 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Variance to Invariance: Qualitative Content Analysis for Narrative Graph Annotation
Mar 04, 2026Narratives in news discourse play a critical role in shaping public understanding of economic events, such as inflation. Annotating and evaluating these narratives in a structured manner remains a key challenge for Natural Language Processing (NLP). In this work, we introduce a narrative graph annotation framework that integrates principles from qualitative content analysis (QCA) to prioritize annotation quality by reducing annotation errors. We present a dataset of inflation narratives annotated as directed acyclic graphs (DAGs), where nodes represent events and edges encode causal relations. To evaluate annotation quality, we employed a $6\times3$ factorial experimental design to examine the effects of narrative representation (six levels) and distance metric type (three levels) on inter-annotator agreement (Krippendorrf's $α$), capturing the presence of human label variation (HLV) in narrative interpretations. Our analysis shows that (1) lenient metrics (overlap-based distance) overestimate reliability, and (2) locally-constrained representations (e.g., one-hop neighbors) reduce annotation variability. Our annotation and implementation of graph-based Krippendorrf's $α$ are open-sourced. The annotation framework and evaluation results provide practical guidance for NLP research on graph-based narrative annotation under HLV.
Topic Scaling: A Joint Document Scaling -- Topic Model Approach To Learn Time-Specific Topics
Mar 31, 2021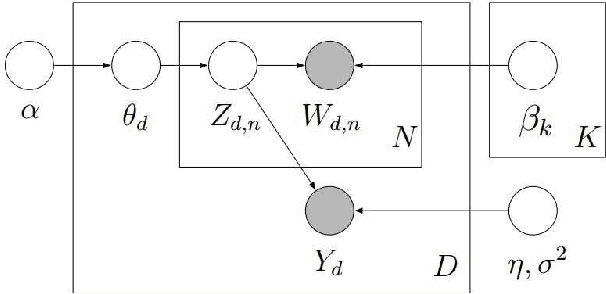
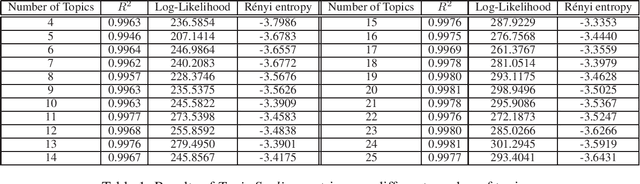
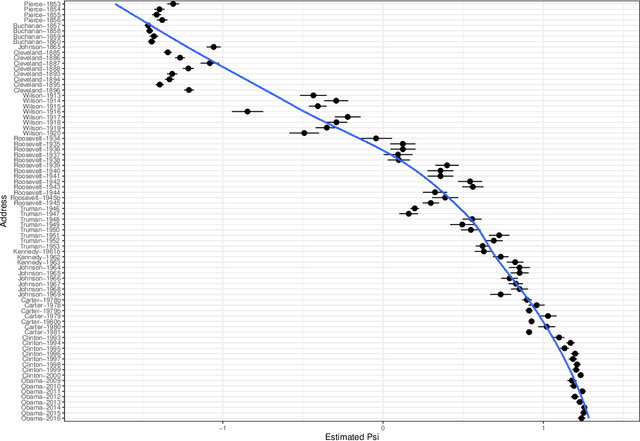

This paper proposes a new methodology to study sequential corpora by implementing a two-stage algorithm that learns time-based topics with respect to a scale of document positions and introduces the concept of Topic Scaling which ranks learned topics within the same document scale. The first stage ranks documents using Wordfish, a Poisson-based document scaling method, to estimate document positions that serve, in the second stage, as a dependent variable to learn relevant topics via a supervised Latent Dirichlet Allocation. This novelty brings two innovations in text mining as it explains document positions, whose scale is a latent variable, and ranks the inferred topics on the document scale to match their occurrences within the corpus and track their evolution. Tested on the U.S. State Of The Union two-party addresses, this inductive approach reveals that each party dominates one end of the learned scale with interchangeable transitions that follow the parties' term of office. Besides a demonstrated high accuracy in predicting in-sample documents' positions from topic scores, this method reveals further hidden topics that differentiate similar documents by increasing the number of learned topics to unfold potential nested hierarchical topic structures. Compared to other popular topic models, Topic Scaling learns topics with respect to document similarities without specifying a time frequency to learn topic evolution, thus capturing broader topic patterns than dynamic topic models and yielding more interpretable outputs than a plain latent Dirichlet allocation.