 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQini-based Uplift Regression
Nov 28, 2019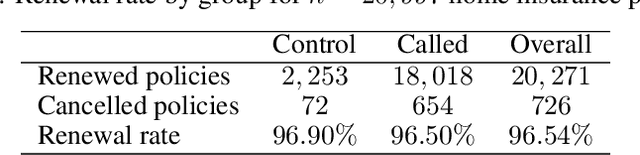
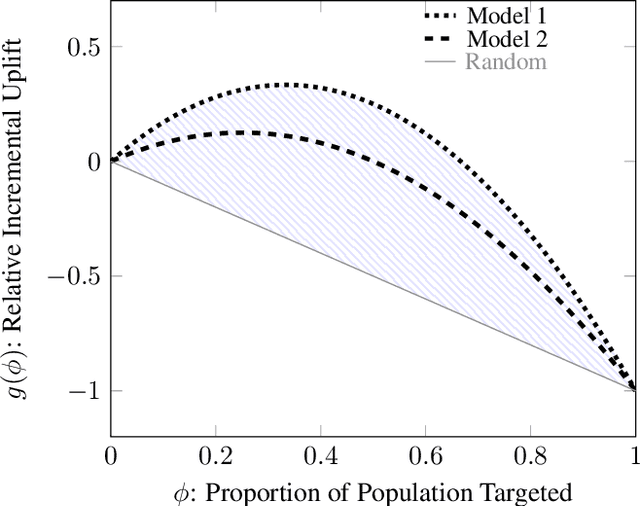
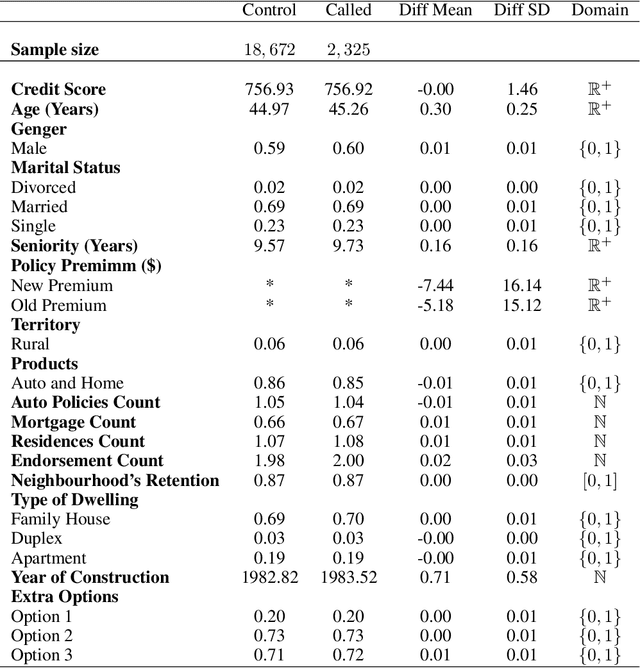
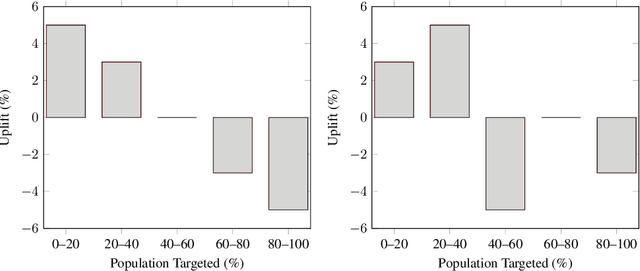
Uplift models provide a solution to the problem of isolating the marketing effect of a campaign. For customer churn reduction, uplift models are used to identify the customers who are likely to respond positively to a retention activity only if targeted, and to avoid wasting resources on customers that are very likely to switch to another company. We introduce a Qini-based uplift regression model to analyze a large insurance company's retention marketing campaign. Our approach is based on logistic regression models. We show that a Qini-optimized uplift model acts as a regularizing factor for uplift, much as a penalized likelihood model does for regression. This results in interpretable parsimonious models with few relevant explanatory variables. Our results show that performing Qini-based variable selection significantly improves the uplift models performance.
How Does Batch Normalization Help Binary Training?
Oct 10, 2019

Binary Neural Networks (BNNs) are difficult to train, and suffer from drop of accuracy. It appears in practice that BNNs fail to train in the absence of Batch Normalization (BatchNorm) layer. We find the main role of BatchNorm is to avoid exploding gradients in the case of BNNs. This finding suggests that the common initialization methods developed for full-precision networks are irrelevant to BNNs. We build a theoretical study on the role of BatchNorm in binary training, backed up by numerical experiments.
Random Bias Initialization Improving Binary Neural Network Training
Sep 30, 2019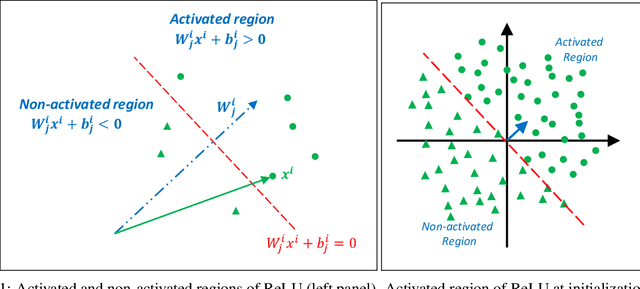
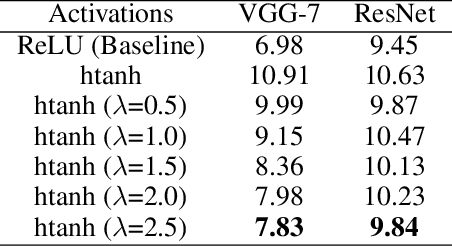
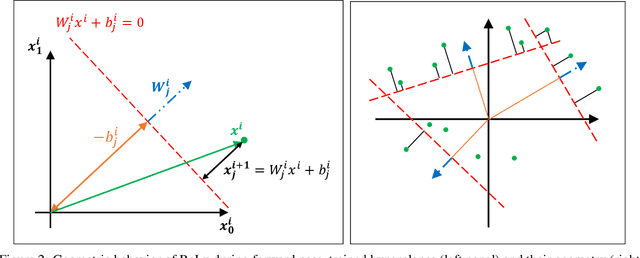
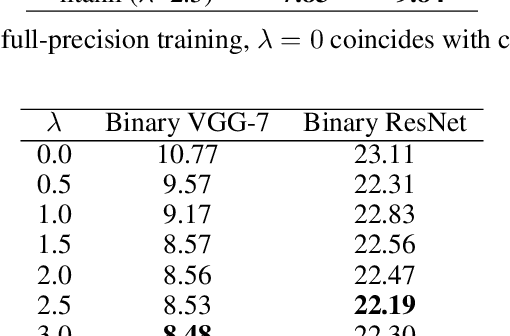
Edge intelligence especially binary neural network (BNN) has attracted considerable attention of the artificial intelligence community recently. BNNs significantly reduce the computational cost, model size, and memory footprint. However, there is still a performance gap between the successful full-precision neural network with ReLU activation and BNNs. We argue that the accuracy drop of BNNs is due to their geometry. We analyze the behaviour of the full-precision neural network with ReLU activation and compare it with its binarized counterpart. This comparison suggests random bias initialization as a remedy to activation saturation in full-precision networks and leads us towards an improved BNN training. Our numerical experiments confirm our geometric intuition.
Smart Ternary Quantization
Sep 26, 2019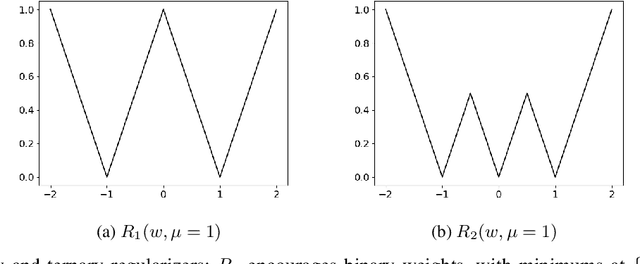
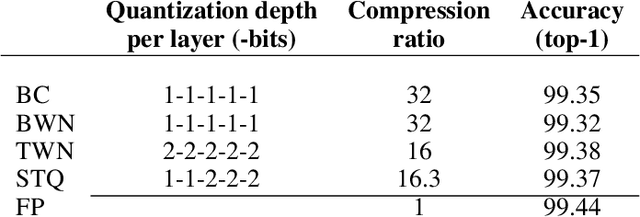
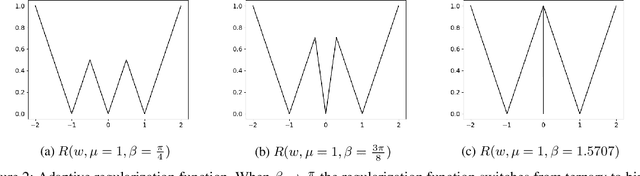

Neural network models are resource hungry. Low bit quantization such as binary and ternary quantization is a common approach to alleviate this resource requirements. Ternary quantization provides a more flexible model and often beats binary quantization in terms of accuracy, but doubles memory and increases computation cost. Mixed quantization depth models, on another hand, allows a trade-off between accuracy and memory footprint. In such models, quantization depth is often chosen manually (which is a tiring task), or is tuned using a separate optimization routine (which requires training a quantized network multiple times). Here, we propose Smart Ternary Quantization (STQ) in which we modify the quantization depth directly through an adaptive regularization function, so that we train a model only once. This method jumps between binary and ternary quantization while training. We show its application on image classification.
Differentiable Mask Pruning for Neural Networks
Sep 10, 2019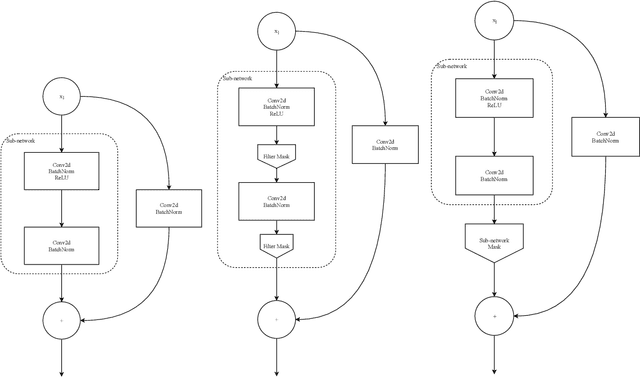
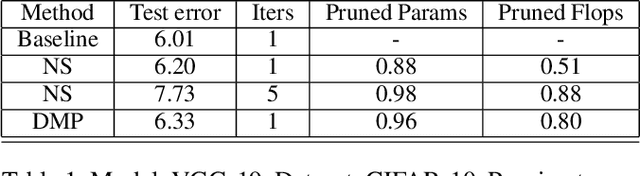
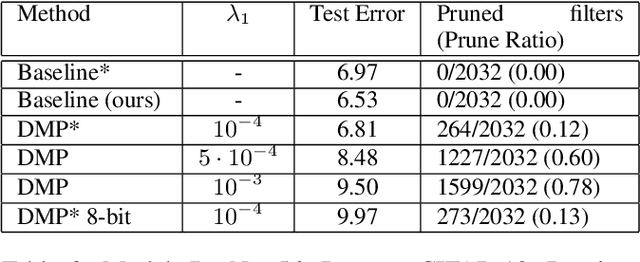
Pruning of neural networks is one of the well-known and promising model simplification techniques. Most neural network models are large and require expensive computations to predict new instances. It is imperative to compress the network to deploy models on low resource devices. Most compression techniques, especially pruning have been focusing on computer vision and convolution neural networks. Existing techniques are complex and require multi-stage optimization and fine-tuning to recover the state-of-the-art accuracy. We introduce a \emph{Differentiable Mask Pruning} (DMP), that simplifies the network while training, and can be used to induce sparsity on weight, filter, node or sub-network. Our method achieves competitive results on standard vision and NLP benchmarks, and is easy to integrate within the deep learning toolbox. DMP bridges the gap between neural model compression and differentiable neural architecture search.
Active Learning for High-Dimensional Binary Features
Feb 05, 2019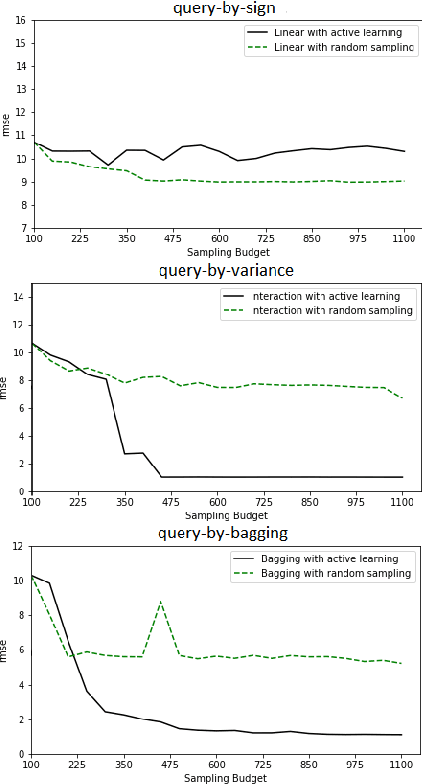
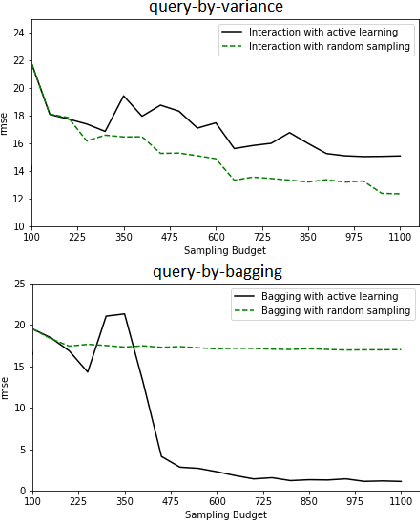
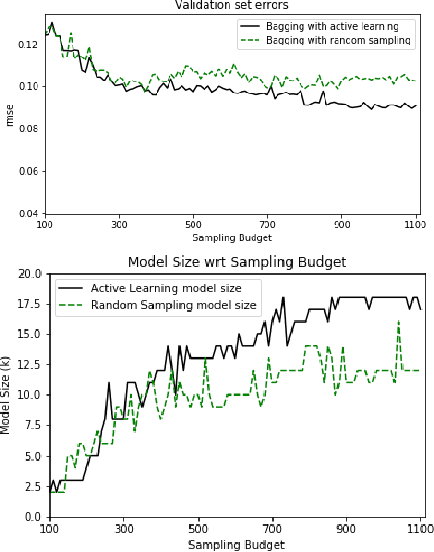
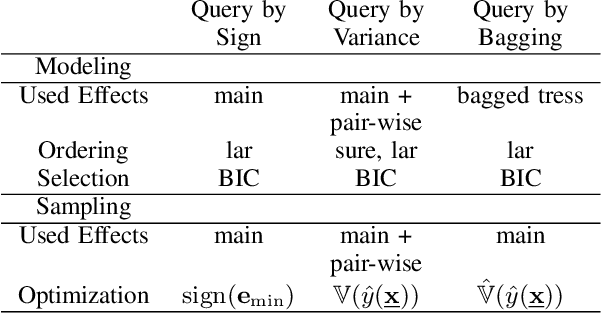
Erbium-doped fiber amplifier (EDFA) is an optical amplifier/repeater device used to boost the intensity of optical signals being carried through a fiber optic communication system. A highly accurate EDFA model is important because of its crucial role in optical network management and optimization. The input channels of an EDFA device are treated as either on or off, hence the input features are binary. Labeled training data is very expensive to collect for EDFA devices, therefore we devise an active learning strategy suitable for binary variables to overcome this issue. We propose to take advantage of sparse linear models to simplify the predictive model. This approach simultaneously improves prediction and accelerates active learning query generation. We show the performance of our proposed active learning strategies on simulated data and real EDFA data.
Activation Adaptation in Neural Networks
Jan 28, 2019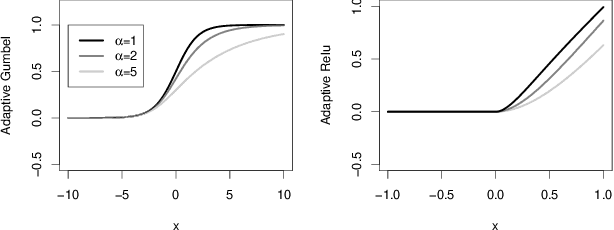
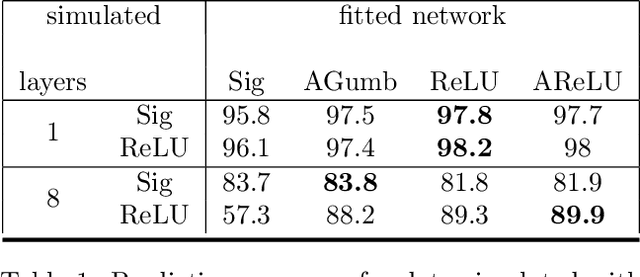
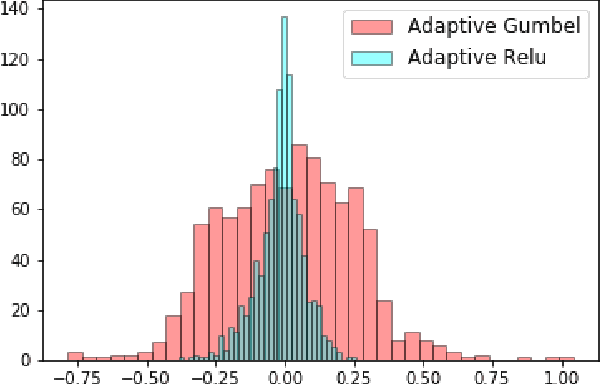
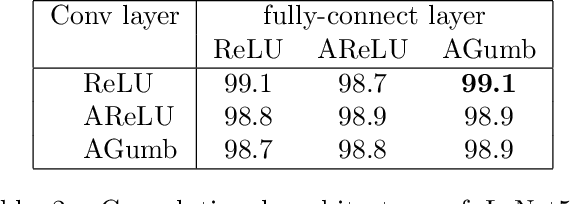
Many neural network architectures rely on the choice of the activation function for each hidden layer. Given the activation function, the neural network is trained over the bias and the weight parameters. The bias catches the center of the activation, and the weights capture the scale. Here we propose to train the network over a shape parameter as well. This view allows each neuron to tune its own activation function and adapt the neuron curvature towards a better prediction. This modification only adds one further equation to the back-propagation for each neuron. Re-formalizing activation functions as CDF generalizes the class of activation function extensively. We aimed at generalizing an extensive class of activation functions to study: i) skewness and ii) smoothness of activation functions. Here we introduce adaptive Gumbel activation function as a bridge between Gumbel and sigmoid. A similar approach is used to invent a smooth version of ReLU. Our comparison with common activation functions suggests different data representation especially in early neural network layers. This adaptation also provides prediction improvement.
Foothill: A Quasiconvex Regularization Function
Jan 18, 2019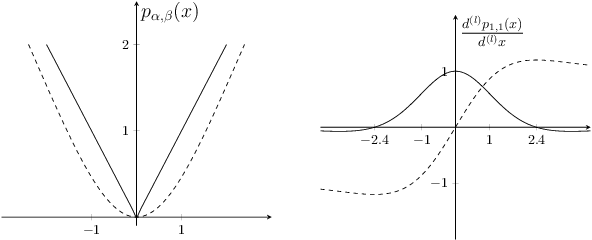

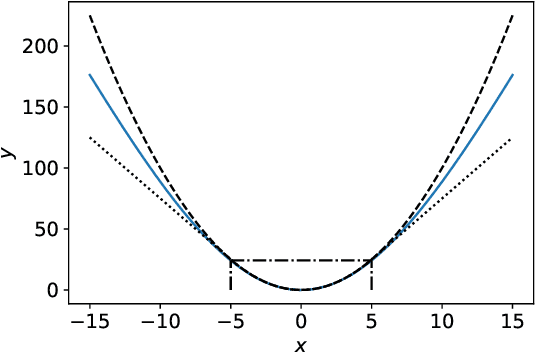
Deep neural networks (DNNs) have demonstrated success for many supervised learning tasks, ranging from voice recognition, object detection, to image classification. However, their increasing complexity yields poor generalization error. Adding noise to the input data or using a concrete regularization function helps to improve generalization. Here we introduce foothill function, an infinitely differentiable quasiconvex function. This regularizer is flexible enough to deform towards $L_1$ and $L_2$ penalties. Foothill can be used as a loss, as a regularizer, or as a binary quantizer.
BNN+: Improved Binary Network Training
Dec 31, 2018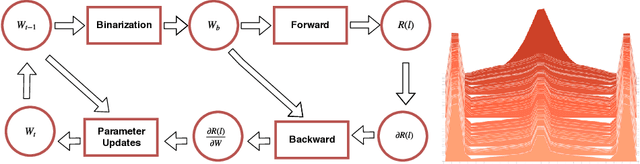
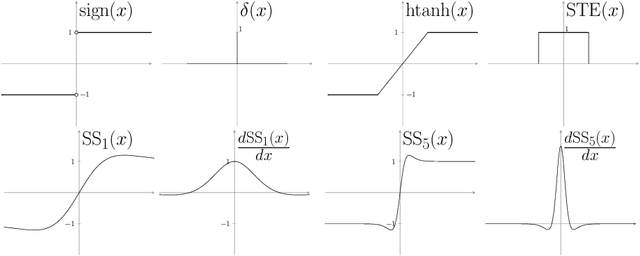
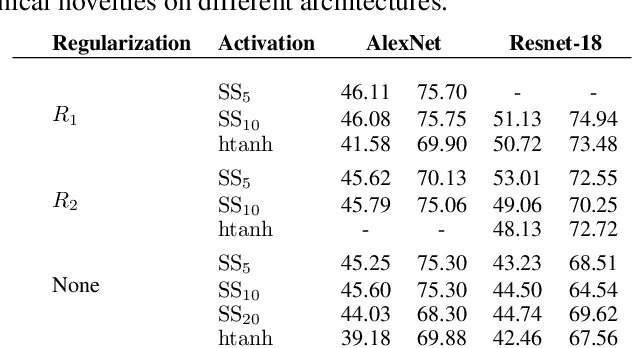
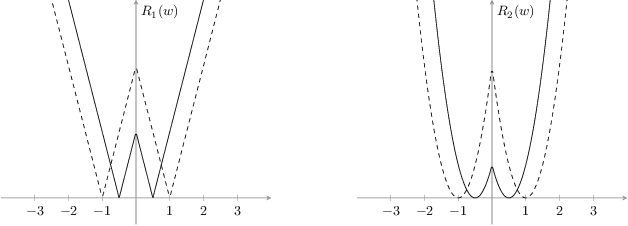
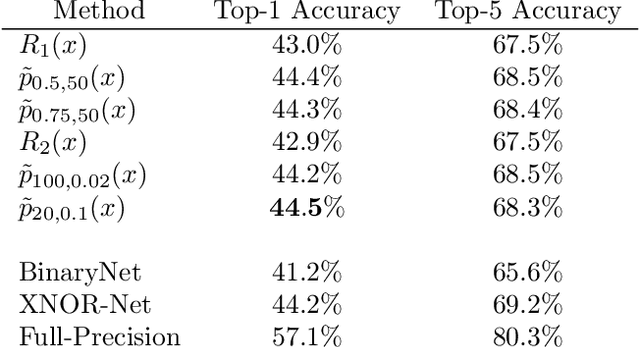
Deep neural networks (DNN) are widely used in many applications. However, their deployment on edge devices has been difficult because they are resource hungry. Binary neural networks (BNN) help to alleviate the prohibitive resource requirements of DNN, where both activations and weights are limited to $1$-bit. We propose an improved binary training method (BNN+), by introducing a regularization function that encourages training weights around binary values. In addition to this, to enhance model performance we add trainable scaling factors to our regularization functions. Furthermore, we use an improved approximation of the derivative of the sign activation function in the backward computation. These additions are based on linear operations that are easily implementable into the binary training framework. We show experimental results on CIFAR-10 obtaining an accuracy of $86.7\%$, on AlexNet and $91.3\%$ with VGG network. On ImageNet, our method also outperforms the traditional BNN method and XNOR-net, using AlexNet by a margin of $4\%$ and $2\%$ top-$1$ accuracy respectively.
Causal Inference and Mechanism Clustering of A Mixture of Additive Noise Models
Oct 27, 2018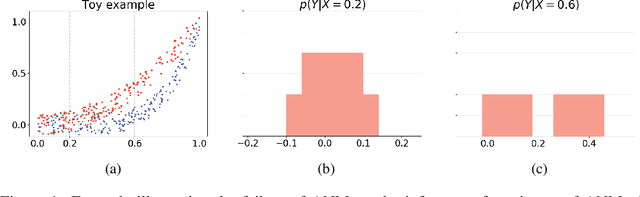
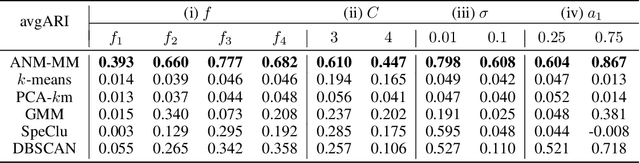
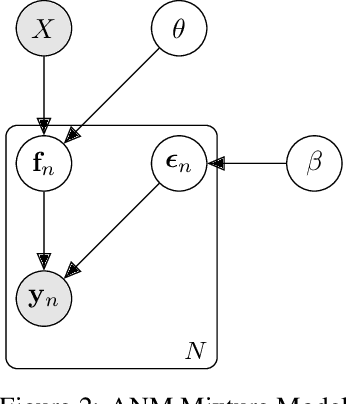
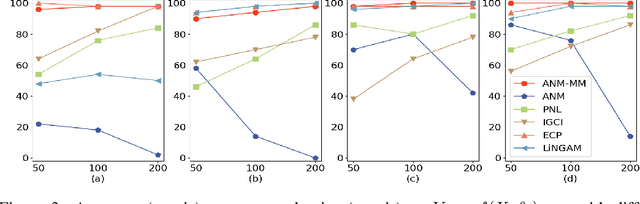
The inference of the causal relationship between a pair of observed variables is a fundamental problem in science, and most existing approaches are based on one single causal model. In practice, however, observations are often collected from multiple sources with heterogeneous causal models due to certain uncontrollable factors, which renders causal analysis results obtained by a single model skeptical. In this paper, we generalize the Additive Noise Model (ANM) to a mixture model, which consists of a finite number of ANMs, and provide the condition of its causal identifiability. To conduct model estimation, we propose Gaussian Process Partially Observable Model (GPPOM), and incorporate independence enforcement into it to learn latent parameter associated with each observation. Causal inference and clustering according to the underlying generating mechanisms of the mixture model are addressed in this work. Experiments on synthetic and real data demonstrate the effectiveness of our proposed approach.