 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResset: A Recurrent Model for Sequence of Sets with Applications to Electronic Medical Records
Feb 03, 2018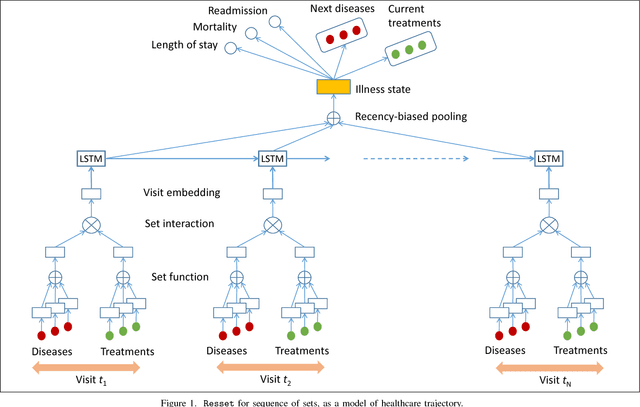
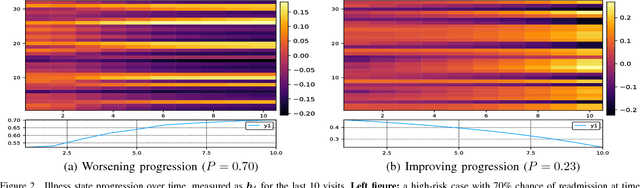

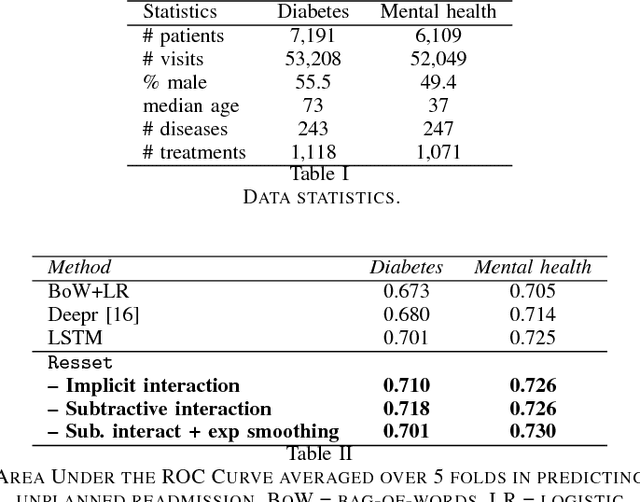
Modern healthcare is ripe for disruption by AI. A game changer would be automatic understanding the latent processes from electronic medical records, which are being collected for billions of people worldwide. However, these healthcare processes are complicated by the interaction between at least three dynamic components: the illness which involves multiple diseases, the care which involves multiple treatments, and the recording practice which is biased and erroneous. Existing methods are inadequate in capturing the dynamic structure of care. We propose Resset, an end-to-end recurrent model that reads medical record and predicts future risk. The model adopts the algebraic view in that discrete medical objects are embedded into continuous vectors lying in the same space. We formulate the problem as modeling sequences of sets, a novel setting that have rarely, if not, been addressed. Within Resset, the bag of diseases recorded at each clinic visit is modeled as function of sets. The same hold for the bag of treatments. The interaction between the disease bag and the treatment bag at a visit is modeled in several, one of which as residual of diseases minus the treatments. Finally, the health trajectory, which is a sequence of visits, is modeled using a recurrent neural network. We report results on over a hundred thousand hospital visits by patients suffered from two costly chronic diseases -- diabetes and mental health. Resset shows promises in multiple predictive tasks such as readmission prediction, treatments recommendation and diseases progression.
Memory-Augmented Neural Networks for Predictive Process Analytics
Feb 03, 2018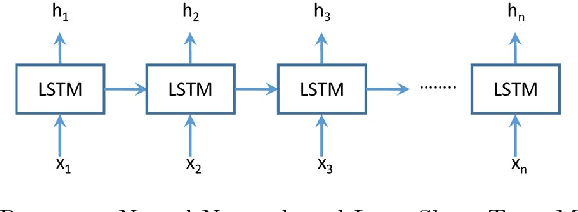

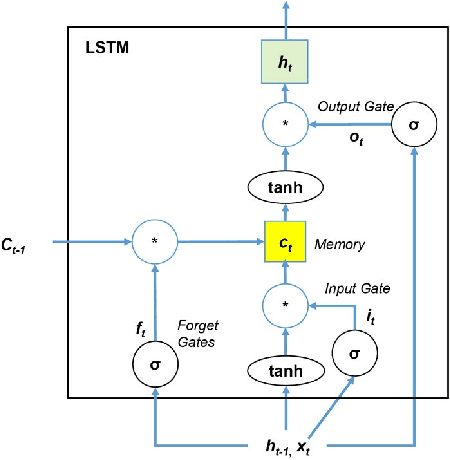
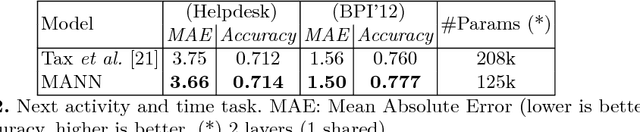
Process analytics involves a sophisticated layer of data analytics built over the traditional notion of process mining. The flexible execution of business process instances involves multiple critical decisions including what task to perform next and what resources to allocate to a task. In this paper, we explore the application of deep learning techniques for solving various process analytics related problems. Based on recent advances in the field we specifically look at memory-augmented neural networks (MANN)s and adapt the latest model to date, namely the Differential Neural Computer. We introduce two modifications to account for a variety of tasks in predictive process analytics: (i) separating the encoding phase and decoding phase, resulting dual controllers, one for each phase; (ii) implementing a write-protected policy for the memory during the decoding phase. We demonstrate the feasibility and usefulness of our approach by solving a number of common process analytics tasks such as next activity prediction, time to completion and suffix prediction. We also introduce the notion of MANN based process analytics recommendation machinery that once deployed can serve as an effective business process recommendation engine enabling organizations to answer various prescriptive process analytics related questions.Using real-world datasets, we benchmark our results against those obtained from the state-of-art methods. We show that MANNs based process analytics methods can acheive state-of-the-art performance and have a lot of value to offer for enterprise specific process anlaytics applications.
Graph Memory Networks for Molecular Activity Prediction
Jan 27, 2018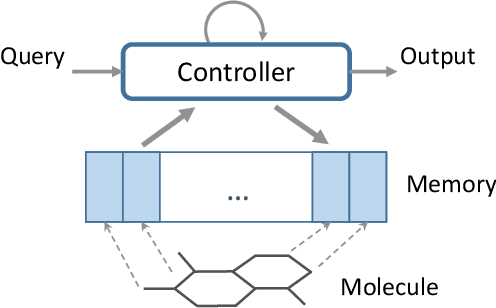
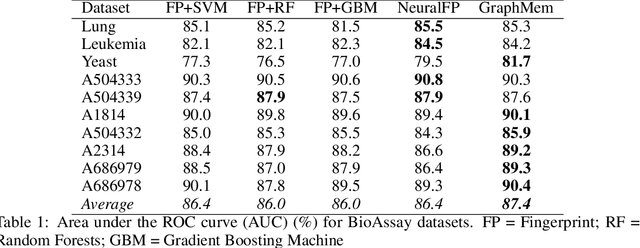
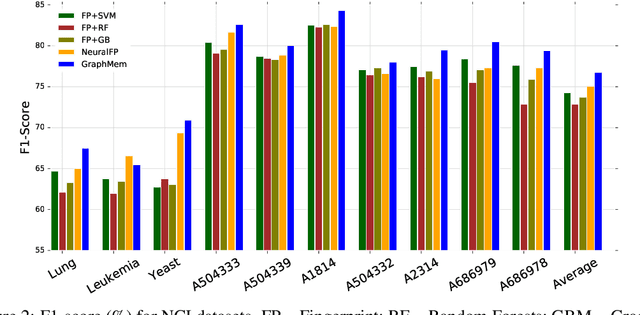
Molecular activity prediction is critical in drug design. Machine learning techniques such as kernel methods and random forests have been successful for this task. These models require fixed-size feature vectors as input while the molecules are variable in size and structure. As a result, fixed-size fingerprint representation is poor in handling substructures for large molecules. In addition, molecular activity tests, or a so-called BioAssays, are relatively small in the number of tested molecules due to its complexity. Here we approach the problem through deep neural networks as they are flexible in modeling structured data such as grids, sequences and graphs. We train multiple BioAssays using a multi-task learning framework, which combines information from multiple sources to improve the performance of prediction, especially on small datasets. We propose Graph Memory Network (GraphMem), a memory-augmented neural network to model the graph structure in molecules. GraphMem consists of a recurrent controller coupled with an external memory whose cells dynamically interact and change through a multi-hop reasoning process. Applied to the molecules, the dynamic interactions enable an iterative refinement of the representation of molecular graphs with multiple bond types. GraphMem is capable of jointly training on multiple datasets by using a specific-task query fed to the controller as an input. We demonstrate the effectiveness of the proposed model for separately and jointly training on more than 100K measurements, spanning across 9 BioAssay activity tests.
Knowledge Graph Embedding with Multiple Relation Projections
Jan 26, 2018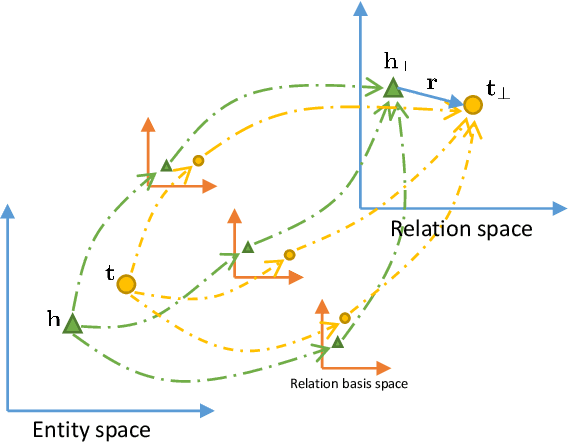
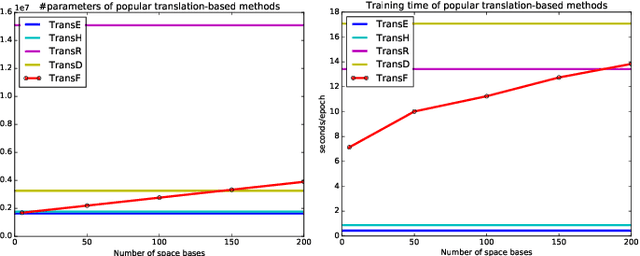
Knowledge graphs contain rich relational structures of the world, and thus complement data-driven machine learning in heterogeneous data. One of the most effective methods in representing knowledge graphs is to embed symbolic relations and entities into continuous spaces, where relations are approximately linear translation between projected images of entities in the relation space. However, state-of-the-art relation projection methods such as TransR, TransD or TransSparse do not model the correlation between relations, and thus are not scalable to complex knowledge graphs with thousands of relations, both in computational demand and in statistical robustness. To this end we introduce TransF, a novel translation-based method which mitigates the burden of relation projection by explicitly modeling the basis subspaces of projection matrices. As a result, TransF is far more light weight than the existing projection methods, and is robust when facing a high number of relations. Experimental results on the canonical link prediction task show that our proposed model outperforms competing rivals by a large margin and achieves state-of-the-art performance. Especially, TransF improves by 9%/5% in the head/tail entity prediction task for N-to-1/1-to-N relations over the best performing translation-based method.
Finding Algebraic Structure of Care in Time: A Deep Learning Approach
Nov 21, 2017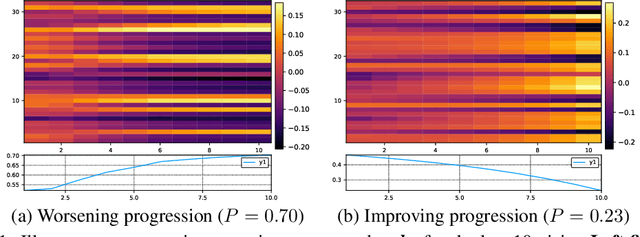
Understanding the latent processes from Electronic Medical Records could be a game changer in modern healthcare. However, the processes are complex due to the interaction between at least three dynamic components: the illness, the care and the recording practice. Existing methods are inadequate in capturing the dynamic structure of care. We propose an end-to-end model that reads medical record and predicts future risk. The model adopts the algebraic view in that discrete medical objects are embedded into continuous vectors lying in the same space. The bag of disease and comorbidities recorded at each hospital visit are modeled as function of sets. The same holds for the bag of treatments. The interaction between diseases and treatments at a visit is modeled as the residual of the diseases minus the treatments. Finally, the health trajectory, which is a sequence of visits, is modeled using a recurrent neural network. We report preliminary results on chronic diseases - diabetes and mental health - for predicting unplanned readmission.
Nonnegative Restricted Boltzmann Machines for Parts-based Representations Discovery and Predictive Model Stabilization
Aug 18, 2017
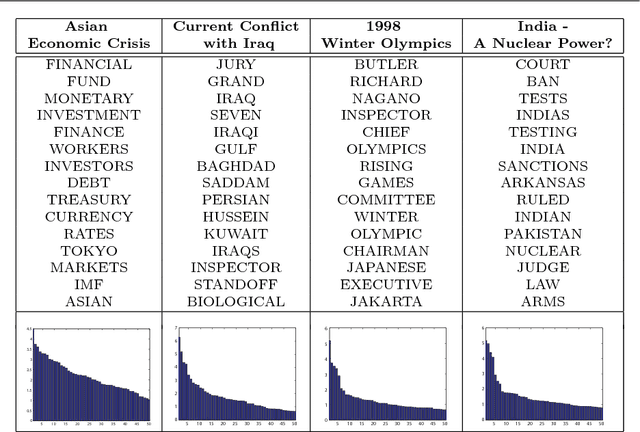
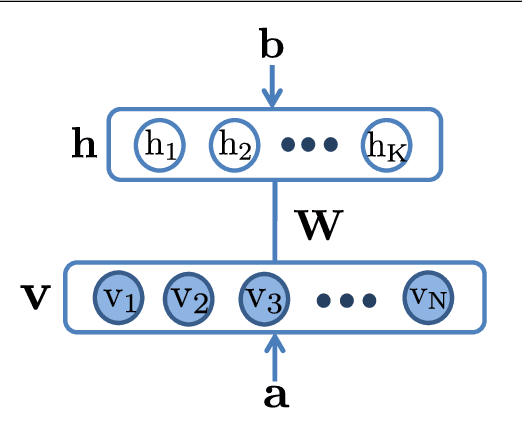
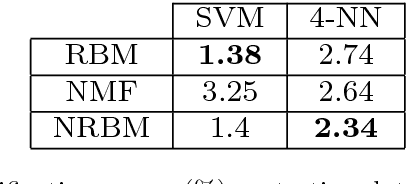
The success of any machine learning system depends critically on effective representations of data. In many cases, it is desirable that a representation scheme uncovers the parts-based, additive nature of the data. Of current representation learning schemes, restricted Boltzmann machines (RBMs) have proved to be highly effective in unsupervised settings. However, when it comes to parts-based discovery, RBMs do not usually produce satisfactory results. We enhance such capacity of RBMs by introducing nonnegativity into the model weights, resulting in a variant called nonnegative restricted Boltzmann machine (NRBM). The NRBM produces not only controllable decomposition of data into interpretable parts but also offers a way to estimate the intrinsic nonlinear dimensionality of data, and helps to stabilize linear predictive models. We demonstrate the capacity of our model on applications such as handwritten digit recognition, face recognition, document classification and patient readmission prognosis. The decomposition quality on images is comparable with or better than what produced by the nonnegative matrix factorization (NMF), and the thematic features uncovered from text are qualitatively interpretable in a similar manner to that of the latent Dirichlet allocation (LDA). The stability performance of feature selection on medical data is better than RBM and competitive with NMF. The learned features, when used for classification, are more discriminative than those discovered by both NMF and LDA and comparable with those by RBM.
Statistical Latent Space Approach for Mixed Data Modelling and Applications
Aug 18, 2017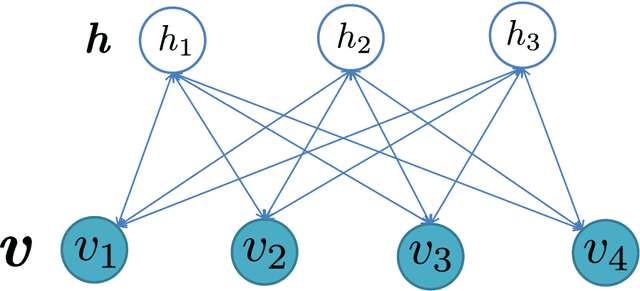
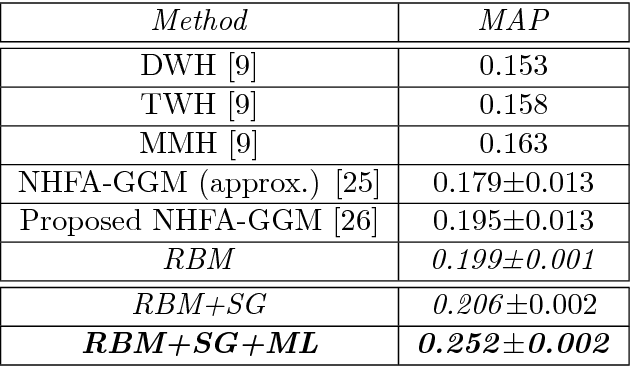
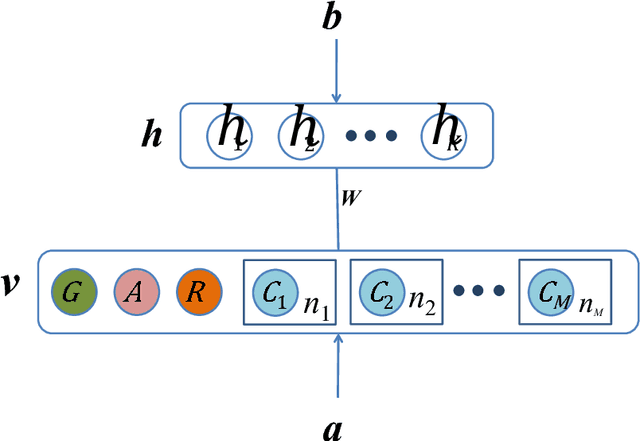
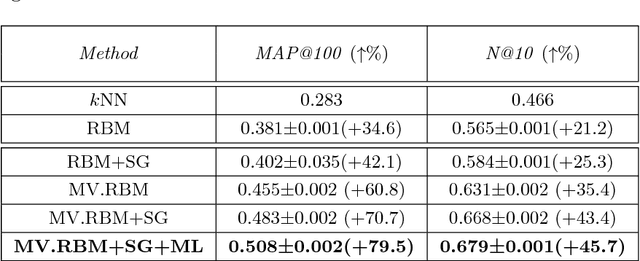
The analysis of mixed data has been raising challenges in statistics and machine learning. One of two most prominent challenges is to develop new statistical techniques and methodologies to effectively handle mixed data by making the data less heterogeneous with minimum loss of information. The other challenge is that such methods must be able to apply in large-scale tasks when dealing with huge amount of mixed data. To tackle these challenges, we introduce parameter sharing and balancing extensions to our recent model, the mixed-variate restricted Boltzmann machine (MV.RBM) which can transform heterogeneous data into homogeneous representation. We also integrate structured sparsity and distance metric learning into RBM-based models. Our proposed methods are applied in various applications including latent patient profile modelling in medical data analysis and representation learning for image retrieval. The experimental results demonstrate the models perform better than baseline methods in medical data and outperform state-of-the-art rivals in image dataset.
Graph Classification via Deep Learning with Virtual Nodes
Aug 14, 2017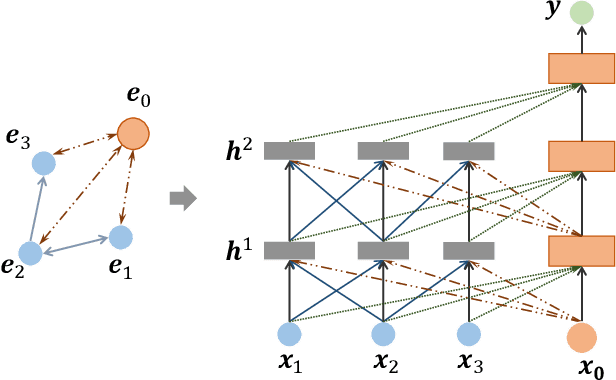

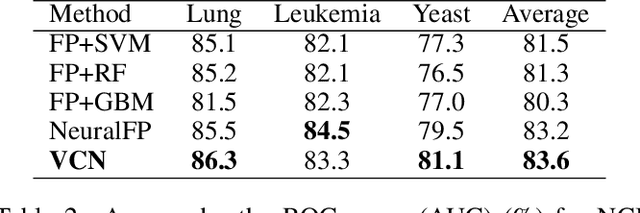
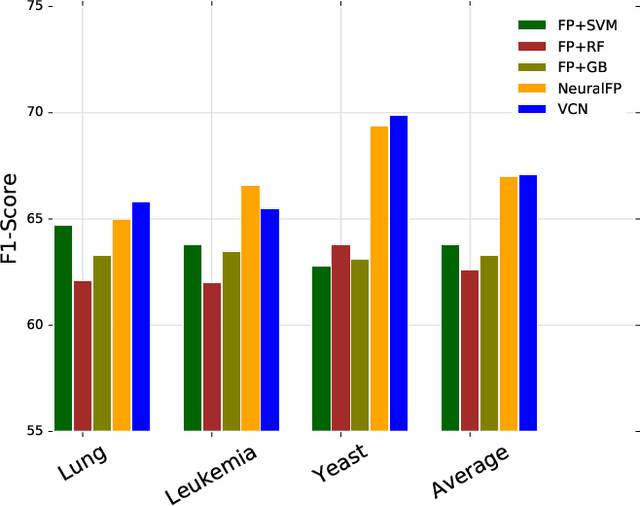
Learning representation for graph classification turns a variable-size graph into a fixed-size vector (or matrix). Such a representation works nicely with algebraic manipulations. Here we introduce a simple method to augment an attributed graph with a virtual node that is bidirectionally connected to all existing nodes. The virtual node represents the latent aspects of the graph, which are not immediately available from the attributes and local connectivity structures. The expanded graph is then put through any node representation method. The representation of the virtual node is then the representation of the entire graph. In this paper, we use the recently introduced Column Network for the expanded graph, resulting in a new end-to-end graph classification model dubbed Virtual Column Network (VCN). The model is validated on two tasks: (i) predicting bio-activity of chemical compounds, and (ii) finding software vulnerability from source code. Results demonstrate that VCN is competitive against well-established rivals.
Deep Learning to Attend to Risk in ICU
Jul 17, 2017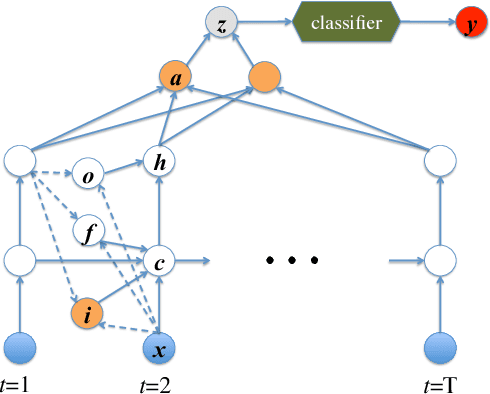
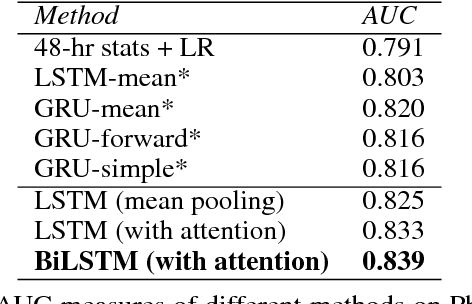
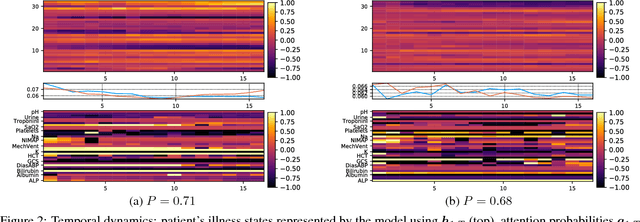
Modeling physiological time-series in ICU is of high clinical importance. However, data collected within ICU are irregular in time and often contain missing measurements. Since absence of a measure would signify its lack of importance, the missingness is indeed informative and might reflect the decision making by the clinician. Here we propose a deep learning architecture that can effectively handle these challenges for predicting ICU mortality outcomes. The model is based on Long Short-Term Memory, and has layered attention mechanisms. At the sensing layer, the model decides whether to observe and incorporate parts of the current measurements. At the reasoning layer, evidences across time steps are weighted and combined. The model is evaluated on the PhysioNet 2012 dataset showing competitive and interpretable results.
DeepCare: A Deep Dynamic Memory Model for Predictive Medicine
Apr 10, 2017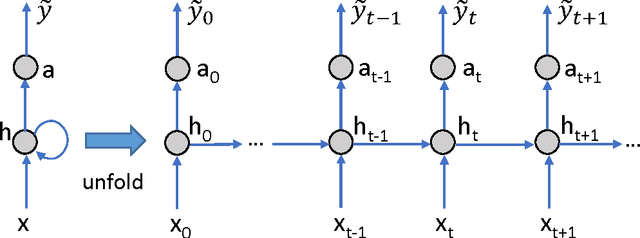
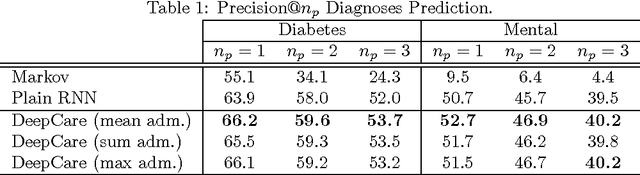
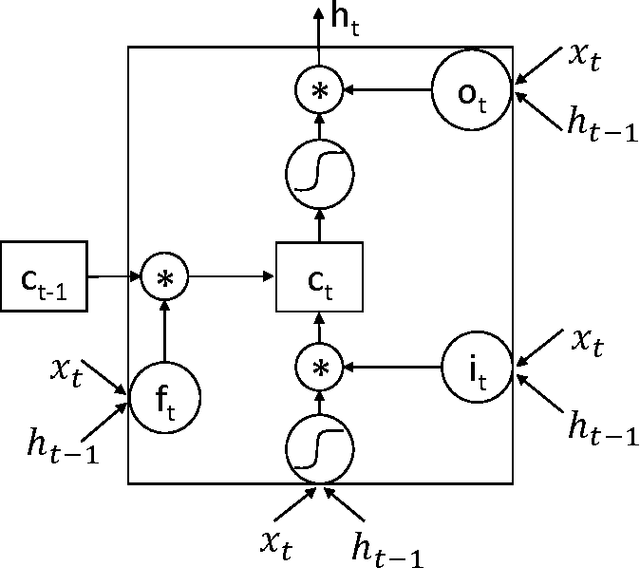
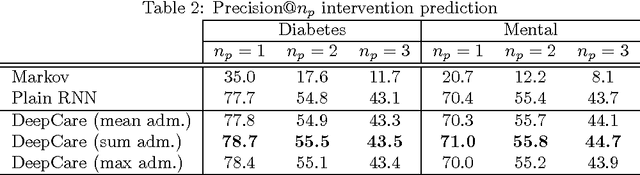
Personalized predictive medicine necessitates the modeling of patient illness and care processes, which inherently have long-term temporal dependencies. Healthcare observations, recorded in electronic medical records, are episodic and irregular in time. We introduce DeepCare, an end-to-end deep dynamic neural network that reads medical records, stores previous illness history, infers current illness states and predicts future medical outcomes. At the data level, DeepCare represents care episodes as vectors in space, models patient health state trajectories through explicit memory of historical records. Built on Long Short-Term Memory (LSTM), DeepCare introduces time parameterizations to handle irregular timed events by moderating the forgetting and consolidation of memory cells. DeepCare also incorporates medical interventions that change the course of illness and shape future medical risk. Moving up to the health state level, historical and present health states are then aggregated through multiscale temporal pooling, before passing through a neural network that estimates future outcomes. We demonstrate the efficacy of DeepCare for disease progression modeling, intervention recommendation, and future risk prediction. On two important cohorts with heavy social and economic burden -- diabetes and mental health -- the results show improved modeling and risk prediction accuracy.