 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Evaluation of Two CCG, a PCFG and a Link Grammar Parsers
Jan 24, 2008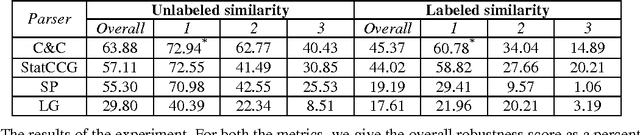

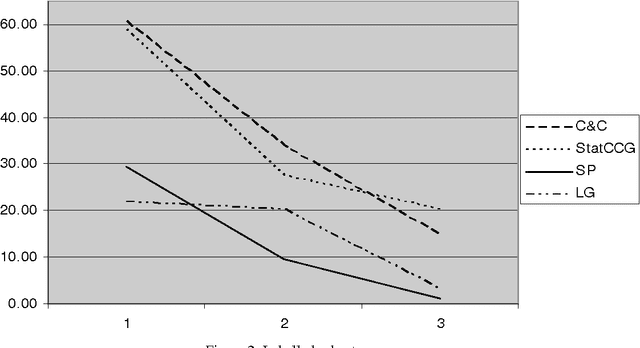
Robustness in a parser refers to an ability to deal with exceptional phenomena. A parser is robust if it deals with phenomena outside its normal range of inputs. This paper reports on a series of robustness evaluations of state-of-the-art parsers in which we concentrated on one aspect of robustness: its ability to parse sentences containing misspelled words. We propose two measures for robustness evaluation based on a comparison of a parser's output for grammatical input sentences and their noisy counterparts. In this paper, we use these measures to compare the overall robustness of the four evaluated parsers, and we present an analysis of the decline in parser performance with increasing error levels. Our results indicate that performance typically declines tens of percentage units when parsers are presented with texts containing misspellings. When it was tested on our purpose-built test set of 443 sentences, the best parser in the experiment (C&C parser) was able to return exactly the same parse tree for the grammatical and ungrammatical sentences for 60.8%, 34.0% and 14.9% of the sentences with one, two or three misspelled words respectively.
Framework and Resources for Natural Language Parser Evaluation
Dec 21, 2007
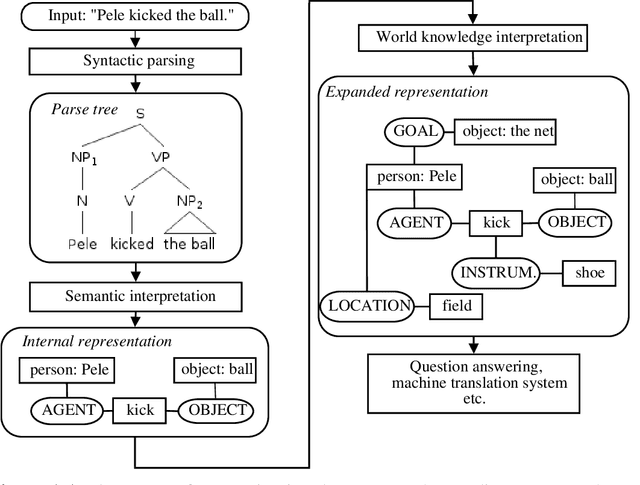

Because of the wide variety of contemporary practices used in the automatic syntactic parsing of natural languages, it has become necessary to analyze and evaluate the strengths and weaknesses of different approaches. This research is all the more necessary because there are currently no genre- and domain-independent parsers that are able to analyze unrestricted text with 100% preciseness (I use this term to refer to the correctness of analyses assigned by a parser). All these factors create a need for methods and resources that can be used to evaluate and compare parsing systems. This research describes: (1) A theoretical analysis of current achievements in parsing and parser evaluation. (2) A framework (called FEPa) that can be used to carry out practical parser evaluations and comparisons. (3) A set of new evaluation resources: FiEval is a Finnish treebank under construction, and MGTS and RobSet are parser evaluation resources in English. (4) The results of experiments in which the developed evaluation framework and the two resources for English were used for evaluating a set of selected parsers.
Dependency Treebanks: Methods, Annotation Schemes and Tools
Oct 20, 2006
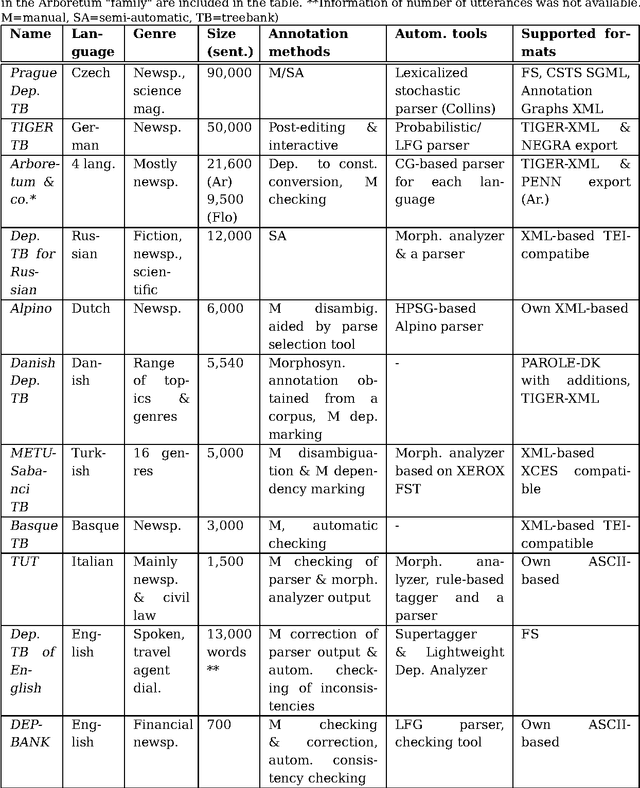
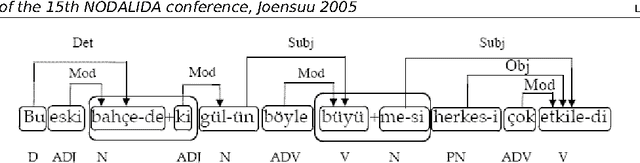
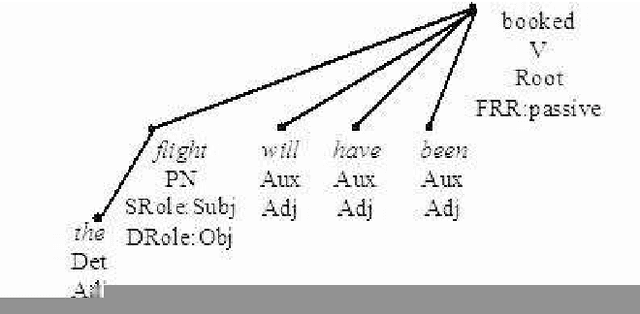
In this paper, current dependencybased treebanks are introduced and analyzed. The methods used for building the resources, the annotation schemes applied, and the tools used (such as POS taggers, parsers and annotation software) are discussed.
Applying Part-of-Seech Enhanced LSA to Automatic Essay Grading
Oct 19, 2006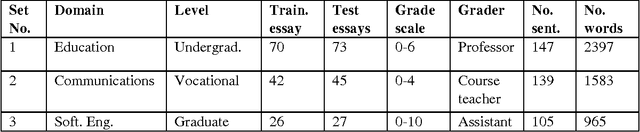
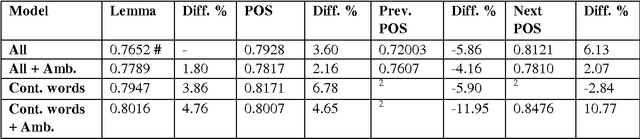
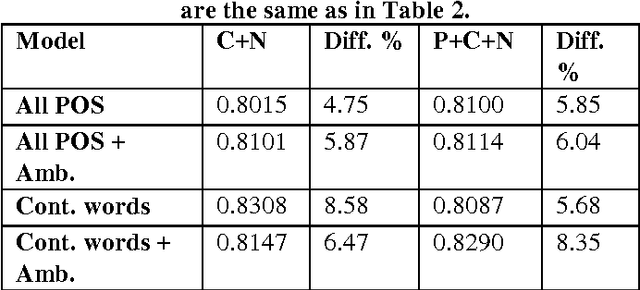
Latent Semantic Analysis (LSA) is a widely used Information Retrieval method based on "bag-of-words" assumption. However, according to general conception, syntax plays a role in representing meaning of sentences. Thus, enhancing LSA with part-of-speech (POS) information to capture the context of word occurrences appears to be theoretically feasible extension. The approach is tested empirically on a automatic essay grading system using LSA for document similarity comparisons. A comparison on several POS-enhanced LSA models is reported. Our findings show that the addition of contextual information in the form of POS tags can raise the accuracy of the LSA-based scoring models up to 10.77 per cent.
DepAnn - An Annotation Tool for Dependency Treebanks
Oct 19, 2006

DepAnn is an interactive annotation tool for dependency treebanks, providing both graphical and text-based annotation interfaces. The tool is aimed for semi-automatic creation of treebanks. It aids the manual inspection and correction of automatically created parses, making the annotation process faster and less error-prone. A novel feature of the tool is that it enables the user to view outputs from several parsers as the basis for creating the final tree to be saved to the treebank. DepAnn uses TIGER-XML, an XML-based general encoding format for both, representing the parser outputs and saving the annotated treebank. The tool includes an automatic consistency checker for sentence structures. In addition, the tool enables users to build structures manually, add comments on the annotations, modify the tagsets, and mark sentences for further revision.