 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Explainability in NLP and Analyzing Algorithms for Performance-Explainability Tradeoff
Jul 12, 2021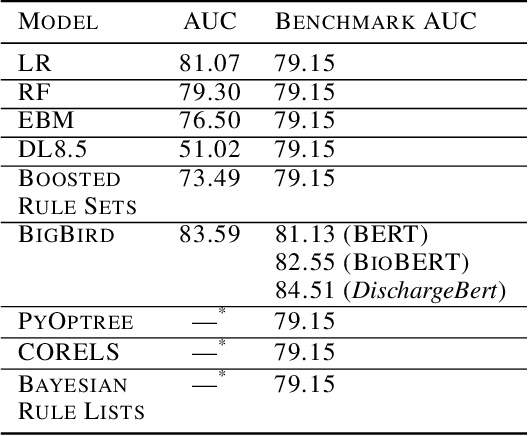
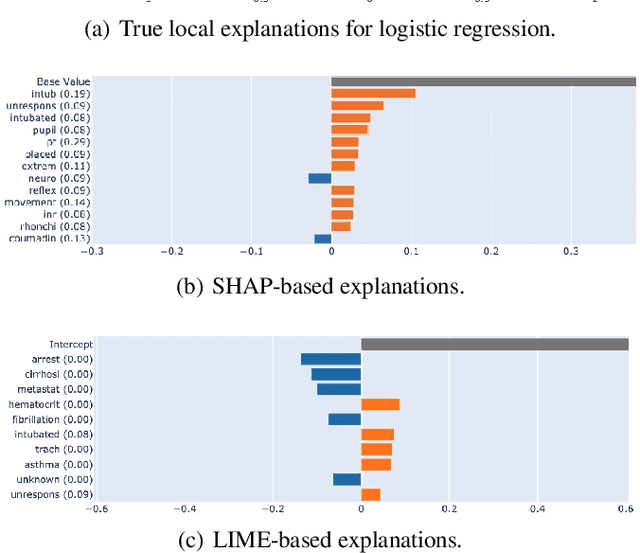
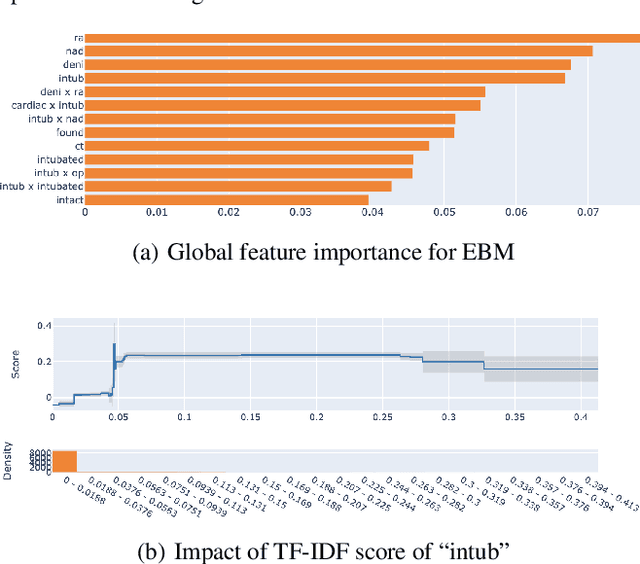
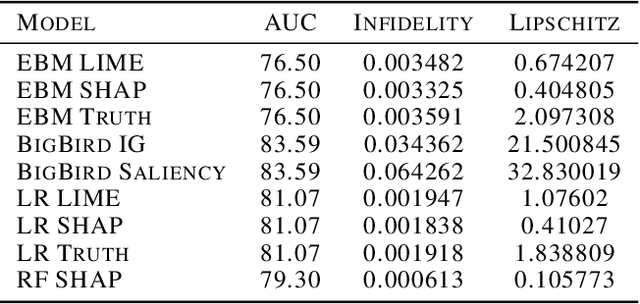
The healthcare domain is one of the most exciting application areas for machine learning, but a lack of model transparency contributes to a lag in adoption within the industry. In this work, we explore the current art of explainability and interpretability within a case study in clinical text classification, using a task of mortality prediction within MIMIC-III clinical notes. We demonstrate various visualization techniques for fully interpretable methods as well as model-agnostic post hoc attributions, and we provide a generalized method for evaluating the quality of explanations using infidelity and local Lipschitz across model types from logistic regression to BERT variants. With these metrics, we introduce a framework through which practitioners and researchers can assess the frontier between a model's predictive performance and the quality of its available explanations. We make our code available to encourage continued refinement of these methods.
Theoretical and Empirical Analysis of a Parallel Boosting Algorithm
Aug 06, 2015
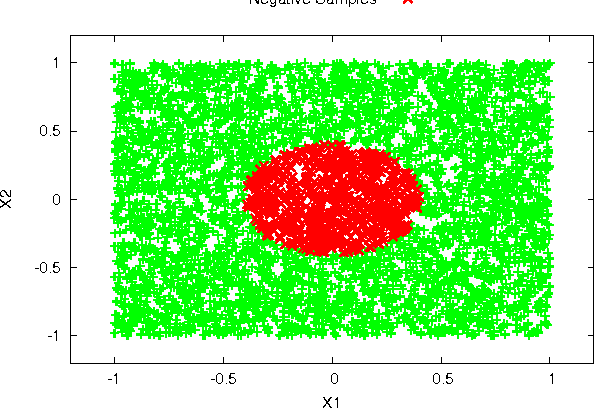
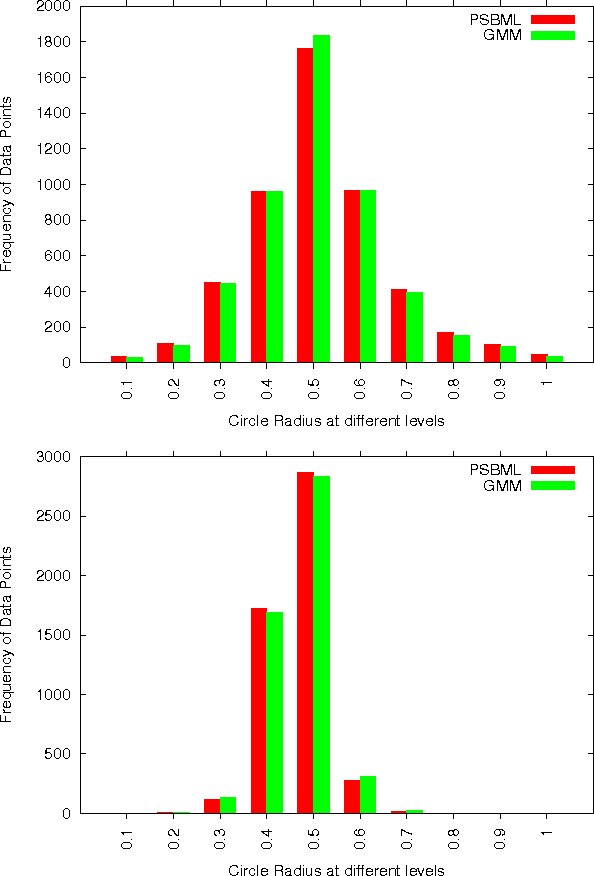

Many real-world problems involve massive amounts of data. Under these circumstances learning algorithms often become prohibitively expensive, making scalability a pressing issue to be addressed. A common approach is to perform sampling to reduce the size of the dataset and enable efficient learning. Alternatively, one customizes learning algorithms to achieve scalability. In either case, the key challenge is to obtain algorithmic efficiency without compromising the quality of the results. In this paper we discuss a meta-learning algorithm (PSBML) which combines features of parallel algorithms with concepts from ensemble and boosting methodologies to achieve the desired scalability property. We present both theoretical and empirical analyses which show that PSBML preserves a critical property of boosting, specifically, convergence to a distribution centered around the margin. We then present additional empirical analyses showing that this meta-level algorithm provides a general and effective framework that can be used in combination with a variety of learning classifiers. We perform extensive experiments to investigate the tradeoff achieved between scalability and accuracy, and robustness to noise, on both synthetic and real-world data. These empirical results corroborate our theoretical analysis, and demonstrate the potential of PSBML in achieving scalability without sacrificing accuracy.