 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport the Floor: A Training-Free Conformal Interval Is a Mandatory Baseline for Probabilistic Time-Series Forecasting
Jun 08, 2026Probabilistic forecasters are increasingly learned, yet the baselines they are compared against are often weak or omitted. We show that the simplest possible conformal interval - a last-value point forecast wrapped in a finite-sample split-conformal residual quantile, with no parameters and no training - is a far stronger baseline than its near-total absence from recent learned-forecasting and conformal-time-series comparisons would suggest. In one-step-ahead online forecasting across 2,217 real series from nine public sources (Monash, LOTSA, the LTSF traffic/electricity/weather suites, METR-LA, BOOM, nips/probts), this ConformalNaive interval decisively beats the naive value-quantile baselines, the entire NPTS family (NPTS 73%, SeasonalNPTS 64% of series), and the published Conformal Seasonal Pools (CSP) method (71% of series, bootstrap 95% CI [69,73], paired Wilcoxon p approx 7.6e-135); it is on par with the simpler learned conformal predictors (RCI, quantile regression; median relative Winkler within 2%) and is beaten only by the adaptive-online and ensemble methods (SPCI, ACI, AgACI), which track distribution shift and lead by 9-33% relative Winkler. It is also better calibrated than a trained neural forecaster: on the six datasets that introduced DeepNPTS, the trivial floors cover the truth 84-85% of the time at a nominal 95%, versus DeepNPTS's 66%. At multi-step seasonal horizons the picture inverts: the random-walk floor is the weakest method and the seasonal pool (CSP) wins - a boundary we map. Finally we give ConformalNaive+, a one-line, training-free, horizon-adaptive selector that attains the better of two complementary floors at every horizon with restored coverage. We argue the matching conformal naive floor must be a mandatory baseline whenever a learned probabilistic forecaster claims gains.
Training-Free Probabilistic Time-Series Forecasting with Conformal Seasonal Pools
May 05, 2026We propose Conformal Seasonal Pools (CSP), a training-free probabilistic time-series forecaster that mixes same-season empirical draws with signed residual draws around a seasonal naive forecast. In an audited rolling-origin benchmark on the six time-series datasets where DeepNPTS was originally evaluated (electricity, exchange_rate, solar_energy, taxi, traffic, wikipedia), CSP-Adaptive significantly outperforms DeepNPTS on every metric we report -- CRPS (per-window paired Wilcoxon $p \approx 4 \times 10^{-10}$), normalized mean quantile loss ($p \approx 7 \times 10^{-10}$), and empirical 95% coverage ($p \approx 8 \times 10^{-45}$, mean 0.89 vs 0.66) -- while running over 500x faster on CPU. Coverage is the most decision-critical of these: a 0.95 nominal interval that contains the truth in only ~66% of cases fails the basic calibration desideratum and would not survive deployment in safety- or decision-critical settings. The failure mode is also more severe than aggregate coverage suggests: in the worst 10% of windows, DeepNPTS's prediction interval covers none of the H forecast horizons -- the entire multi-step trajectory misses the truth at every step simultaneously. This poses serious risk in safety- and decision-critical applications such as healthcare, finance, energy operations, and autonomous systems, where prediction intervals that systematically miss the truth across the entire planning horizon translate directly into misclassified patients, regulatory capital failures, grid imbalances, and safety-case violations. CSP achieves all of this with no learned parameters and no training. We argue training-free conformal samplers should be mandatory baselines when evaluating learned non-parametric forecasters.
The Manokhin Probability Matrix: A Diagnostic Framework for Classifier Probability Quality
May 05, 2026The Brier score conflates two distinct properties of probabilistic predictions: reliability (calibration error) and resolution (discriminatory power). We introduce the Manokhin Probability Matrix, a BCG-style two-dimensional diagnostic framework that separates them. Classifiers are placed on a 2x2 grid by Spiegelhalter Z-statistic and AUC-ROC expected rank, then assigned to one of four archetypes: Eagle (good on both axes), Bull (strong discrimination, poor calibration), Sloth (well-calibrated, weak discriminator), and Mole (poor on both). Each archetype carries a distinct prescription. We populate the matrix from a large-scale empirical study spanning 21 classifiers, 5 post-hoc calibrators, and 30 real-world binary classification tasks from the TabArena-v0.1 suite. The assignment is unambiguous. CatBoost, TabICL, EBM, TabPFN, GBC, and Random Forest are Eagles. XGBoost, LightGBM, and HGB are Bulls; Venn-Abers calibration cuts log-loss by 6.5 to 12.6% on Bulls but degrades Eagles by 2.1%. SVM, LR, LDA, and the empirical base-rate predictor are Sloths. MLP, KNN, Naive Bayes, and ExtraTrees are Moles. A theoretical asymmetry follows: no order-preserving post-hoc calibrator can add discriminatory power (Proposition 1), so calibration is the fixable part and discrimination is the hard part. The practical rule is direct: do not optimise aggregate Brier score without first decomposing it; optimise discrimination first, then fix calibration post-hoc. Code and raw experimental data are available at https://github.com/valeman/classifier_calibration.
Classifier Calibration at Scale: An Empirical Study of Model-Agnostic Post-Hoc Methods
Jan 19, 2026We study model-agnostic post-hoc calibration methods intended to improve probabilistic predictions in supervised binary classification on real i.i.d. tabular data, with particular emphasis on conformal and Venn-based approaches that provide distribution-free validity guarantees under exchangeability. We benchmark 21 widely used classifiers, including linear models, SVMs, tree ensembles (CatBoost, XGBoost, LightGBM), and modern tabular neural and foundation models, on binary tasks from the TabArena-v0.1 suite using randomized, stratified five-fold cross-validation with a held-out test fold. Five calibrators; Isotonic regression, Platt scaling, Beta calibration, Venn-Abers predictors, and Pearsonify are trained on a separate calibration split and applied to test predictions. Calibration is evaluated using proper scoring rules (log-loss and Brier score) and diagnostic measures (Spiegelhalter's Z, ECE, and ECI), alongside discrimination (AUC-ROC) and standard classification metrics. Across tasks and architectures, Venn-Abers predictors achieve the largest average reductions in log-loss, followed closely by Beta calibration, while Platt scaling exhibits weaker and less consistent effects. Beta calibration improves log-loss most frequently across tasks, whereas Venn-Abers displays fewer instances of extreme degradation and slightly more instances of extreme improvement. Importantly, we find that commonly used calibration procedures, most notably Platt scaling and isotonic regression, can systematically degrade proper scoring performance for strong modern tabular models. Overall classification performance is often preserved, but calibration effects vary substantially across datasets and architectures, and no method dominates uniformly. In expectation, all methods except Pearsonify slightly increase accuracy, but the effect is marginal, with the largest expected gain about 0.008%.
Computationally efficient versions of conformal predictive distributions
Nov 03, 2019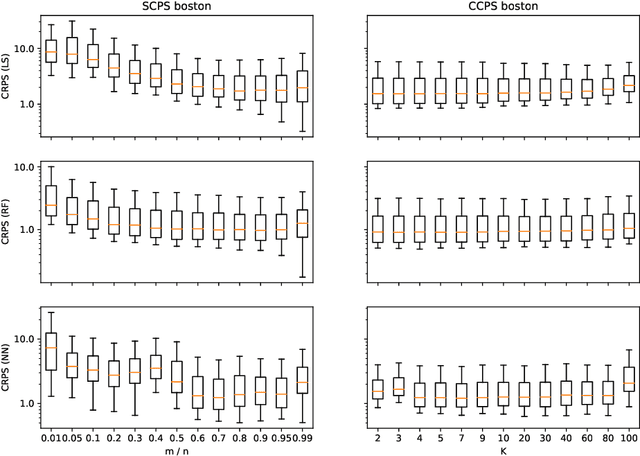

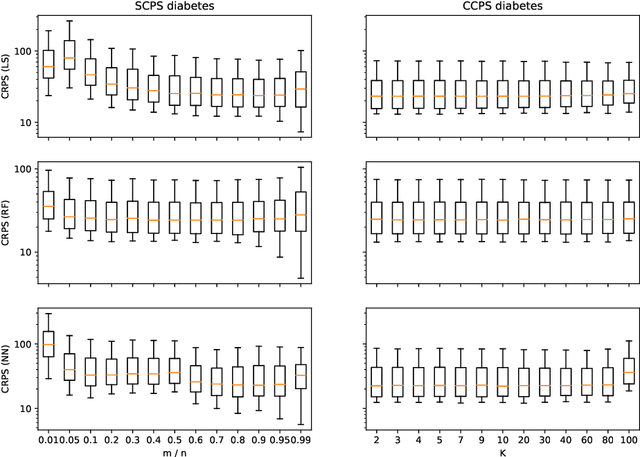
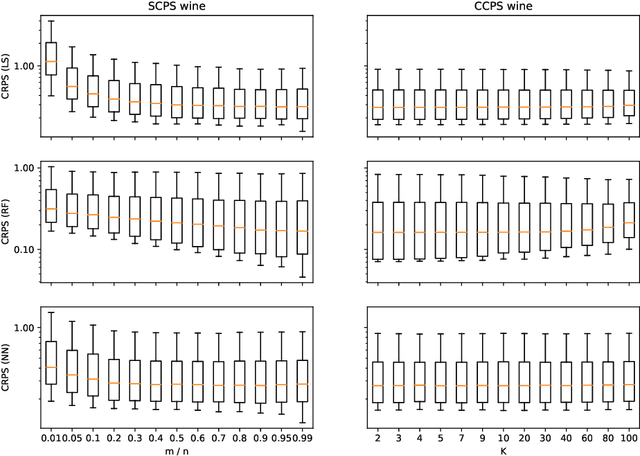
Conformal predictive systems are a recent modification of conformal predictors that output, in regression problems, probability distributions for labels of test observations rather than set predictions. The extra information provided by conformal predictive systems may be useful, e.g., in decision making problems. Conformal predictive systems inherit the relative computational inefficiency of conformal predictors. In this paper we discuss two computationally efficient versions of conformal predictive systems, which we call split conformal predictive systems and cross-conformal predictive systems. The main advantage of split conformal predictive systems is their guaranteed validity, whereas for cross-conformal predictive systems validity only holds empirically and in the absence of excessive randomization. The main advantage of cross-conformal predictive systems is their greater predictive efficiency.
Conformal predictive distributions with kernels
Oct 24, 2017

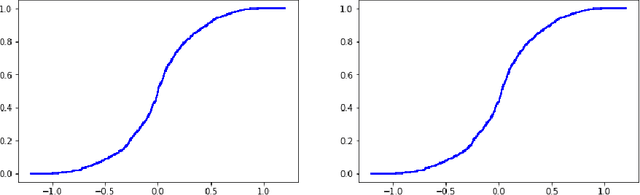
This paper reviews the checkered history of predictive distributions in statistics and discusses two developments, one from recent literature and the other new. The first development is bringing predictive distributions into machine learning, whose early development was so deeply influenced by two remarkable groups at the Institute of Automation and Remote Control. The second development is combining predictive distributions with kernel methods, which were originated by one of those groups, including Emmanuel Braverman.