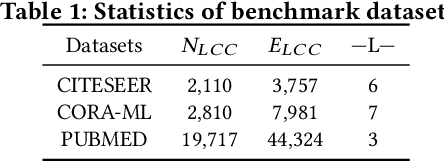
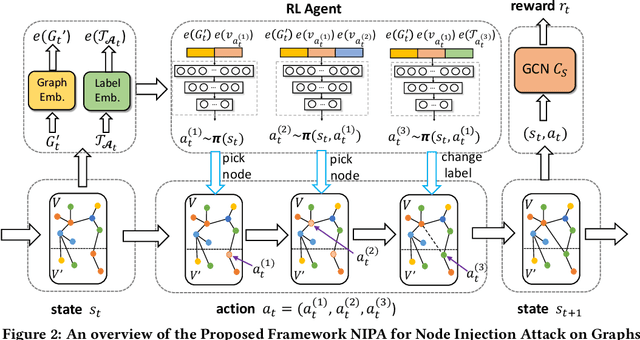
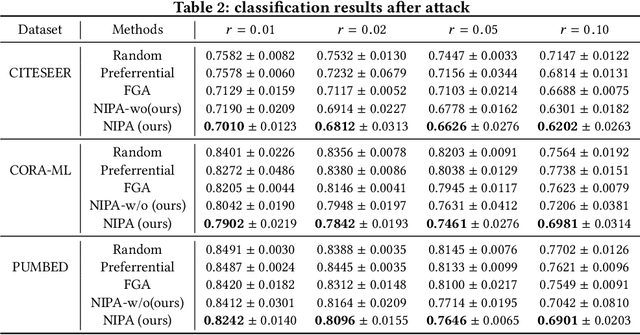
Real-world graph applications, such as advertisements and product recommendations make profits based on accurately classify the label of the nodes. However, in such scenarios, there are high incentives for the adversaries to attack such graph to reduce the node classification performance. Previous work on graph adversarial attacks focus on modifying existing graph structures, which is infeasible in most real-world applications. In contrast, it is more practical to inject adversarial nodes into existing graphs, which can also potentially reduce the performance of the classifier. In this paper, we study the novel node injection poisoning attacks problem which aims to poison the graph. We describe a reinforcement learning based method, namely NIPA, to sequentially modify the adversarial information of the injected nodes. We report the results of experiments using several benchmark data sets that show the superior performance of the proposed method NIPA, relative to the existing state-of-the-art methods.
MEGAN: A Generative Adversarial Network for Multi-View Network Embedding
Aug 20, 2019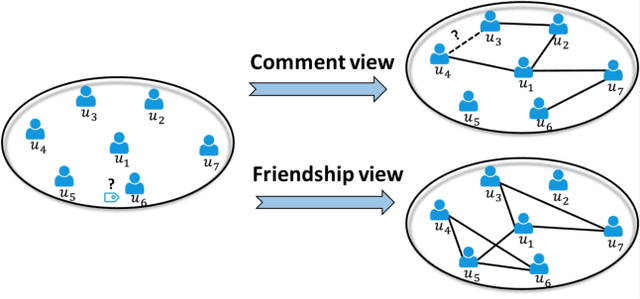
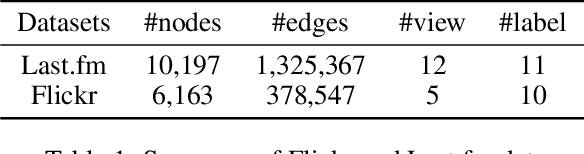
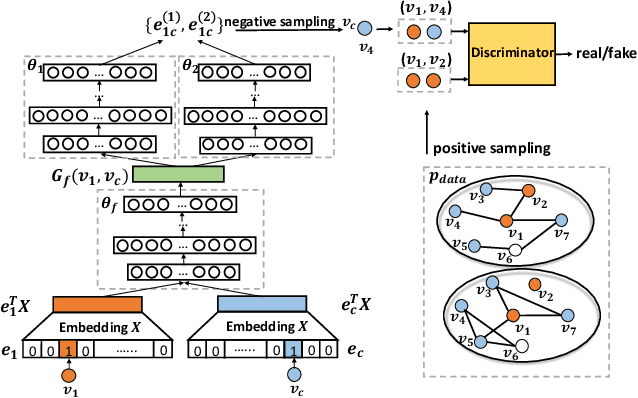
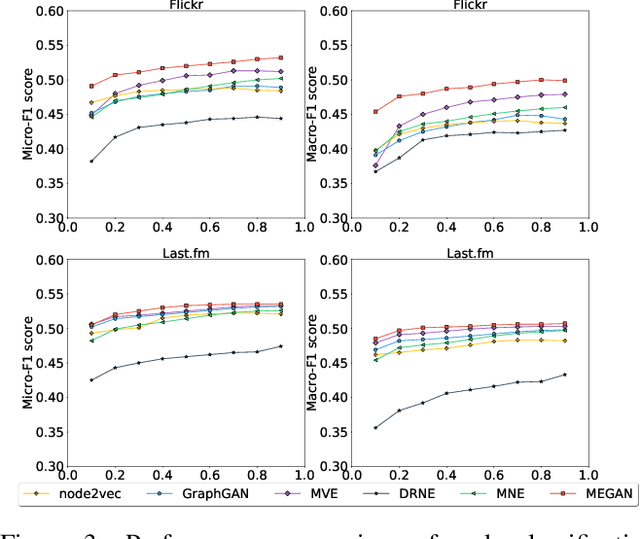
Data from many real-world applications can be naturally represented by multi-view networks where the different views encode different types of relationships (e.g., friendship, shared interests in music, etc.) between real-world individuals or entities. There is an urgent need for methods to obtain low-dimensional, information preserving and typically nonlinear embeddings of such multi-view networks. However, most of the work on multi-view learning focuses on data that lack a network structure, and most of the work on network embeddings has focused primarily on single-view networks. Against this background, we consider the multi-view network representation learning problem, i.e., the problem of constructing low-dimensional information preserving embeddings of multi-view networks. Specifically, we investigate a novel Generative Adversarial Network (GAN) framework for Multi-View Network Embedding, namely MEGAN, aimed at preserving the information from the individual network views, while accounting for connectivity across (and hence complementarity of and correlations between) different views. The results of our experiments on two real-world multi-view data sets show that the embeddings obtained using MEGAN outperform the state-of-the-art methods on node classification, link prediction and visualization tasks.
Fairness in Algorithmic Decision Making: An Excursion Through the Lens of Causality
Mar 27, 2019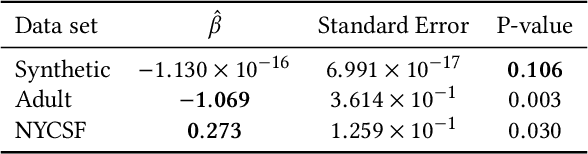
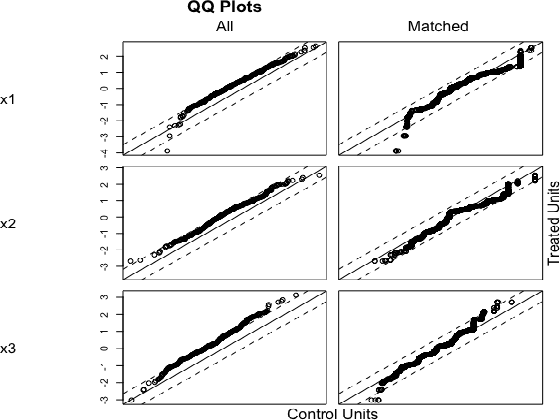

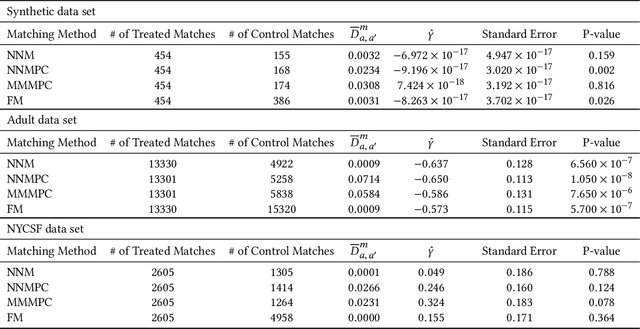
As virtually all aspects of our lives are increasingly impacted by algorithmic decision making systems, it is incumbent upon us as a society to ensure such systems do not become instruments of unfair discrimination on the basis of gender, race, ethnicity, religion, etc. We consider the problem of determining whether the decisions made by such systems are discriminatory, through the lens of causal models. We introduce two definitions of group fairness grounded in causality: fair on average causal effect (FACE), and fair on average causal effect on the treated (FACT). We use the Rubin-Neyman potential outcomes framework for the analysis of cause-effect relationships to robustly estimate FACE and FACT. We demonstrate the effectiveness of our proposed approach on synthetic data. Our analyses of two real-world data sets, the Adult income data set from the UCI repository (with gender as the protected attribute), and the NYC Stop and Frisk data set (with race as the protected attribute), show that the evidence of discrimination obtained by FACE and FACT, or lack thereof, is often in agreement with the findings from other studies. We further show that FACT, being somewhat more nuanced compared to FACE, can yield findings of discrimination that differ from those obtained using FACE.
Improving Image Captioning by Leveraging Knowledge Graphs
Jan 25, 2019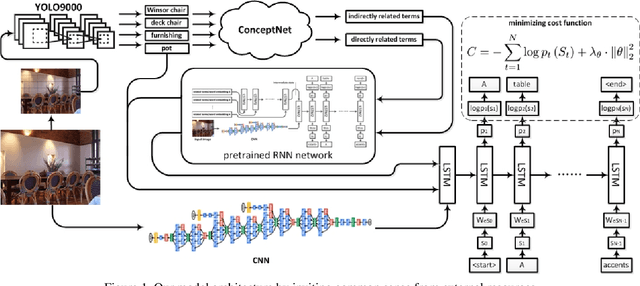
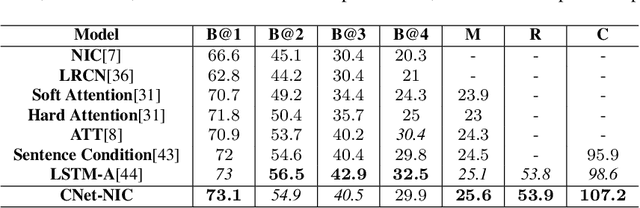
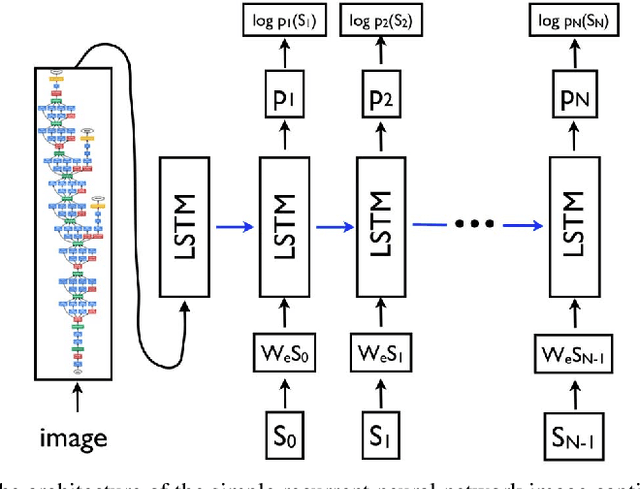
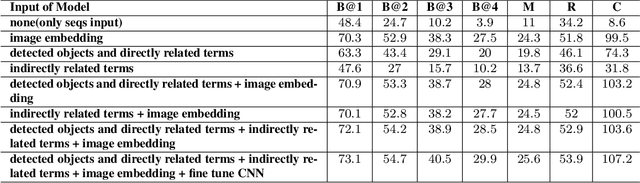
We explore the use of a knowledge graphs, that capture general or commonsense knowledge, to augment the information extracted from images by the state-of-the-art methods for image captioning. The results of our experiments, on several benchmark data sets such as MS COCO, as measured by CIDEr-D, a performance metric for image captioning, show that the variants of the state-of-the-art methods for image captioning that make use of the information extracted from knowledge graphs can substantially outperform those that rely solely on the information extracted from images.
Top-N-Rank: A Scalable List-wise Ranking Method for Recommender Systems
Dec 19, 2018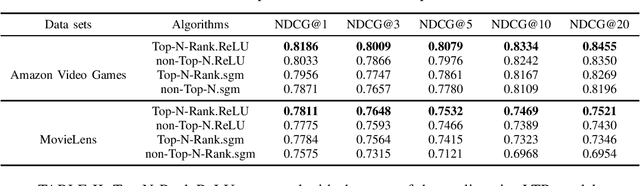
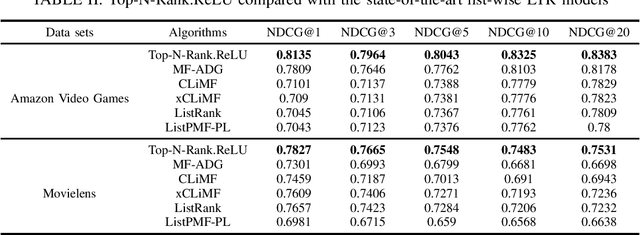
We propose Top-N-Rank, a novel family of list-wise Learning-to-Rank models for reliably recommending the N top-ranked items. The proposed models optimize a variant of the widely used discounted cumulative gain (DCG) objective function which differs from DCG in two important aspects: (i) It limits the evaluation of DCG only on the top N items in the ranked lists, thereby eliminating the impact of low-ranked items on the learned ranking function; and (ii) it incorporates weights that allow the model to leverage multiple types of implicit feedback with differing levels of reliability or trustworthiness. Because the resulting objective function is non-smooth and hence challenging to optimize, we consider two smooth approximations of the objective function, using the traditional sigmoid function and the rectified linear unit (ReLU). We propose a family of learning-to-rank algorithms (Top-N-Rank) that work with any smooth objective function. Then, a more efficient variant, Top-N-Rank.ReLU, is introduced, which effectively exploits the properties of ReLU function to reduce the computational complexity of Top-N-Rank from quadratic to linear in the average number of items rated by users. The results of our experiments using two widely used benchmarks, namely, the MovieLens data set and the Amazon Video Games data set demonstrate that: (i) The `top-N truncation' of the objective function substantially improves the ranking quality of the top N recommendations; (ii) using the ReLU for smoothing the objective function yields significant improvement in both ranking quality as well as runtime as compared to using the sigmoid; and (iii) Top-N-Rank.ReLU substantially outperforms the well-performing list-wise ranking methods in terms of ranking quality.
Multi-View Network Embedding Via Graph Factorization Clustering and Co-Regularized Multi-View Agreement
Nov 08, 2018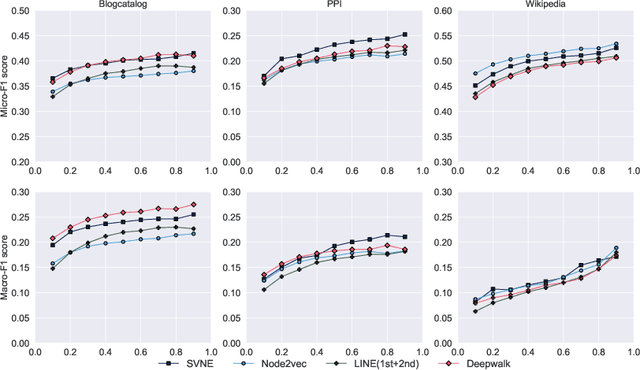
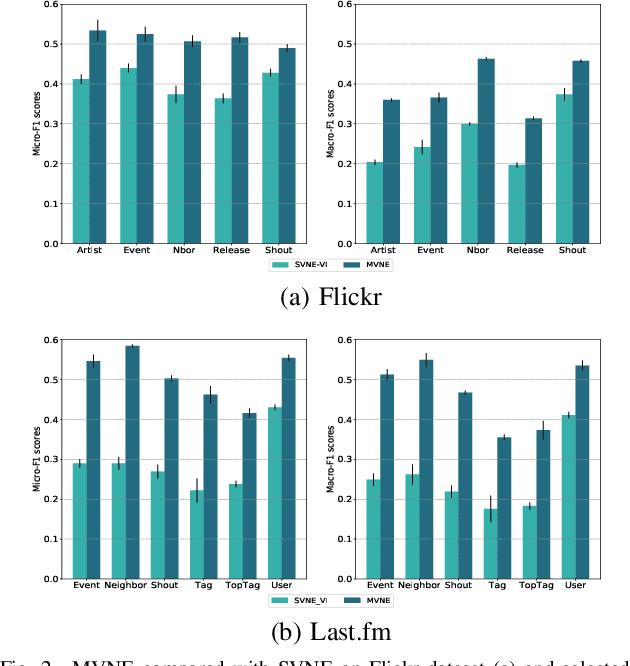
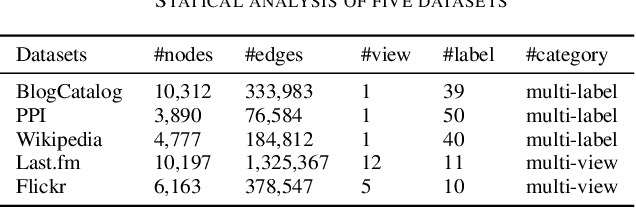
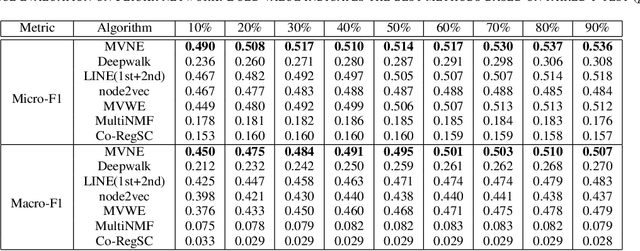
Real-world social networks and digital platforms are comprised of individuals (nodes) that are linked to other individuals or entities through multiple types of relationships (links). Sub-networks of such a network based on each type of link correspond to distinct views of the underlying network. In real-world applications, each node is typically linked to only a small subset of other nodes. Hence, practical approaches to problems such as node labeling have to cope with the resulting sparse networks. While low-dimensional network embeddings offer a promising approach to this problem, most of the current network embedding methods focus primarily on single view networks. We introduce a novel multi-view network embedding (MVNE) algorithm for constructing low-dimensional node embeddings from multi-view networks. MVNE adapts and extends an approach to single view network embedding (SVNE) using graph factorization clustering (GFC) to the multi-view setting using an objective function that maximizes the agreement between views based on both the local and global structure of the underlying multi-view graph. Our experiments with several benchmark real-world single view networks show that GFC-based SVNE yields network embeddings that are competitive with or superior to those produced by the state-of-the-art single view network embedding methods when the embeddings are used for labeling unlabeled nodes in the networks. Our experiments with several multi-view networks show that MVNE substantially outperforms the single view methods on integrated view and the state-of-the-art multi-view methods. We further show that even when the goal is to predict labels of nodes within a single target view, MVNE outperforms its single-view counterpart suggesting that the MVNE is able to extract the information that is useful for labeling nodes in the target view from the all of the views.
Compositional Stochastic Average Gradient for Machine Learning and Related Applications
Sep 07, 2018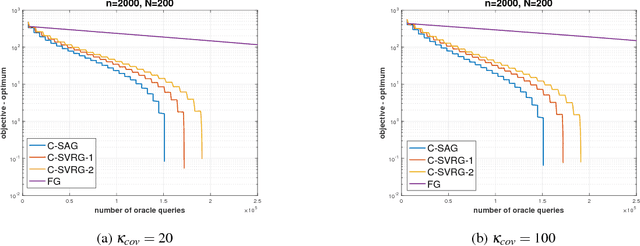
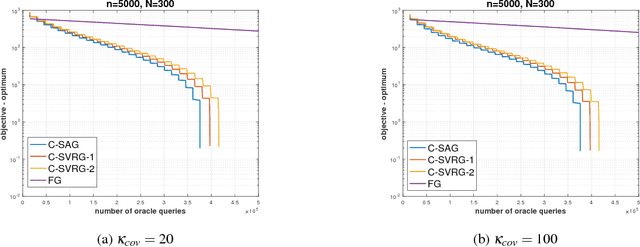
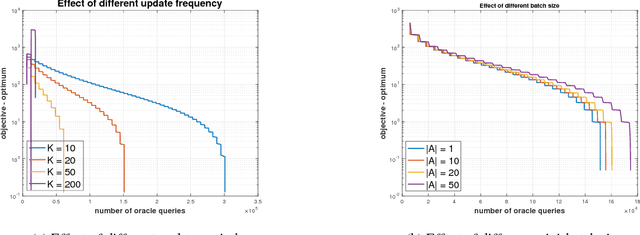
Many machine learning, statistical inference, and portfolio optimization problems require minimization of a composition of expected value functions (CEVF). Of particular interest is the finite-sum versions of such compositional optimization problems (FS-CEVF). Compositional stochastic variance reduced gradient (C-SVRG) methods that combine stochastic compositional gradient descent (SCGD) and stochastic variance reduced gradient descent (SVRG) methods are the state-of-the-art methods for FS-CEVF problems. We introduce compositional stochastic average gradient descent (C-SAG) a novel extension of the stochastic average gradient method (SAG) to minimize composition of finite-sum functions. C-SAG, like SAG, estimates gradient by incorporating memory of previous gradient information. We present theoretical analyses of C-SAG which show that C-SAG, like SAG, and C-SVRG, achieves a linear convergence rate when the objective function is strongly convex; However, C-CAG achieves lower oracle query complexity per iteration than C-SVRG. Finally, we present results of experiments showing that C-SAG converges substantially faster than full gradient (FG), as well as C-SVRG.
Advances in Artificial Intelligence Require Progress Across all of Computer Science
Jul 13, 2017Advances in Artificial Intelligence require progress across all of computer science.
Lifted Representation of Relational Causal Models Revisited: Implications for Reasoning and Structure Learning
Aug 17, 2015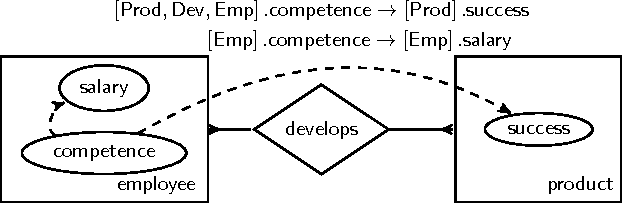
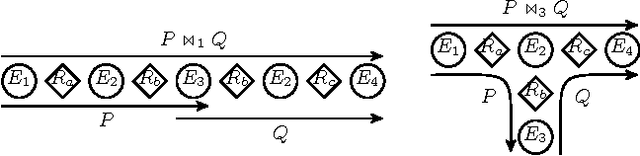
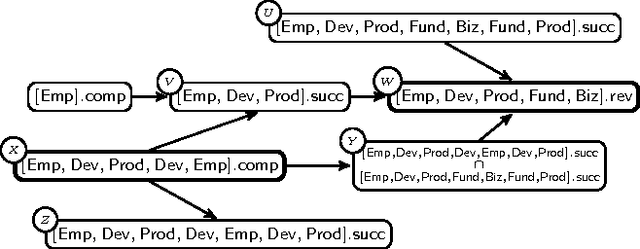
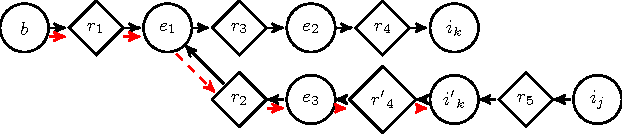
Maier et al. (2010) introduced the relational causal model (RCM) for representing and inferring causal relationships in relational data. A lifted representation, called abstract ground graph (AGG), plays a central role in reasoning with and learning of RCM. The correctness of the algorithm proposed by Maier et al. (2013a) for learning RCM from data relies on the soundness and completeness of AGG for relational d-separation to reduce the learning of an RCM to learning of an AGG. We revisit the definition of AGG and show that AGG, as defined in Maier et al. (2013b), does not correctly abstract all ground graphs. We revise the definition of AGG to ensure that it correctly abstracts all ground graphs. We further show that AGG representation is not complete for relational d-separation, that is, there can exist conditional independence relations in an RCM that are not entailed by AGG. A careful examination of the relationship between the lack of completeness of AGG for relational d-separation and faithfulness conditions suggests that weaker notions of completeness, namely adjacency faithfulness and orientation faithfulness between an RCM and its AGG, can be used to learn an RCM from data.
CRISNER: A Practically Efficient Reasoner for Qualitative Preferences
Jul 30, 2015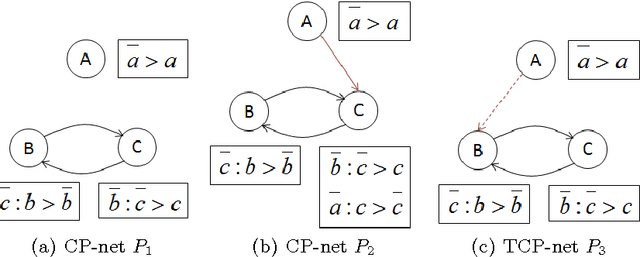
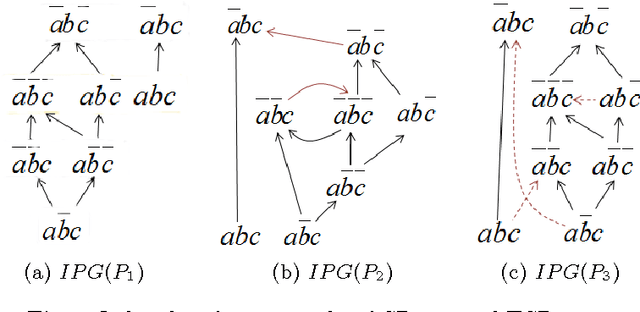


We present CRISNER (Conditional & Relative Importance Statement Network PrEference Reasoner), a tool that provides practically efficient as well as exact reasoning about qualitative preferences in popular ceteris paribus preference languages such as CP-nets, TCP-nets, CP-theories, etc. The tool uses a model checking engine to translate preference specifications and queries into appropriate Kripke models and verifiable properties over them respectively. The distinguishing features of the tool are: (1) exact and provably correct query answering for testing dominance, consistency with respect to a preference specification, and testing equivalence and subsumption of two sets of preferences; (2) automatic generation of proofs evidencing the correctness of answer produced by CRISNER to any of the above queries; (3) XML inputs and outputs that make it portable and pluggable into other applications. We also describe the extensible architecture of CRISNER, which can be extended to new reference formalisms based on ceteris paribus semantics that may be developed in the future.