 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalous State Sequence Modeling to Enhance Safety in Reinforcement Learning
Jul 29, 2024The deployment of artificial intelligence (AI) in decision-making applications requires ensuring an appropriate level of safety and reliability, particularly in changing environments that contain a large number of unknown observations. To address this challenge, we propose a novel safe reinforcement learning (RL) approach that utilizes an anomalous state sequence to enhance RL safety. Our proposed solution Safe Reinforcement Learning with Anomalous State Sequences (AnoSeqs) consists of two stages. First, we train an agent in a non-safety-critical offline 'source' environment to collect safe state sequences. Next, we use these safe sequences to build an anomaly detection model that can detect potentially unsafe state sequences in a 'target' safety-critical environment where failures can have high costs. The estimated risk from the anomaly detection model is utilized to train a risk-averse RL policy in the target environment; this involves adjusting the reward function to penalize the agent for visiting anomalous states deemed unsafe by our anomaly model. In experiments on multiple safety-critical benchmarking environments including self-driving cars, our solution approach successfully learns safer policies and proves that sequential anomaly detection can provide an effective supervisory signal for training safety-aware RL agents
Learning Contextualized Music Semantics from Tags via a Siamese Network
Jun 07, 2016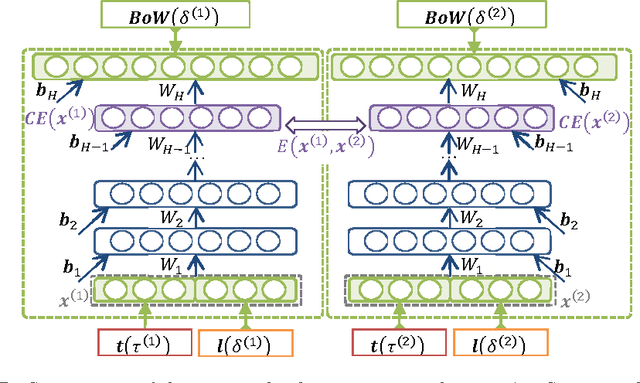
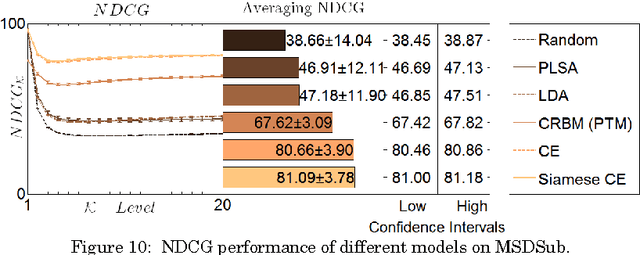
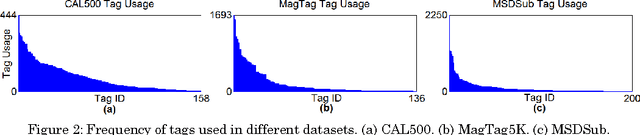
Music information retrieval faces a challenge in modeling contextualized musical concepts formulated by a set of co-occurring tags. In this paper, we investigate the suitability of our recently proposed approach based on a Siamese neural network in fighting off this challenge. By means of tag features and probabilistic topic models, the network captures contextualized semantics from tags via unsupervised learning. This leads to a distributed semantics space and a potential solution to the out of vocabulary problem which has yet to be sufficiently addressed. We explore the nature of the resultant music-based semantics and address computational needs. We conduct experiments on three public music tag collections -namely, CAL500, MagTag5K and Million Song Dataset- and compare our approach to a number of state-of-the-art semantics learning approaches. Comparative results suggest that this approach outperforms previous approaches in terms of semantic priming and music tag completion.
Multi-Label Zero-Shot Learning via Concept Embedding
Jun 01, 2016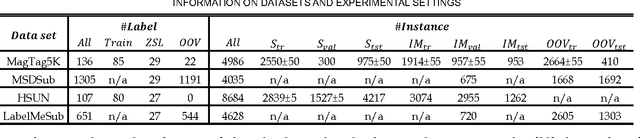

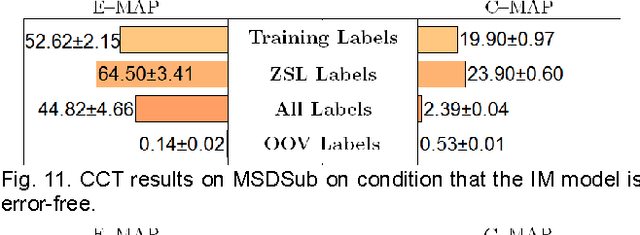
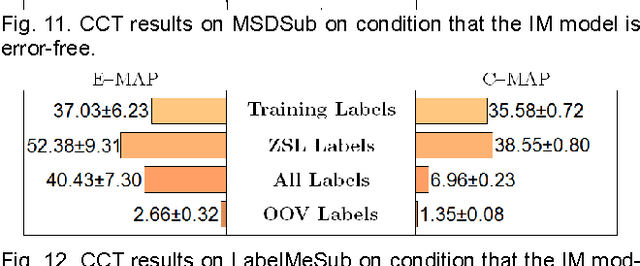
Zero Shot Learning (ZSL) enables a learning model to classify instances of an unseen class during training. While most research in ZSL focuses on single-label classification, few studies have been done in multi-label ZSL, where an instance is associated with a set of labels simultaneously, due to the difficulty in modeling complex semantics conveyed by a set of labels. In this paper, we propose a novel approach to multi-label ZSL via concept embedding learned from collections of public users' annotations of multimedia. Thanks to concept embedding, multi-label ZSL can be done by efficiently mapping an instance input features onto the concept embedding space in a similar manner used in single-label ZSL. Moreover, our semantic learning model is capable of embedding an out-of-vocabulary label by inferring its meaning from its co-occurring labels. Thus, our approach allows both seen and unseen labels during the concept embedding learning to be used in the aforementioned instance mapping, which makes multi-label ZSL more flexible and suitable for real applications. Experimental results of multi-label ZSL on images and music tracks suggest that our approach outperforms a state-of-the-art multi-label ZSL model and can deal with a scenario involving out-of-vocabulary labels without re-training the semantics learning model.
Learning Contextualized Semantics from Co-occurring Terms via a Siamese Architecture
Jun 17, 2015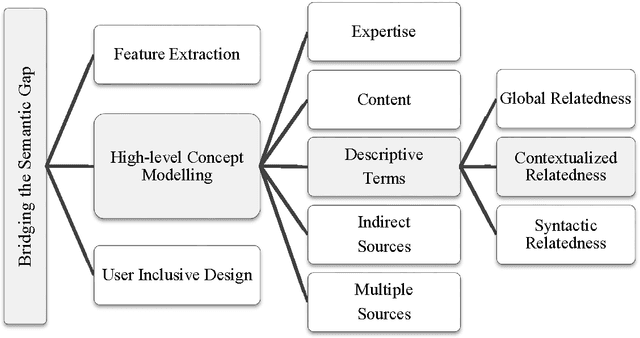
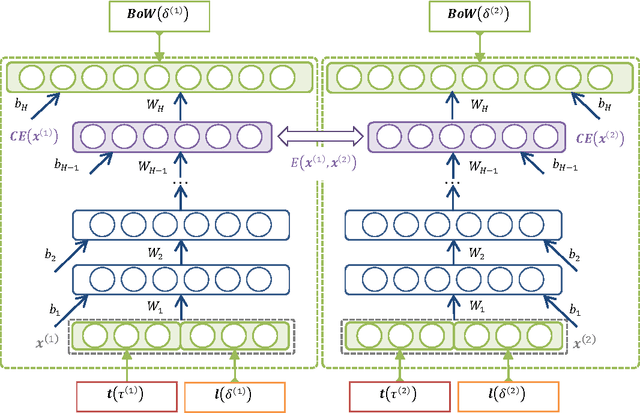
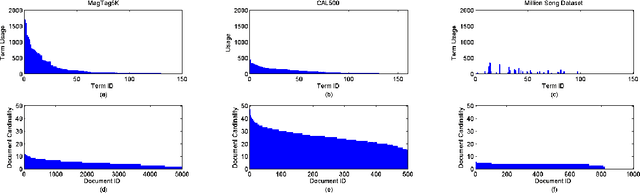
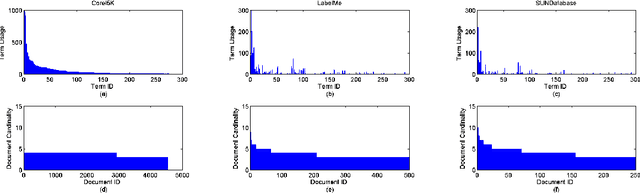
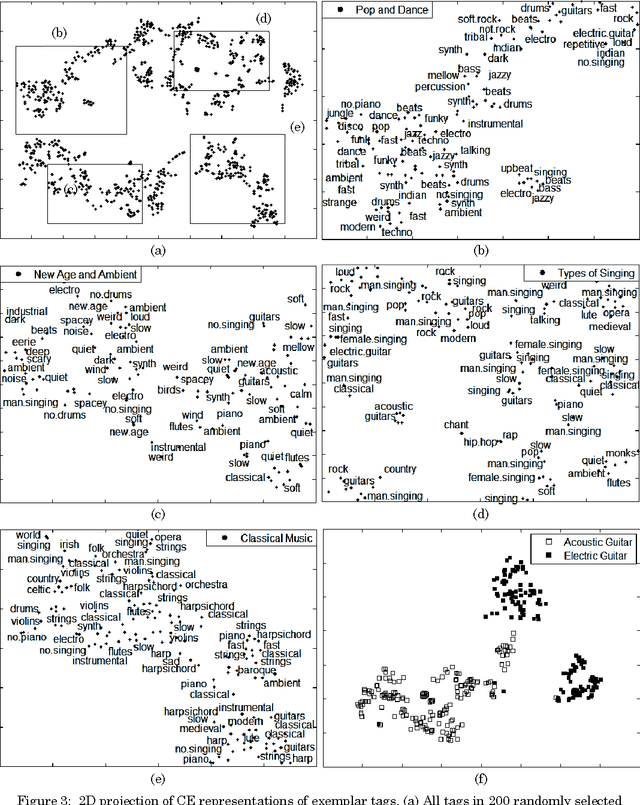
One of the biggest challenges in Multimedia information retrieval and understanding is to bridge the semantic gap by properly modeling concept semantics in context. The presence of out of vocabulary (OOV) concepts exacerbates this difficulty. To address the semantic gap issues, we formulate a problem on learning contextualized semantics from descriptive terms and propose a novel Siamese architecture to model the contextualized semantics from descriptive terms. By means of pattern aggregation and probabilistic topic models, our Siamese architecture captures contextualized semantics from the co-occurring descriptive terms via unsupervised learning, which leads to a concept embedding space of the terms in context. Furthermore, the co-occurring OOV concepts can be easily represented in the learnt concept embedding space. The main properties of the concept embedding space are demonstrated via visualization. Using various settings in semantic priming, we have carried out a thorough evaluation by comparing our approach to a number of state-of-the-art methods on six annotation corpora in different domains, i.e., MagTag5K, CAL500 and Million Song Dataset in the music domain as well as Corel5K, LabelMe and SUNDatabase in the image domain. Experimental results on semantic priming suggest that our approach outperforms those state-of-the-art methods considerably in various aspects.