 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuCEPT: Locally Discover Neural Networks' Mechanism via Critical Neurons Identification with Precision Guarantee
Sep 18, 2022

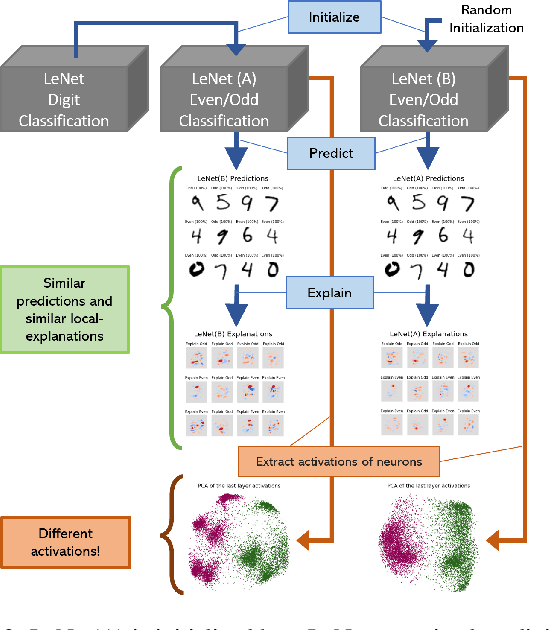
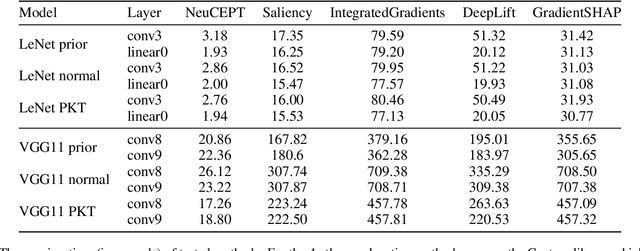
Despite recent studies on understanding deep neural networks (DNNs), there exists numerous questions on how DNNs generate their predictions. Especially, given similar predictions on different input samples, are the underlying mechanisms generating those predictions the same? In this work, we propose NeuCEPT, a method to locally discover critical neurons that play a major role in the model's predictions and identify model's mechanisms in generating those predictions. We first formulate a critical neurons identification problem as maximizing a sequence of mutual-information objectives and provide a theoretical framework to efficiently solve for critical neurons while keeping the precision under control. NeuCEPT next heuristically learns different model's mechanisms in an unsupervised manner. Our experimental results show that neurons identified by NeuCEPT not only have strong influence on the model's predictions but also hold meaningful information about model's mechanisms.
Evaluating Explainers via Perturbation
Jun 05, 2019
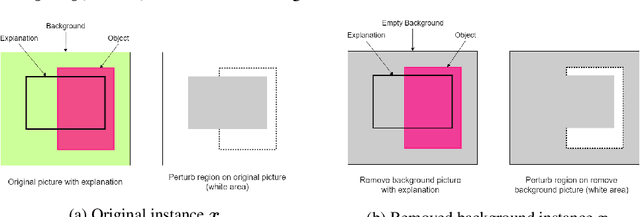
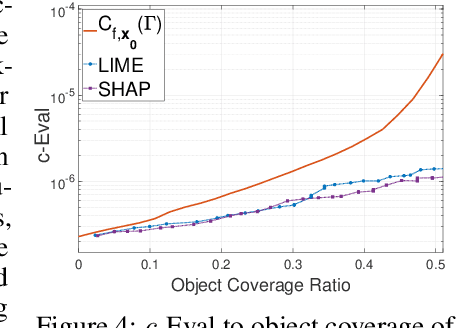
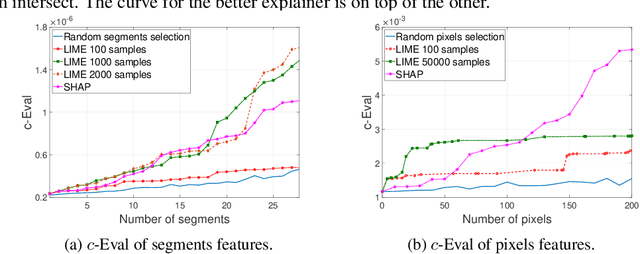
Due to high complexity of many modern machine learning models such as deep convolutional networks, understanding the cause of model's prediction is critical. Many explainers have been designed to give us more insights on the decision of complex classifiers. However, there is no common ground on evaluating the quality of different classification methods. Motivated by the needs for comprehensive evaluation, we introduce the c-Eval metric and the corresponding framework to quantify the explainer's quality on feature-based explainers of machine learning image classifiers. Given a prediction and the corresponding explanation on that prediction, c-Eval is the minimum-power perturbation that successfully alters the prediction while keeping the explanation's features unchanged. We also provide theoretical analysis linking the proposed parameter with the portion of predicted object covered by the explanation. Using a heuristic approach, we introduce the c-Eval plot, which not only displays a strong connection between c-Eval and explainers' quality, but also serves as a low-complexity approach of assessing explainers. We finally conduct extensive experiments of explainers on three different datasets in order to support the adoption of c-Eval in evaluating explainers' performance.