 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Grammar for Information Extraction
May 06, 2003In this paper, we present the concept of Approximate grammar and how it can be used to extract information from a documemt. As the structure of informational strings cannot be defined well in a document, we cannot use the conventional grammar rules to represent the information. Hence, the need arises to design an approximate grammar that can be used effectively to accomplish the task of Information extraction. Approximate grammars are a novel step in this direction. The rules of an approximate grammar can be given by a user or the machine can learn the rules from an annotated document. We have performed our experiments in both the above areas and the results have been impressive.
* 10 pages, 3 figures, 2 tables, Presented at "International Conference on Universal Knowledge and Language, Goa'2002"
An Algorithm for Aligning Sentences in Bilingual Corpora Using Lexical Information
Feb 12, 2003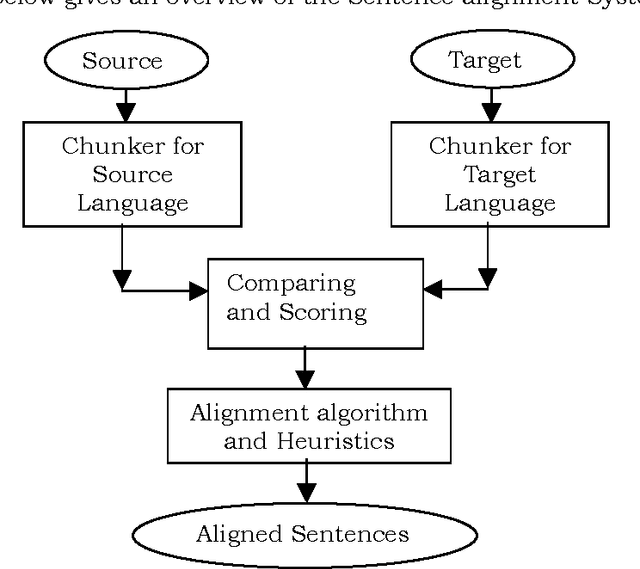
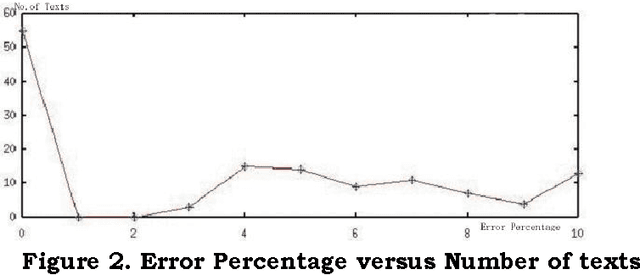
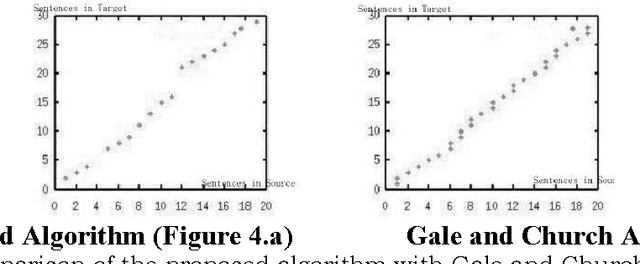
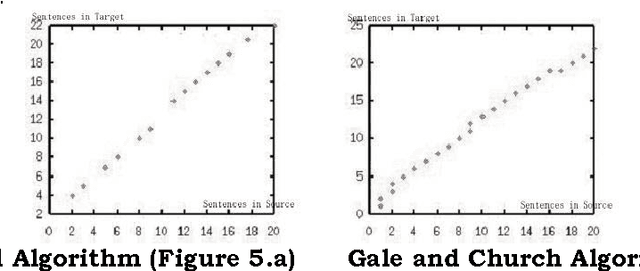
In this paper we describe an algorithm for aligning sentences with their translations in a bilingual corpus using lexical information of the languages. Existing efficient algorithms ignore word identities and consider only the sentence lengths (Brown, 1991; Gale and Church, 1993). For a sentence in the source language text, the proposed algorithm picks the most likely translation from the target language text using lexical information and certain heuristics. It does not do statistical analysis using sentence lengths. The algorithm is language independent. It also aids in detecting addition and deletion of text in translations. The algorithm gives comparable results with the existing algorithms in most of the cases while it does better in cases where statistical algorithms do not give good results.