 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Stereo Speech Enhancement with Spatial-Cue Preservation based on Dual-Path Structure
Feb 01, 2024We introduce a real-time, multichannel speech enhancement algorithm which maintains the spatial cues of stereo recordings including two speech sources. Recognizing that each source has unique spatial information, our method utilizes a dual-path structure, ensuring the spatial cues remain unaffected during enhancement by applying source-specific common-band gain. This method also seamlessly integrates pretrained monaural speech enhancement, eliminating the need for retraining on stereo inputs. Source separation from stereo mixtures is achieved via spatial beamforming, with the steering vector for each source being adaptively updated using post-enhancement output signal. This ensures accurate tracking of the spatial information. The final stereo output is derived by merging the spatial images of the enhanced sources, with its efficacy not heavily reliant on the separation performance of the beamforming. The algorithm runs in real-time on 10-ms frames with a 40 ms of look-ahead. Evaluations reveal its effectiveness in enhancing speech and preserving spatial cues in both fully and sparsely overlapped mixtures.
Semi-supervised Time Domain Target Speaker Extraction with Attention
Jun 18, 2022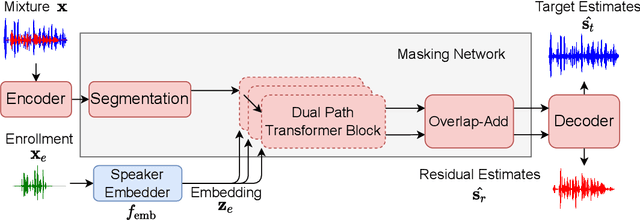

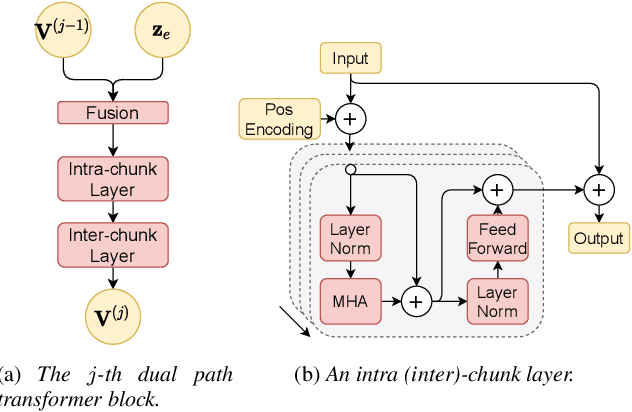
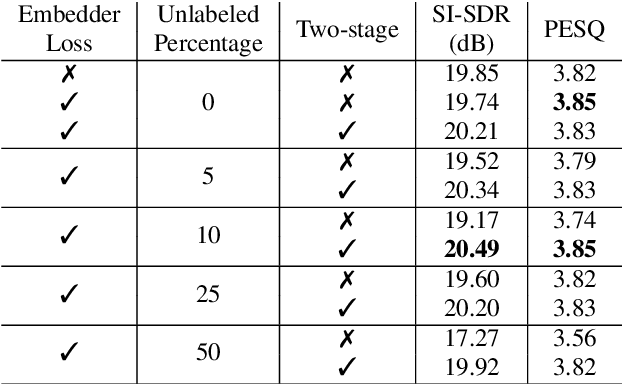
In this work, we propose Exformer, a time-domain architecture for target speaker extraction. It consists of a pre-trained speaker embedder network and a separator network based on transformer encoder blocks. We study multiple methods to combine speaker information with the input mixture, and the resulting Exformer architecture obtains superior extraction performance compared to prior time-domain networks. Furthermore, we investigate a two-stage procedure to train the model using mixtures without reference signals upon a pre-trained supervised model. Experimental results show that the proposed semi-supervised learning procedure improves the performance of the supervised baselines.
To Dereverb Or Not to Dereverb? Perceptual Studies On Real-Time Dereverberation Targets
Jun 16, 2022



In real life, room effect, also known as room reverberation, and the present background noise degrade the quality of speech. Recently, deep learning-based speech enhancement approaches have shown a lot of promise and surpassed traditional denoising and dereverberation methods. It is also well established that these state-of-the-art denoising algorithms significantly improve the quality of speech as perceived by human listeners. But the role of dereverberation on subjective (perceived) speech quality, and whether the additional artifacts introduced by dereverberation cause more harm than good are still unclear. In this paper, we attempt to answer these questions by evaluating a state of the art speech enhancement system in a comprehensive subjective evaluation study for different choices of dereverberation targets.
End-to-end LPCNet: A Neural Vocoder With Fully-Differentiable LPC Estimation
Mar 29, 2022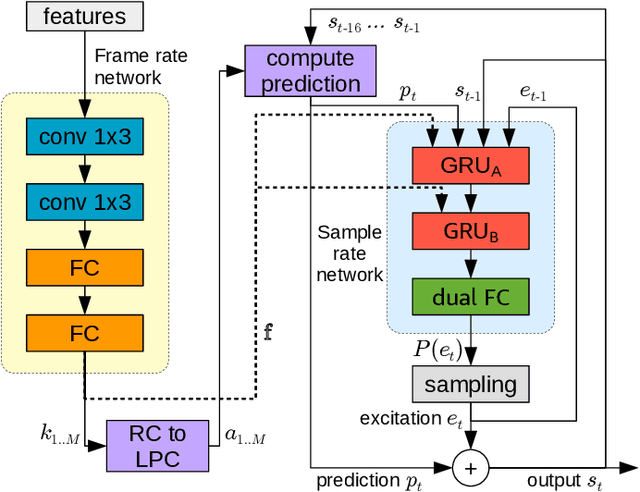
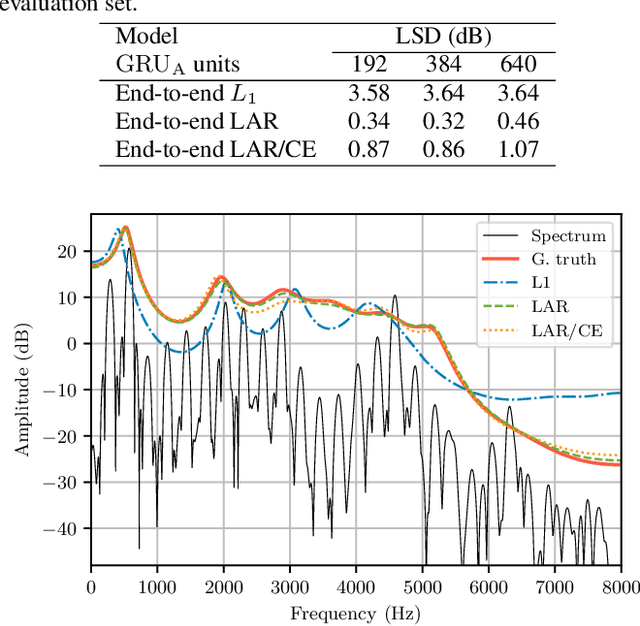
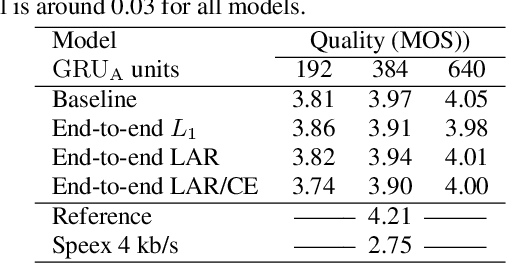
Neural vocoders have recently demonstrated high quality speech synthesis, but typically require a high computational complexity. LPCNet was proposed as a way to reduce the complexity of neural synthesis by using linear prediction (LP) to assist an autoregressive model. At inference time, LPCNet relies on the LP coefficients being explicitly computed from the input acoustic features. That makes the design of LPCNet-based systems more complicated, while adding the constraint that the input features must represent a clean speech spectrum. We propose an end-to-end version of LPCNet that lifts these limitations by learning to infer the LP coefficients from the input features in the frame rate network. Results show that the proposed end-to-end approach equals or exceeds the quality of the original LPCNet model, but without explicit LP analysis. Our open-source end-to-end model still benefits from LPCNet's low complexity, while allowing for any type of conditioning features.
Improved singing voice separation with chromagram-based pitch-aware remixing
Mar 28, 2022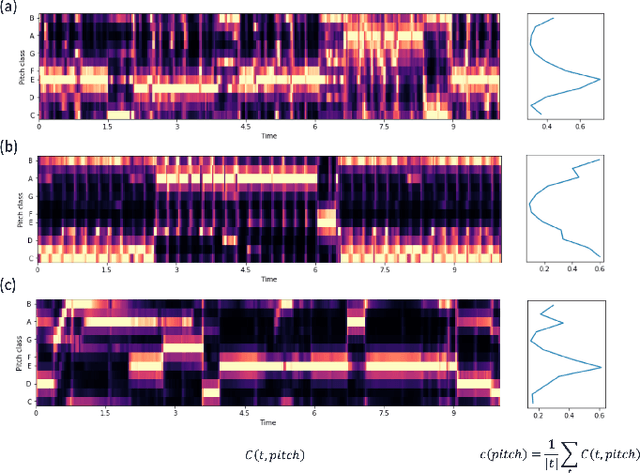
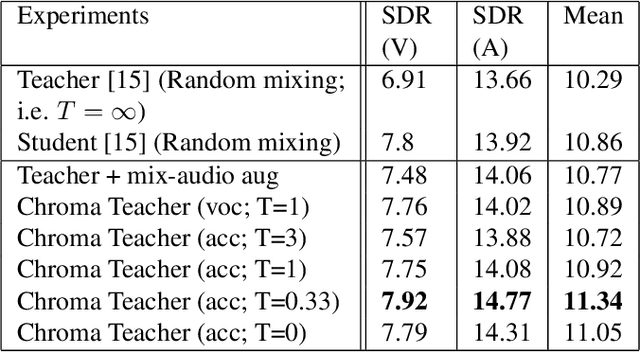
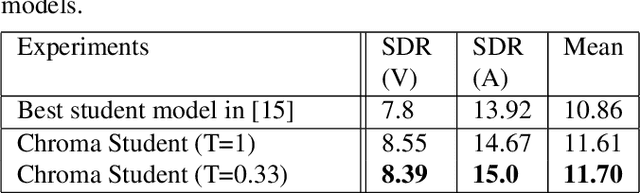
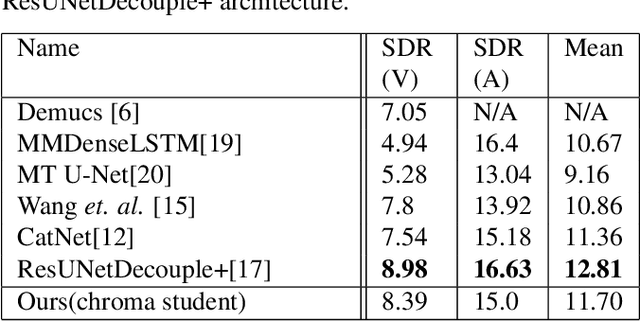
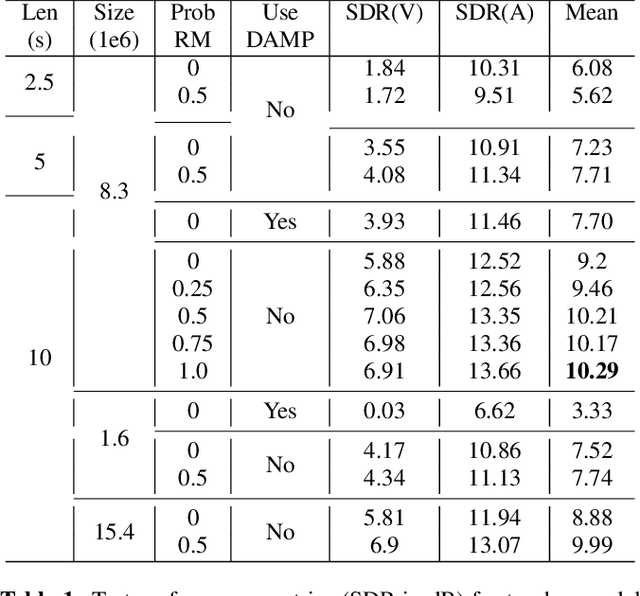
Singing voice separation aims to separate music into vocals and accompaniment components. One of the major constraints for the task is the limited amount of training data with separated vocals. Data augmentation techniques such as random source mixing have been shown to make better use of existing data and mildly improve model performance. We propose a novel data augmentation technique, chromagram-based pitch-aware remixing, where music segments with high pitch alignment are mixed. By performing controlled experiments in both supervised and semi-supervised settings, we demonstrate that training models with pitch-aware remixing significantly improves the test signal-to-distortion ratio (SDR)
Neural Speech Synthesis on a Shoestring: Improving the Efficiency of LPCNet
Feb 22, 2022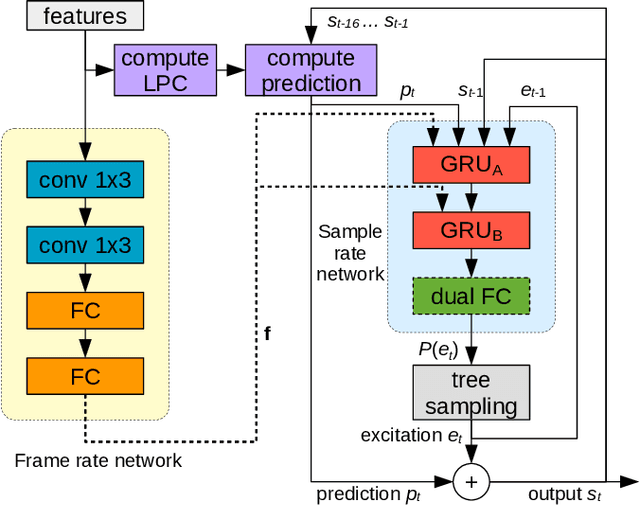
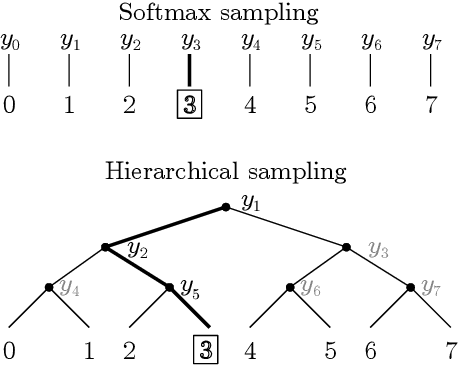
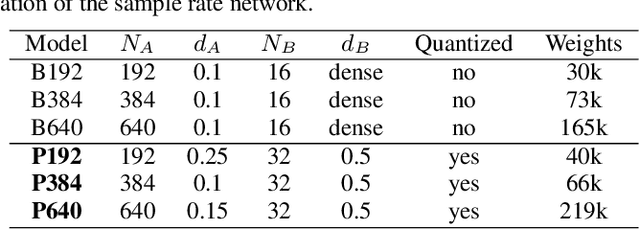
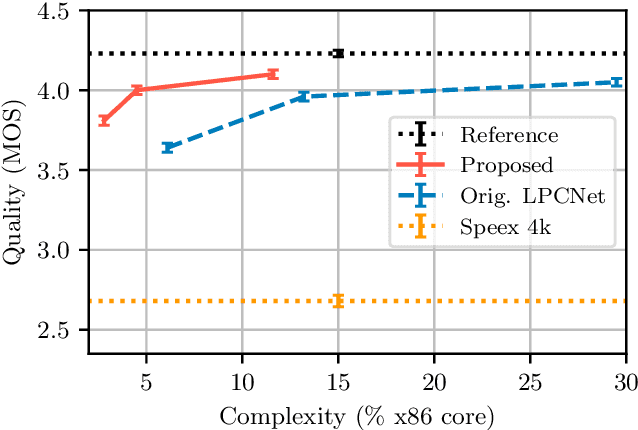
Neural speech synthesis models can synthesize high quality speech but typically require a high computational complexity to do so. In previous work, we introduced LPCNet, which uses linear prediction to significantly reduce the complexity of neural synthesis. In this work, we further improve the efficiency of LPCNet -- targeting both algorithmic and computational improvements -- to make it usable on a wide variety of devices. We demonstrate an improvement in synthesis quality while operating 2.5x faster. The resulting open-source LPCNet algorithm can perform real-time neural synthesis on most existing phones and is even usable in some embedded devices.
Personalized PercepNet: Real-time, Low-complexity Target Voice Separation and Enhancement
Jun 08, 2021



The presence of multiple talkers in the surrounding environment poses a difficult challenge for real-time speech communication systems considering the constraints on network size and complexity. In this paper, we present Personalized PercepNet, a real-time speech enhancement model that separates a target speaker from a noisy multi-talker mixture without compromising on complexity of the recently proposed PercepNet. To enable speaker-dependent speech enhancement, we first show how we can train a perceptually motivated speaker embedder network to produce a representative embedding vector for the given speaker. Personalized PercepNet uses the target speaker embedding as additional information to pick out and enhance only the target speaker while suppressing all other competing sounds. Our experiments show that the proposed model significantly outperforms PercepNet and other baselines, both in terms of objective speech enhancement metrics and human opinion scores.
Semi-Supervised Singing Voice Separation with Noisy Self-Training
Feb 16, 2021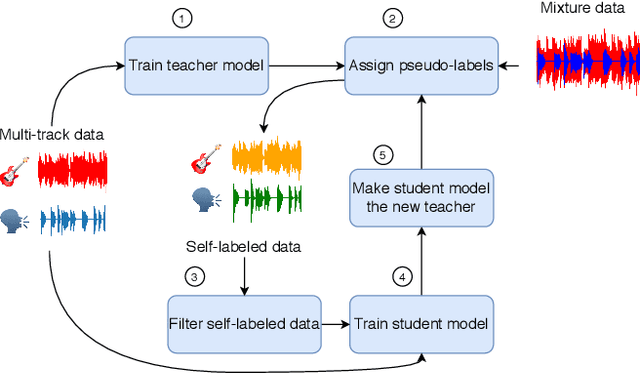
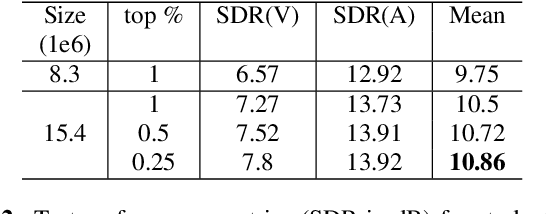
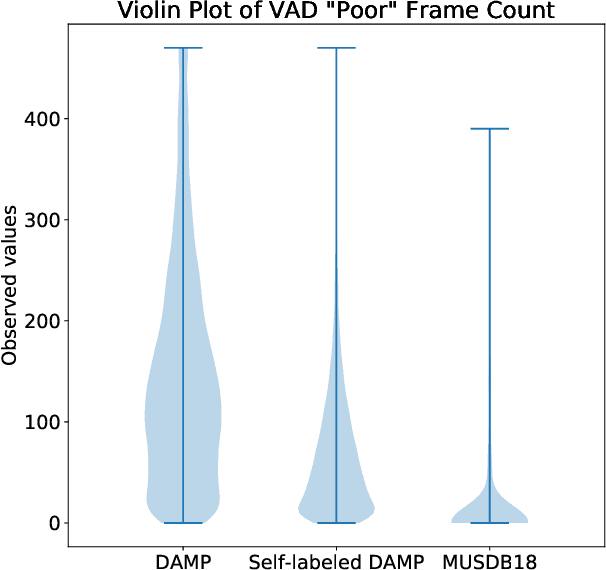
Recent progress in singing voice separation has primarily focused on supervised deep learning methods. However, the scarcity of ground-truth data with clean musical sources has been a problem for long. Given a limited set of labeled data, we present a method to leverage a large volume of unlabeled data to improve the model's performance. Following the noisy self-training framework, we first train a teacher network on the small labeled dataset and infer pseudo-labels from the large corpus of unlabeled mixtures. Then, a larger student network is trained on combined ground-truth and self-labeled datasets. Empirical results show that the proposed self-training scheme, along with data augmentation methods, effectively leverage the large unlabeled corpus and obtain superior performance compared to supervised methods.
Enhancing into the codec: Noise Robust Speech Coding with Vector-Quantized Autoencoders
Feb 12, 2021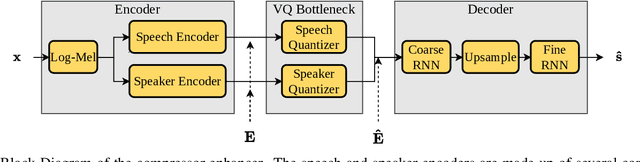
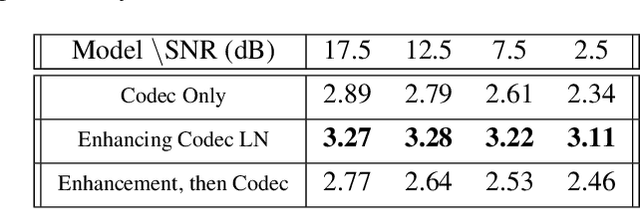
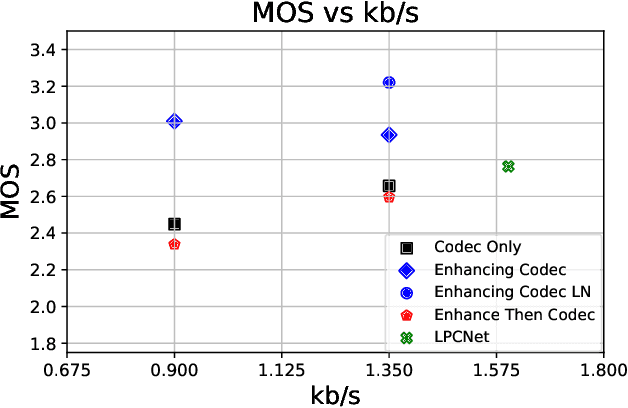
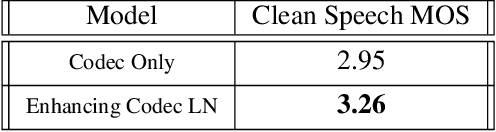
Audio codecs based on discretized neural autoencoders have recently been developed and shown to provide significantly higher compression levels for comparable quality speech output. However, these models are tightly coupled with speech content, and produce unintended outputs in noisy conditions. Based on VQ-VAE autoencoders with WaveRNN decoders, we develop compressor-enhancer encoders and accompanying decoders, and show that they operate well in noisy conditions. We also observe that a compressor-enhancer model performs better on clean speech inputs than a compressor model trained only on clean speech.
Low-Complexity, Real-Time Joint Neural Echo Control and Speech Enhancement Based On PercepNet
Feb 10, 2021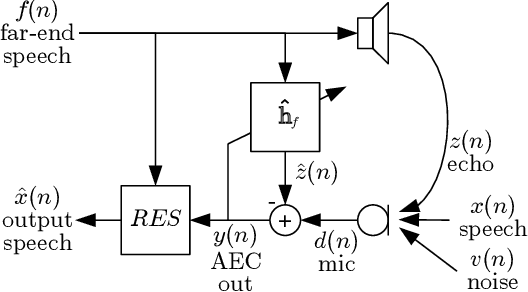
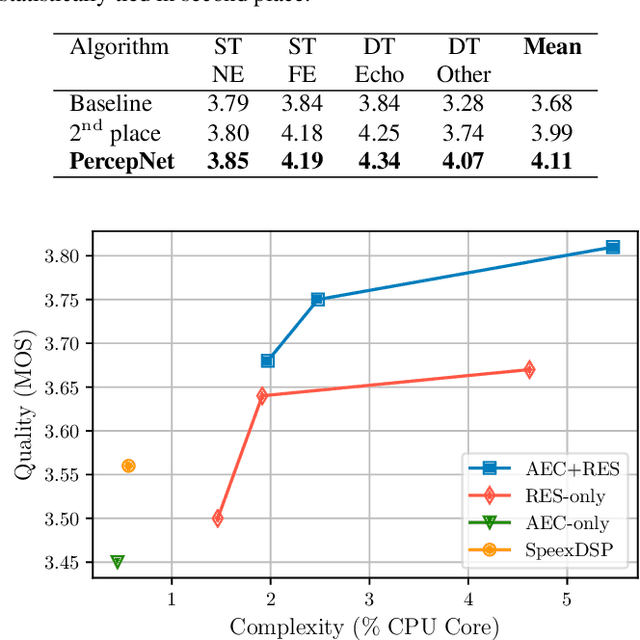
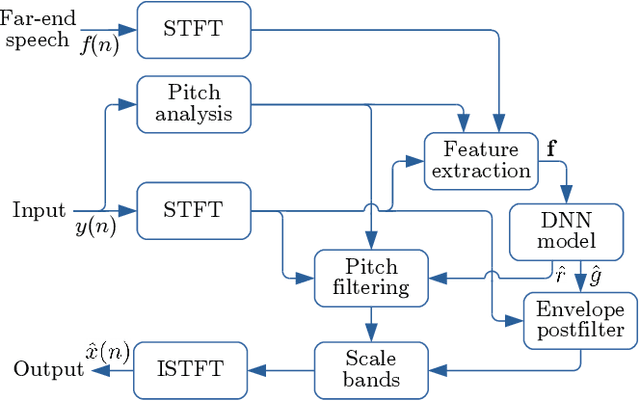
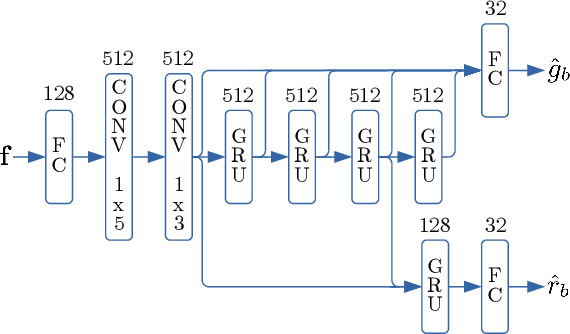
Speech enhancement algorithms based on deep learning have greatly surpassed their traditional counterparts and are now being considered for the task of removing acoustic echo from hands-free communication systems. This is a challenging problem due to both real-world constraints like loudspeaker non-linearities, and to limited compute capabilities in some communication systems. In this work, we propose a system combining a traditional acoustic echo canceller, and a low-complexity joint residual echo and noise suppressor based on a hybrid signal processing/deep neural network (DSP/DNN) approach. We show that the proposed system outperforms both traditional and other neural approaches, while requiring only 5.5% CPU for real-time operation. We further show that the system can scale to even lower complexity levels.