 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Race Detection Using Large Language Models
Aug 15, 2023



Large language models (LLMs) are demonstrating significant promise as an alternate strategy to facilitate analyses and optimizations of high-performance computing programs, circumventing the need for resource-intensive manual tool creation. In this paper, we explore a novel LLM-based data race detection approach combining prompting engineering and fine-tuning techniques. We create a dedicated dataset named DRB-ML, which is derived from DataRaceBench, with fine-grain labels showing the presence of data race pairs and their associated variables, line numbers, and read/write information. DRB-ML is then used to evaluate representative LLMs and fine-tune open-source ones. Our experiment shows that LLMs can be a viable approach to data race detection. However, they still cannot compete with traditional data race detection tools when we need detailed information about variable pairs causing data races.
LM4HPC: Towards Effective Language Model Application in High-Performance Computing
Jun 26, 2023In recent years, language models (LMs), such as GPT-4, have been widely used in multiple domains, including natural language processing, visualization, and so on. However, applying them for analyzing and optimizing high-performance computing (HPC) software is still challenging due to the lack of HPC-specific support. In this paper, we design the LM4HPC framework to facilitate the research and development of HPC software analyses and optimizations using LMs. Tailored for supporting HPC datasets, AI models, and pipelines, our framework is built on top of a range of components from different levels of the machine learning software stack, with Hugging Face-compatible APIs. Using three representative tasks, we evaluated the prototype of our framework. The results show that LM4HPC can help users quickly evaluate a set of state-of-the-art models and generate insightful leaderboards.
Structured Thoughts Automaton: First Formalized Execution Model for Auto-Regressive Language Models
Jun 16, 2023In recent months, Language Models (LMs) have become a part of daily discourse, with focus on OpenAI and the potential of Artificial General Intelligence (AGI). Furthermore, the leaking of LLama's weights to the public has led to an influx of innovations demonstrating the impressive capabilities of generative LMs. While we believe that AGI is still a distant goal, we recognize the potential of LMs in solving tasks such as searching complex documents, compiling reports with basic analysis, and providing assistance in problem-solving. In this paper, we propose formalizing the execution model of language models. We investigate current execution models, to find that this formalism has received little attention, and present our contribution: the first formalized execution model for LMs. We introduce a new algorithm for sampling the predictions of LMs, which we use to build a reliable and inspectable execution model. We introduce a low-level language to write "cognitive program" for this execution model. We hope to shed light on the need for execution models for LMs and encourage further research in this area.
Making Machine Learning Datasets and Models FAIR for HPC: A Methodology and Case Study
Nov 03, 2022



The FAIR Guiding Principles aim to improve the findability, accessibility, interoperability, and reusability of digital content by making them both human and machine actionable. However, these principles have not yet been broadly adopted in the domain of machine learning-based program analyses and optimizations for High-Performance Computing (HPC). In this paper, we design a methodology to make HPC datasets and machine learning models FAIR after investigating existing FAIRness assessment and improvement techniques. Our methodology includes a comprehensive, quantitative assessment for elected data, followed by concrete, actionable suggestions to improve FAIRness with respect to common issues related to persistent identifiers, rich metadata descriptions, license and provenance information. Moreover, we select a representative training dataset to evaluate our methodology. The experiment shows the methodology can effectively improve the dataset and model's FAIRness from an initial score of 19.1% to the final score of 83.0%.
Finding Reusable Machine Learning Components to Build Programming Language Processing Pipelines
Aug 11, 2022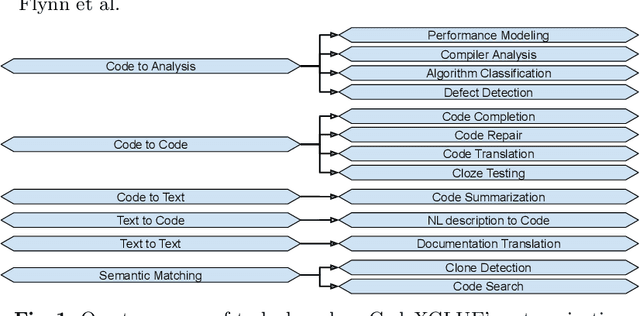
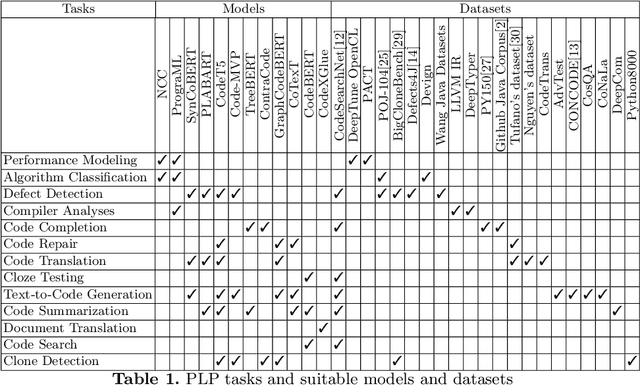
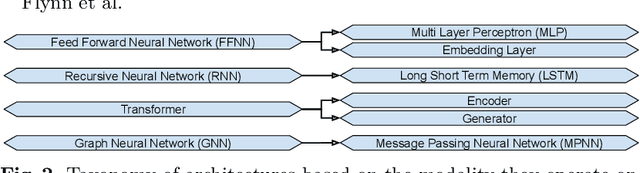
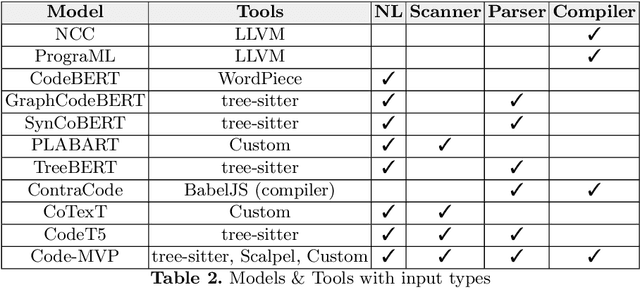
Programming Language Processing (PLP) using machine learning has made vast improvements in the past few years. Increasingly more people are interested in exploring this promising field. However, it is challenging for new researchers and developers to find the right components to construct their own machine learning pipelines, given the diverse PLP tasks to be solved, the large number of datasets and models being released, and the set of complex compilers or tools involved. To improve the findability, accessibility, interoperability and reusability (FAIRness) of machine learning components, we collect and analyze a set of representative papers in the domain of machine learning-based PLP. We then identify and characterize key concepts including PLP tasks, model architectures and supportive tools. Finally, we show some example use cases of leveraging the reusable components to construct machine learning pipelines to solve a set of PLP tasks.