 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Intangible: Surveying Automatic High-Level Visual Understanding from Still Images
Aug 21, 2023The field of Computer Vision (CV) was born with the single grand goal of complete image understanding: providing a complete semantic interpretation of an input image. What exactly this goal entails is not immediately straightforward, but theoretical hierarchies of visual understanding point towards a top level of full semantics, within which sits the most complex and subjective information humans can detect from visual data. In particular, non-concrete concepts including emotions, social values and ideologies seem to be protagonists of this "high-level" visual semantic understanding. While such "abstract concepts" are critical tools for image management and retrieval, their automatic recognition is still a challenge, exactly because they rest at the top of the "semantic pyramid": the well-known semantic gap problem is worsened given their lack of unique perceptual referents, and their reliance on more unspecific features than concrete concepts. Given that there seems to be very scarce explicit work within CV on the task of abstract social concept (ASC) detection, and that many recent works seem to discuss similar non-concrete entities by using different terminology, in this survey we provide a systematic review of CV work that explicitly or implicitly approaches the problem of abstract (specifically social) concept detection from still images. Specifically, this survey performs and provides: (1) A study and clustering of high level visual understanding semantic elements from a multidisciplinary perspective (computer science, visual studies, and cognitive perspectives); (2) A study and clustering of high level visual understanding computer vision tasks dealing with the identified semantic elements, so as to identify current CV work that implicitly deals with AC detection.
The Music Annotation Pattern
Mar 30, 2023The annotation of music content is a complex process to represent due to its inherent multifaceted, subjectivity, and interdisciplinary nature. Numerous systems and conventions for annotating music have been developed as independent standards over the past decades. Little has been done to make them interoperable, which jeopardises cross-corpora studies as it requires users to familiarise with a multitude of conventions. Most of these systems lack the semantic expressiveness needed to represent the complexity of the musical language and cannot model multi-modal annotations originating from audio and symbolic sources. In this article, we introduce the Music Annotation Pattern, an Ontology Design Pattern (ODP) to homogenise different annotation systems and to represent several types of musical objects (e.g. chords, patterns, structures). This ODP preserves the semantics of the object's content at different levels and temporal granularity. Moreover, our ODP accounts for multi-modality upfront, to describe annotations derived from different sources, and it is the first to enable the integration of music datasets at a large scale.
Pitchclass2vec: Symbolic Music Structure Segmentation with Chord Embeddings
Mar 24, 2023



Structure perception is a fundamental aspect of music cognition in humans. Historically, the hierarchical organization of music into structures served as a narrative device for conveying meaning, creating expectancy, and evoking emotions in the listener. Thereby, musical structures play an essential role in music composition, as they shape the musical discourse through which the composer organises his ideas. In this paper, we present a novel music segmentation method, pitchclass2vec, based on symbolic chord annotations, which are embedded into continuous vector representations using both natural language processing techniques and custom-made encodings. Our algorithm is based on long-short term memory (LSTM) neural network and outperforms the state-of-the-art techniques based on symbolic chord annotations in the field.
Automatic Modeling of Social Concepts Evoked by Art Images as Multimodal Frames
Oct 14, 2021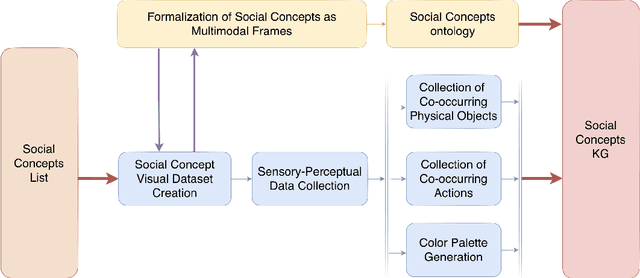
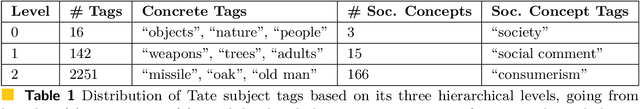
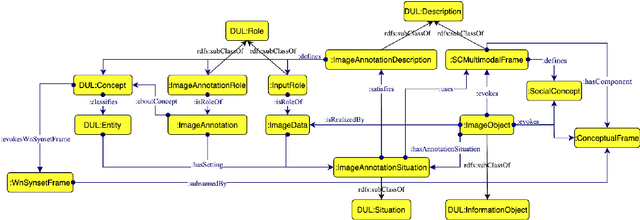
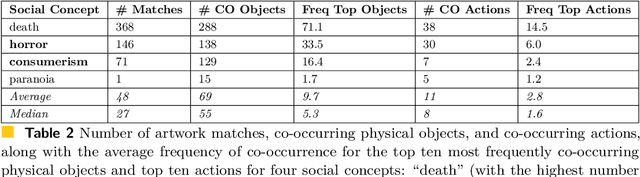
Social concepts referring to non-physical objects--such as revolution, violence, or friendship--are powerful tools to describe, index, and query the content of visual data, including ever-growing collections of art images from the Cultural Heritage (CH) field. While much progress has been made towards complete image understanding in computer vision, automatic detection of social concepts evoked by images is still a challenge. This is partly due to the well-known semantic gap problem, worsened for social concepts given their lack of unique physical features, and reliance on more unspecific features than concrete concepts. In this paper, we propose the translation of recent cognitive theories about social concept representation into a software approach to represent them as multimodal frames, by integrating multisensory data. Our method focuses on the extraction, analysis, and integration of multimodal features from visual art material tagged with the concepts of interest. We define a conceptual model and present a novel ontology for formally representing social concepts as multimodal frames. Taking the Tate Gallery's collection as an empirical basis, we experiment our method on a corpus of art images to provide a proof of concept of its potential. We discuss further directions of research, and provide all software, data sources, and results.
Pattern-based Visualization of Knowledge Graphs
Jun 24, 2021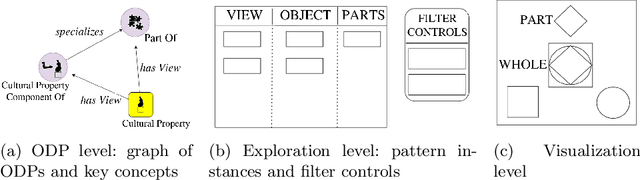
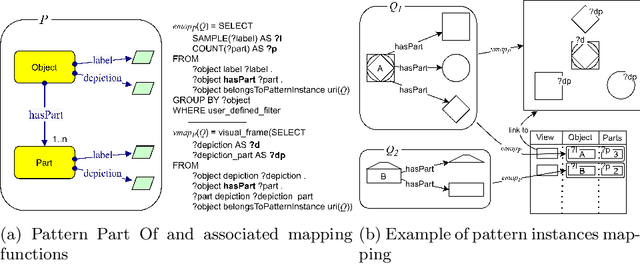

We present a novel approach to knowledge graph visualization based on ontology design patterns. This approach relies on OPLa (Ontology Pattern Language) annotations and on a catalogue of visual frames, which are associated with foundational ontology design patterns. We demonstrate that this approach significantly reduces the cognitive load required to users for visualizing and interpreting a knowledge graph and guides the user in exploring it through meaningful thematic paths provided by ontology patterns.
Extraction of common conceptual components from multiple ontologies
Jun 24, 2021
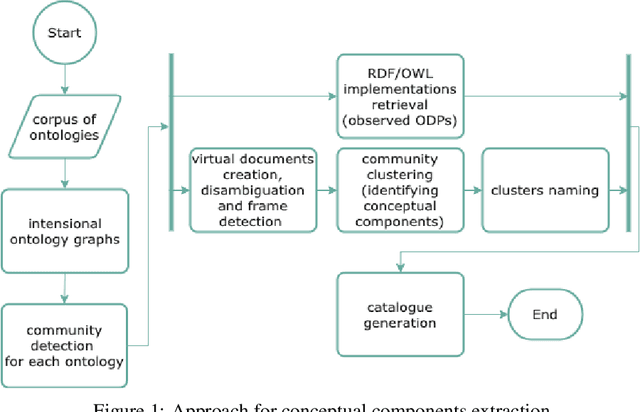
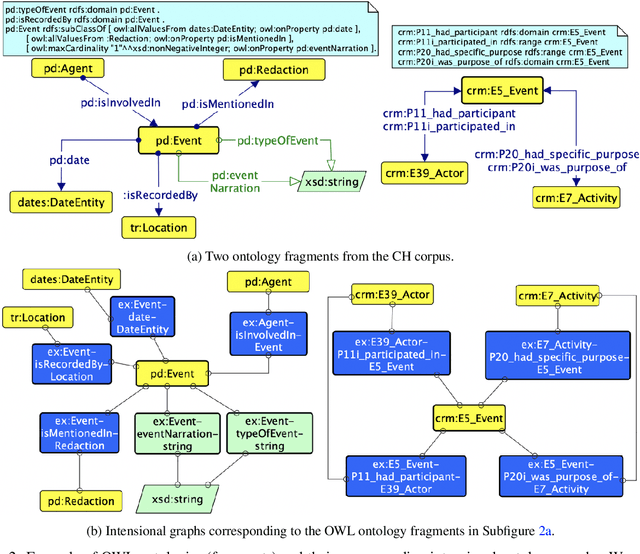

We describe a novel method for identifying and extracting conceptual components from domain ontologies, which are used to understand and compare them. The method is applied to two corpora of ontologies in the Cultural Heritage and Conference domain, respectively. The results, which show good quality, are evaluated by manual inspection and by correlation with datasets and tool performance from the ontology alignment evaluation initiative.
An Ontology Design Pattern for representing Recurrent Situations
Jan 01, 2021
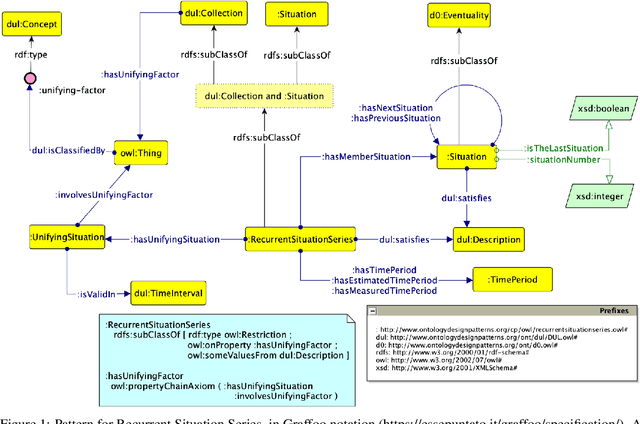
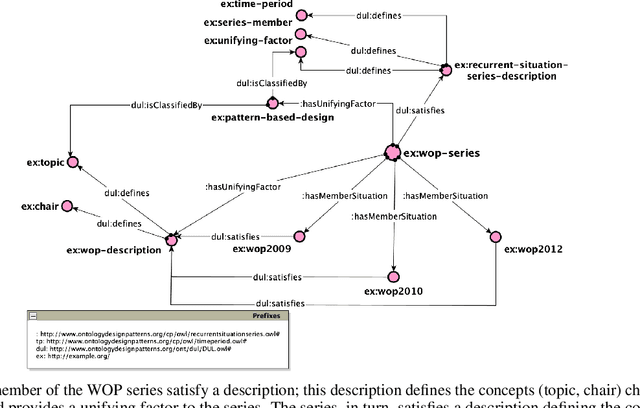
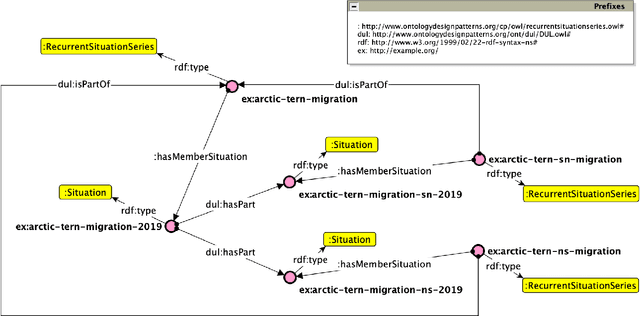
In this paper, we present an Ontology Design Pattern for representing situations that recur at regular periods and share some invariant factors, which unify them conceptually: we refer to this set of recurring situations as recurrent situation series. The proposed pattern appears to be foundational, since it can be generalised for modelling the top-level domain-independent concept of recurrence, which is strictly associated with invariance. The pattern reuses other foundational patterns such as Collection, Description and Situation, Classification, Sequence. Indeed, a recurrent situation series is formalised as both a collection of situations occurring regularly over time and unified according to some properties that are common to all the members, and a situation itself, which provides a relational context to its members that satisfy a reference description. Besides including some exemplifying instances of this pattern, we show how it has been implemented and specialised to model recurrent cultural events and ceremonies in ArCo, the Knowledge Graph of Italian cultural heritage.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020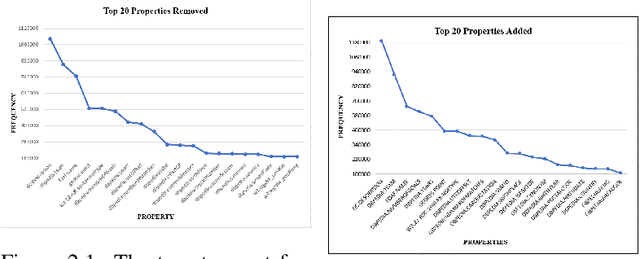
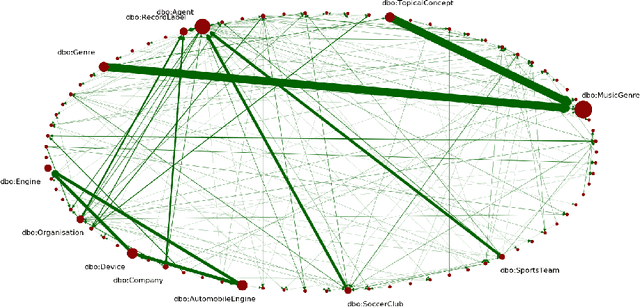

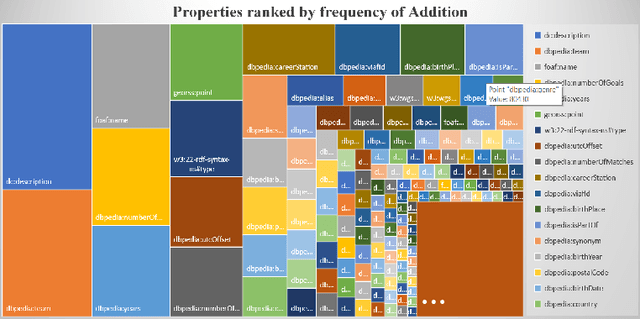
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
The Landscape of Ontology Reuse Approaches
Nov 25, 2020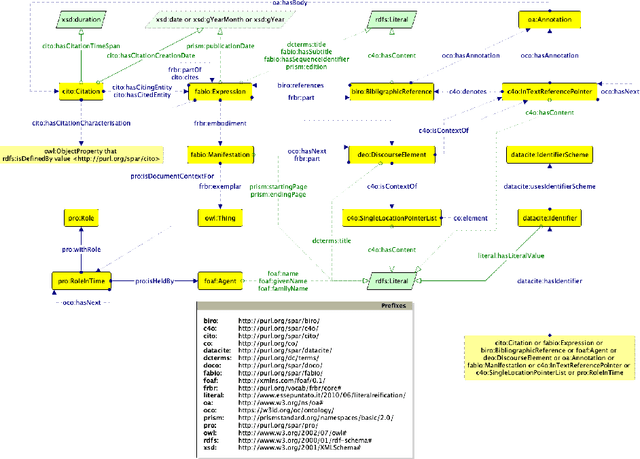
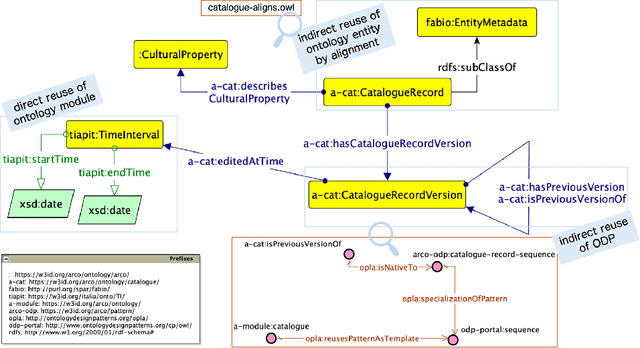
Ontology reuse aims to foster interoperability and facilitate knowledge reuse. Several approaches are typically evaluated by ontology engineers when bootstrapping a new project. However, current practices are often motivated by subjective, case-by-case decisions, which hamper the definition of a recommended behaviour. In this chapter we argue that to date there are no effective solutions for supporting developers' decision-making process when deciding on an ontology reuse strategy. The objective is twofold: (i) to survey current approaches to ontology reuse, presenting motivations, strategies, benefits and limits, and (ii) to analyse two representative approaches and discuss their merits.
A Reference Software Architecture for Social Robots
Jul 09, 2020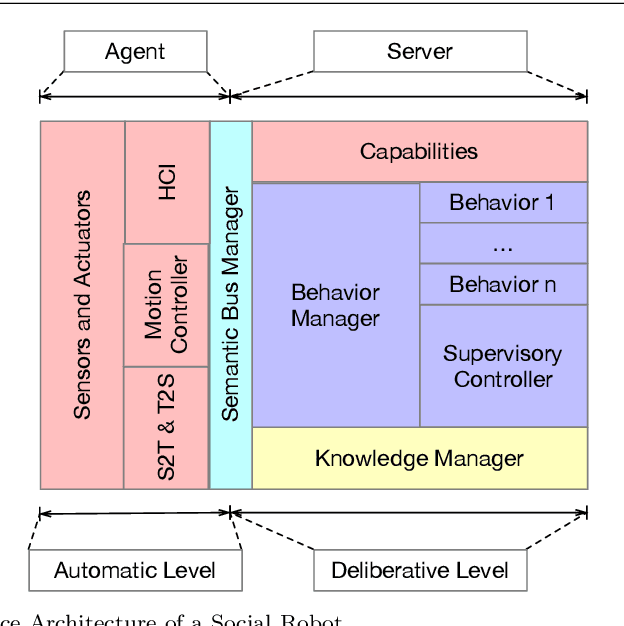
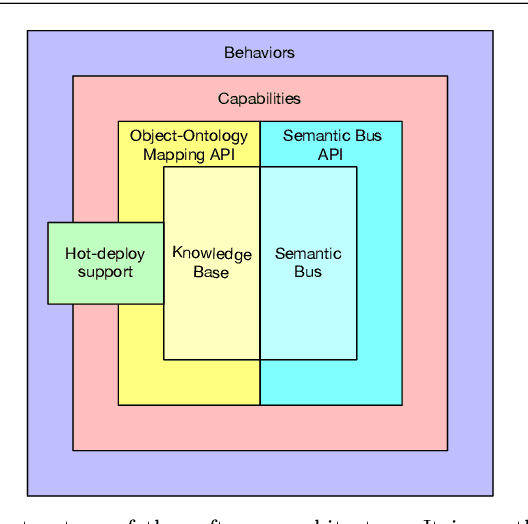
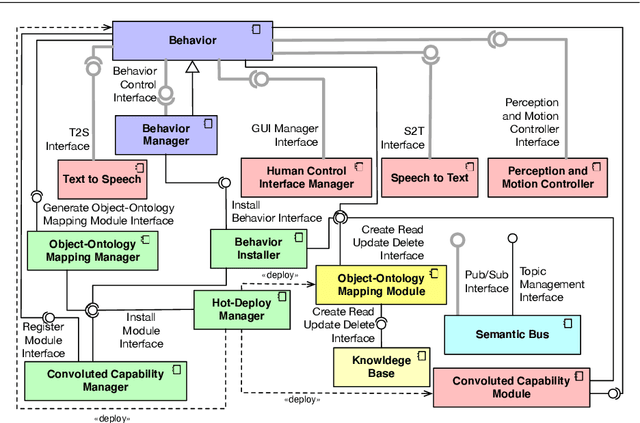
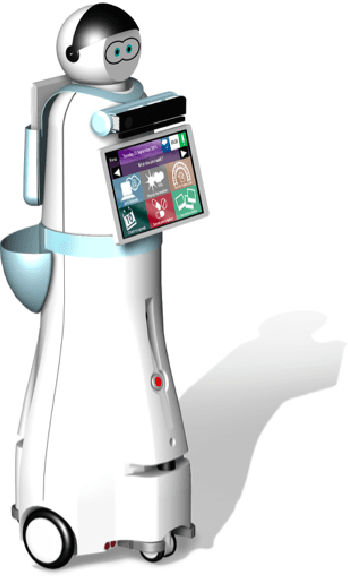
Social Robotics poses tough challenges to software designers who are required to take care of difficult architectural drivers like acceptability, trust of robots as well as to guarantee that robots establish a personalised interaction with their users. Moreover, in this context recurrent software design issues such as ensuring interoperability, improving reusability and customizability of software components also arise. Designing and implementing social robotic software architectures is a time-intensive activity requiring multi-disciplinary expertise: this makes difficult to rapidly develop, customise, and personalise robotic solutions. These challenges may be mitigated at design time by choosing certain architectural styles, implementing specific architectural patterns and using particular technologies. Leveraging on our experience in the MARIO project, in this paper we propose a series of principles that social robots may benefit from. These principles lay also the foundations for the design of a reference software architecture for Social Robots. The ultimate goal of this work is to establish a common ground based on a reference software architecture to allow to easily reuse robotic software components in order to rapidly develop, implement, and personalise Social Robots.