 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Asynchronous and Sparse Human-Object Interaction in Videos
Mar 03, 2021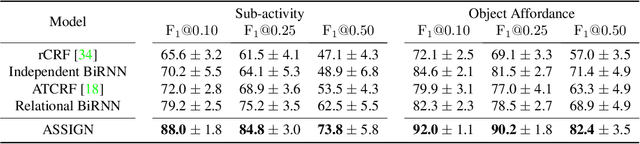
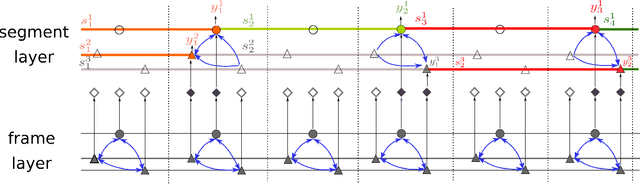
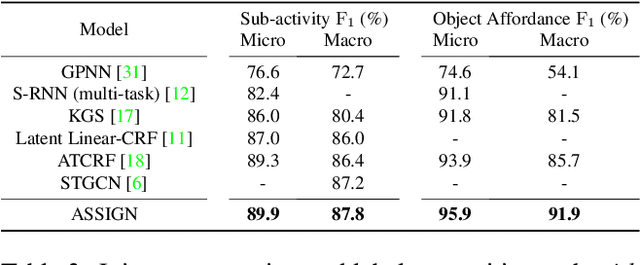
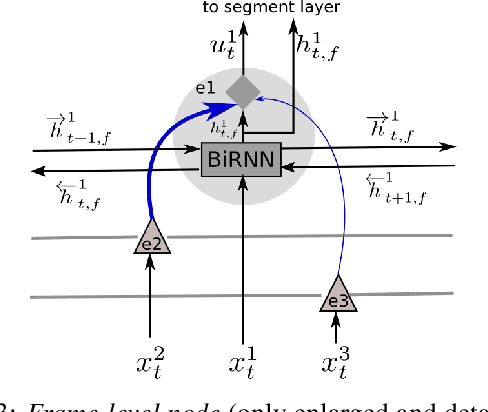
Human activities can be learned from video. With effective modeling it is possible to discover not only the action labels but also the temporal structures of the activities such as the progression of the sub-activities. Automatically recognizing such structure from raw video signal is a new capability that promises authentic modeling and successful recognition of human-object interactions. Toward this goal, we introduce Asynchronous-Sparse Interaction Graph Networks (ASSIGN), a recurrent graph network that is able to automatically detect the structure of interaction events associated with entities in a video scene. ASSIGN pioneers learning of autonomous behavior of video entities including their dynamic structure and their interaction with the coexisting neighbors. Entities' lives in our model are asynchronous to those of others therefore more flexible in adaptation to complex scenarios. Their interactions are sparse in time hence more faithful to the true underlying nature and more robust in inference and learning. ASSIGN is tested on human-object interaction recognition and shows superior performance in segmenting and labeling of human sub-activities and object affordances from raw videos. The native ability for discovering temporal structures of the model also eliminates the dependence on external segmentation that was previously mandatory for this task.
Semi-Supervised Learning with Variational Bayesian Inference and Maximum Uncertainty Regularization
Dec 03, 2020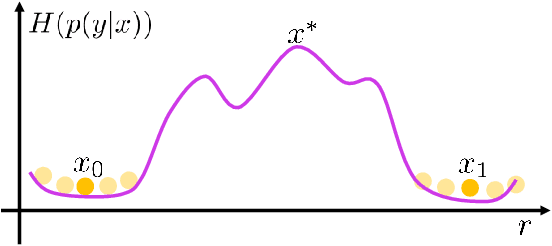
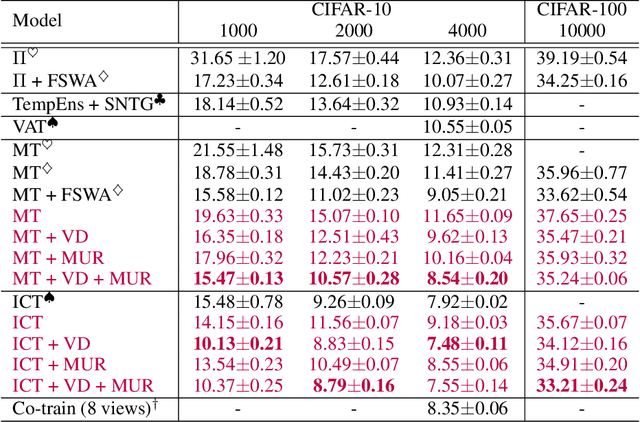
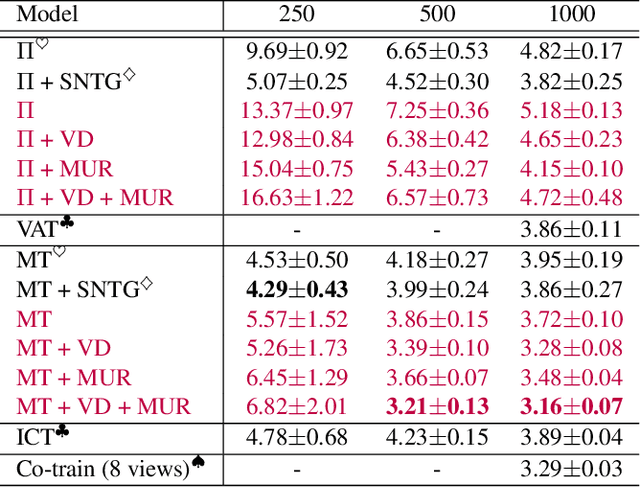
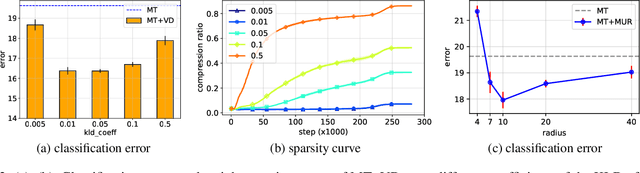
We propose two generic methods for improving semi-supervised learning (SSL). The first integrates weight perturbation (WP) into existing "consistency regularization" (CR) based methods. We implement WP by leveraging variational Bayesian inference (VBI). The second method proposes a novel consistency loss called "maximum uncertainty regularization" (MUR). While most consistency losses act on perturbations in the vicinity of each data point, MUR actively searches for "virtual" points situated beyond this region that cause the most uncertain class predictions. This allows MUR to impose smoothness on a wider area in the input-output manifold. Our experiments show clear improvements in classification errors of various CR based methods when they are combined with VBI or MUR or both.
Logically Consistent Loss for Visual Question Answering
Nov 19, 2020
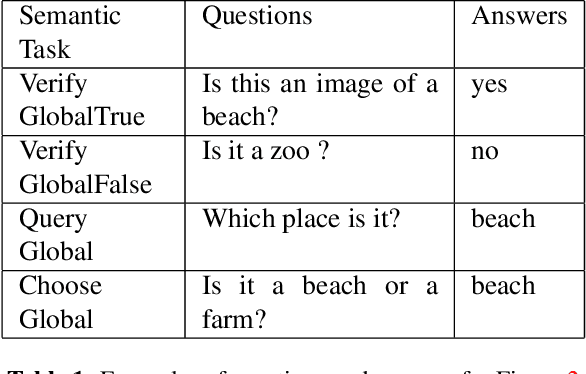
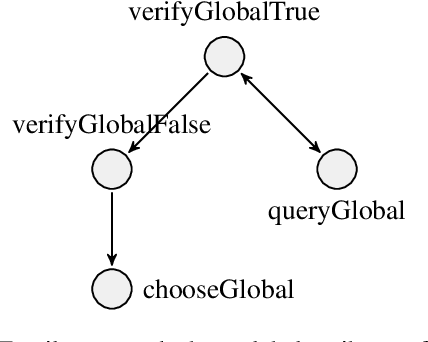
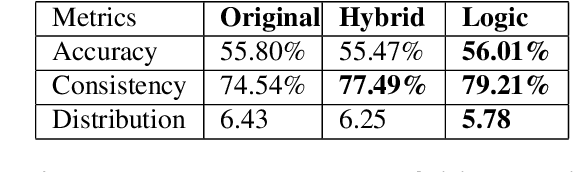
Given an image, a back-ground knowledge, and a set of questions about an object, human learners answer the questions very consistently regardless of question forms and semantic tasks. The current advancement in neural-network based Visual Question Answering (VQA), despite their impressive performance, cannot ensure such consistency due to identically distribution (i.i.d.) assumption. We propose a new model-agnostic logic constraint to tackle this issue by formulating a logically consistent loss in the multi-task learning framework as well as a data organisation called family-batch and hybrid-batch. To demonstrate usefulness of this proposal, we train and evaluate MAC-net based VQA machines with and without the proposed logically consistent loss and the proposed data organization. The experiments confirm that the proposed loss formulae and introduction of hybrid-batch leads to more consistency as well as better performance. Though the proposed approach is tested with MAC-net, it can be utilised in any other QA methods whenever the logical consistency between answers exist.
Goal-driven Long-Term Trajectory Prediction
Nov 06, 2020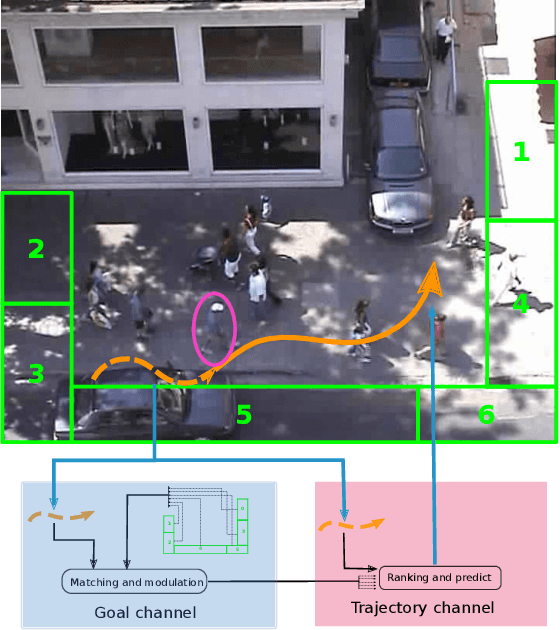
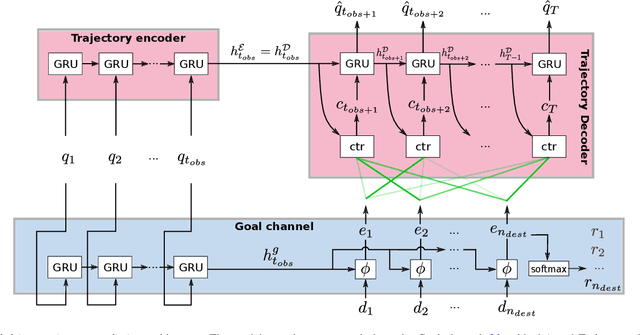
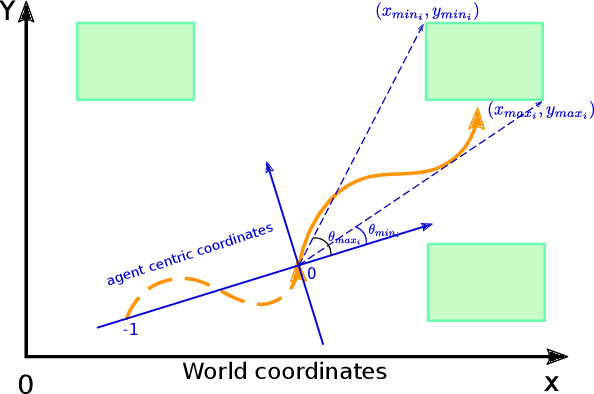
The prediction of humans' short-term trajectories has advanced significantly with the use of powerful sequential modeling and rich environment feature extraction. However, long-term prediction is still a major challenge for the current methods as the errors could accumulate along the way. Indeed, consistent and stable prediction far to the end of a trajectory inherently requires deeper analysis into the overall structure of that trajectory, which is related to the pedestrian's intention on the destination of the journey. In this work, we propose to model a hypothetical process that determines pedestrians' goals and the impact of such process on long-term future trajectories. We design Goal-driven Trajectory Prediction model - a dual-channel neural network that realizes such intuition. The two channels of the network take their dedicated roles and collaborate to generate future trajectories. Different than conventional goal-conditioned, planning-based methods, the model architecture is designed to generalize the patterns and work across different scenes with arbitrary geometrical and semantic structures. The model is shown to outperform the state-of-the-art in various settings, especially in large prediction horizons. This result is another evidence for the effectiveness of adaptive structured representation of visual and geometrical features in human behavior analysis.
Toward a Generalization Metric for Deep Generative Models
Nov 02, 2020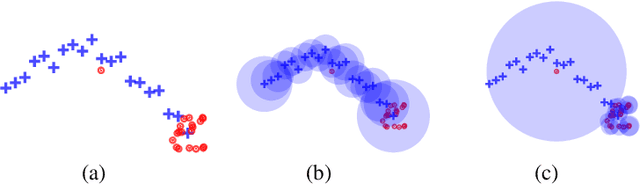

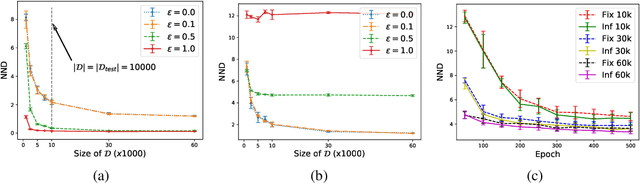
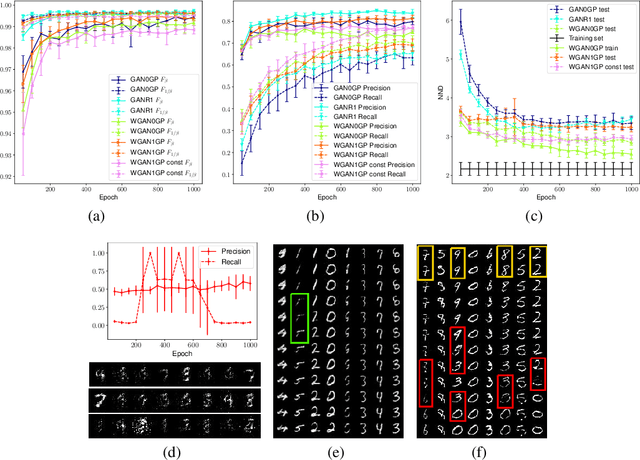
Measuring the generalization capacity of Deep Generative Models (DGMs) is difficult because of the curse of dimensionality. Evaluation metrics for DGMs like Inception Score, Frechet Inception Distance, Precision-Recall, and Neural Net Divergence try to estimate the distance between the generated distribution and the target distribution using a polynomial number of samples. These metrics are the target of researchers when designing new models. Despite the claims, it is still unclear how well they can measure the generalization capacity of a model. In this paper, we investigate the capacity of these metrics in measuring the generalization capacity. We introduce a framework for comparing the robustness of evaluation metrics. We show that better scores in these metrics do not imply better generalization. They can be fooled easily by a generator that memorizes a small subset of the training set. We propose a fix to the NND metric to make it more robust to noise in the generated data.
Hierarchical Conditional Relation Networks for Multimodal Video Question Answering
Oct 18, 2020
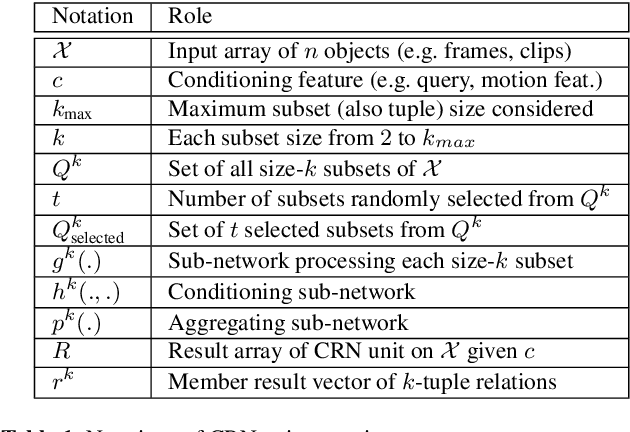

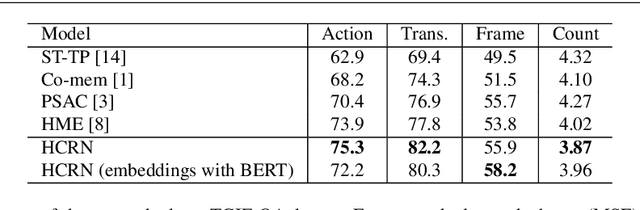
Video QA challenges modelers in multiple fronts. Modeling video necessitates building not only spatio-temporal models for the dynamic visual channel but also multimodal structures for associated information channels such as subtitles or audio. Video QA adds at least two more layers of complexity - selecting relevant content for each channel in the context of the linguistic query, and composing spatio-temporal concepts and relations in response to the query. To address these requirements, we start with two insights: (a) content selection and relation construction can be jointly encapsulated into a conditional computational structure, and (b) video-length structures can be composed hierarchically. For (a) this paper introduces a general-reusable neural unit dubbed Conditional Relation Network (CRN) taking as input a set of tensorial objects and translating into a new set of objects that encode relations of the inputs. The generic design of CRN helps ease the common complex model building process of Video QA by simple block stacking with flexibility in accommodating input modalities and conditioning features across both different domains. As a result, we realize insight (b) by introducing Hierarchical Conditional Relation Networks (HCRN) for Video QA. The HCRN primarily aims at exploiting intrinsic properties of the visual content of a video and its accompanying channels in terms of compositionality, hierarchy, and near and far-term relation. HCRN is then applied for Video QA in two forms, short-form where answers are reasoned solely from the visual content, and long-form where associated information, such as subtitles, presented. Our rigorous evaluations show consistent improvements over SOTAs on well-studied benchmarks including large-scale real-world datasets such as TGIF-QA and TVQA, demonstrating the strong capabilities of our CRN unit and the HCRN for complex domains such as Video QA.
GEFA: Early Fusion Approach in Drug-Target Affinity Prediction
Sep 28, 2020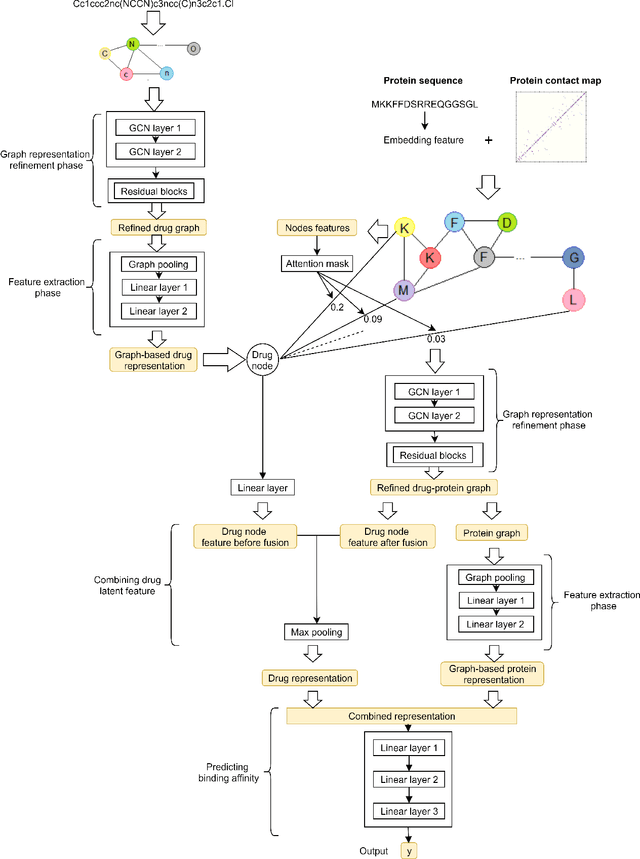
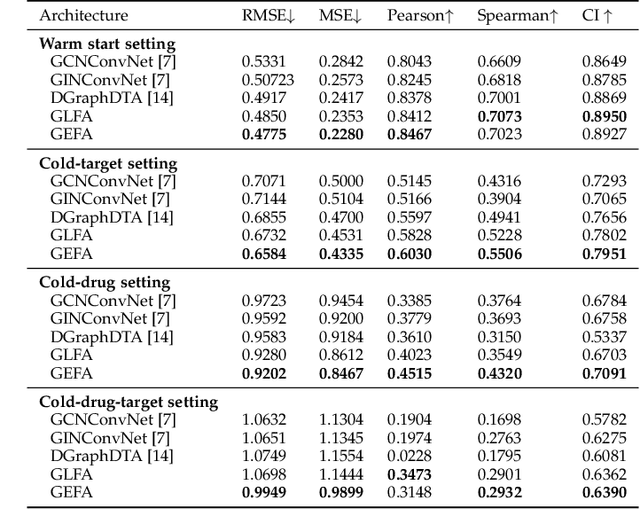
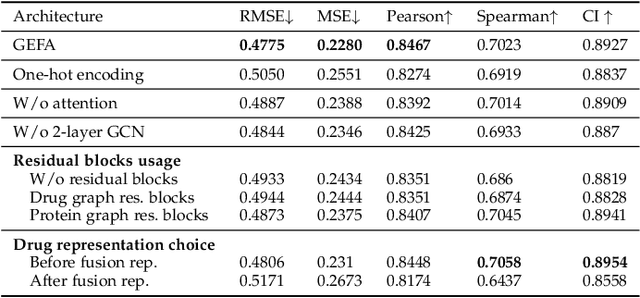

Predicting the interaction between a compound and a target is crucial for rapid drug repurposing. Deep learning has been successfully applied in drug-target affinity (DTA) problem. However, previous deep learning-based methods ignore modeling the direct interactions between drug and protein residues. This would lead to inaccurate learning of target representation which may change due to the drug binding effects. In addition, previous DTA methods learn protein representation solely based on a small number of protein sequences in DTA datasets while neglecting the use of proteins outside of the DTA datasets. We propose GEFA (Graph Early Fusion Affinity), a novel graph-in-graph neural network with attention mechanism to address the changes in target representation because of the binding effects. Specifically, a drug is modeled as a graph of atoms, which then serves as a node in a larger graph of residues-drug complex. The resulting model is an expressive deep nested graph neural network. We also use pre-trained protein representation powered by the recent effort of learning contextualized protein representation. The experiments are conducted under different settings to evaluate scenarios such as novel drugs or targets. The results demonstrate the effectiveness of the pre-trained protein embedding and the advantages our GEFA in modeling the nested graph for drug-target interaction.
Unsupervised Anomaly Detection on Temporal Multiway Data
Sep 20, 2020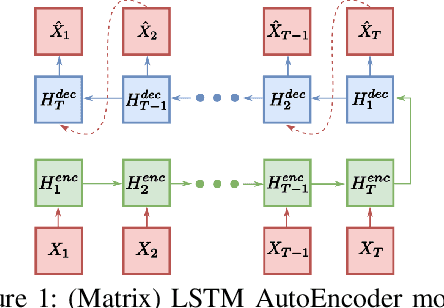
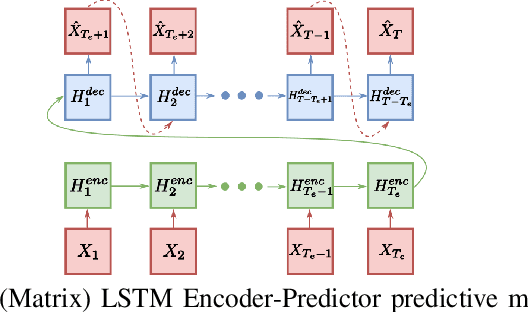
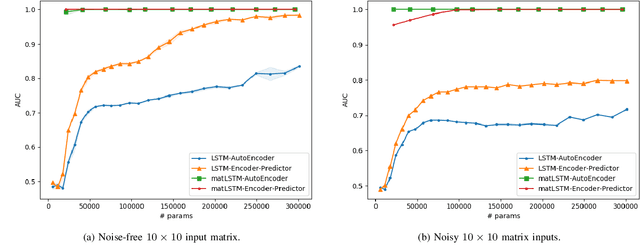
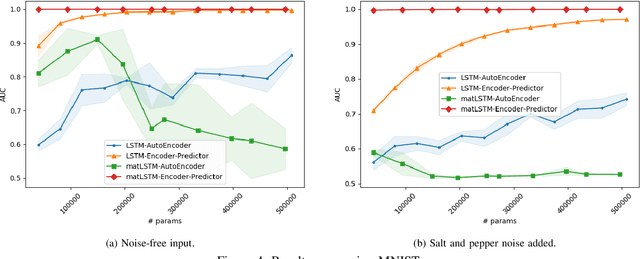
Temporal anomaly detection looks for irregularities over space-time. Unsupervised temporal models employed thus far typically work on sequences of feature vectors, and much less on temporal multiway data. We focus our investigation on two-way data, in which a data matrix is observed at each time step. Leveraging recent advances in matrix-native recurrent neural networks, we investigated strategies for data arrangement and unsupervised training for temporal multiway anomaly detection. These include compressing-decompressing, encoding-predicting, and temporal data differencing. We conducted a comprehensive suite of experiments to evaluate model behaviors under various settings on synthetic data, moving digits, and ECG recordings. We found interesting phenomena not previously reported. These include the capacity of the compact matrix LSTM to compress noisy data near perfectly, making the strategy of compressing-decompressing data ill-suited for anomaly detection under the noise. Also, long sequence of vectors can be addressed directly by matrix models that allow very long context and multiple step prediction. Overall, the encoding-predicting strategy works very well for the matrix LSTMs in the conducted experiments, thanks to its compactness and better fit to the data dynamics.
Theory of Mind with Guilt Aversion Facilitates Cooperative Reinforcement Learning
Sep 16, 2020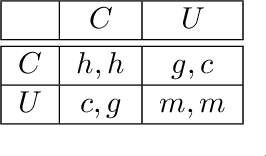
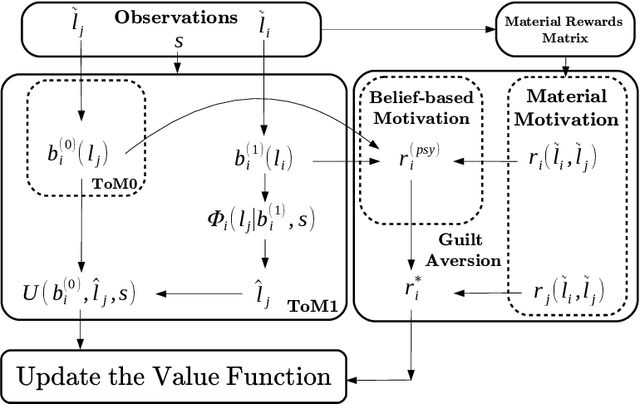
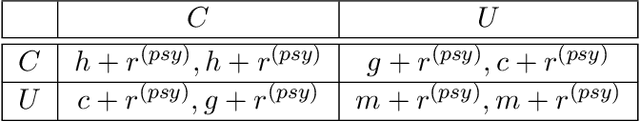
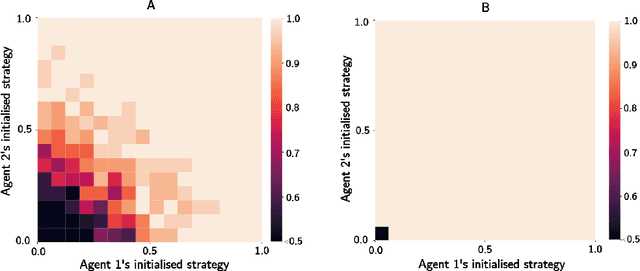
Guilt aversion induces experience of a utility loss in people if they believe they have disappointed others, and this promotes cooperative behaviour in human. In psychological game theory, guilt aversion necessitates modelling of agents that have theory about what other agents think, also known as Theory of Mind (ToM). We aim to build a new kind of affective reinforcement learning agents, called Theory of Mind Agents with Guilt Aversion (ToMAGA), which are equipped with an ability to think about the wellbeing of others instead of just self-interest. To validate the agent design, we use a general-sum game known as Stag Hunt as a test bed. As standard reinforcement learning agents could learn suboptimal policies in social dilemmas like Stag Hunt, we propose to use belief-based guilt aversion as a reward shaping mechanism. We show that our belief-based guilt averse agents can efficiently learn cooperative behaviours in Stag Hunt Games.
Learning to Abstract and Predict Human Actions
Aug 20, 2020
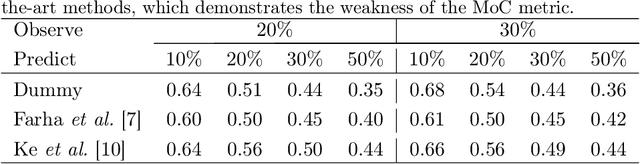
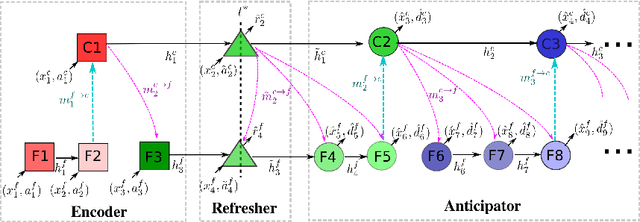
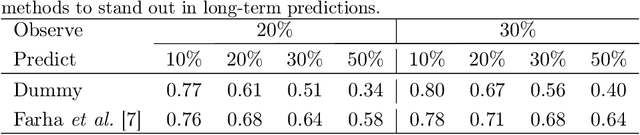
Human activities are naturally structured as hierarchies unrolled over time. For action prediction, temporal relations in event sequences are widely exploited by current methods while their semantic coherence across different levels of abstraction has not been well explored. In this work we model the hierarchical structure of human activities in videos and demonstrate the power of such structure in action prediction. We propose Hierarchical Encoder-Refresher-Anticipator, a multi-level neural machine that can learn the structure of human activities by observing a partial hierarchy of events and roll-out such structure into a future prediction in multiple levels of abstraction. We also introduce a new coarse-to-fine action annotation on the Breakfast Actions videos to create a comprehensive, consistent, and cleanly structured video hierarchical activity dataset. Through our experiments, we examine and rethink the settings and metrics of activity prediction tasks toward unbiased evaluation of prediction systems, and demonstrate the role of hierarchical modeling toward reliable and detailed long-term action forecasting.