 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Form Generalized Hamiltonian Learning
Apr 11, 2021
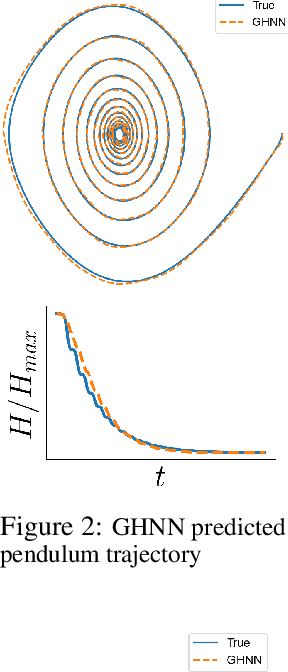


We present a method for learning generalized Hamiltonian decompositions of ordinary differential equations given a set of noisy time series measurements. Our method simultaneously learns a continuous time model and a scalar energy function for a general dynamical system. Learning predictive models in this form allows one to place strong, high-level, physics inspired priors onto the form of the learnt governing equations for general dynamical systems. Moreover, having shown how our method extends and unifies some previous work in deep learning with physics inspired priors, we present a novel method for learning continuous time models from the weak form of the governing equations which is less computationally taxing than standard adjoint methods.
* 34th Conference on Neural Information Processing Systems, 18 pages
Quadruply Stochastic Gaussian Processes
Jun 04, 2020
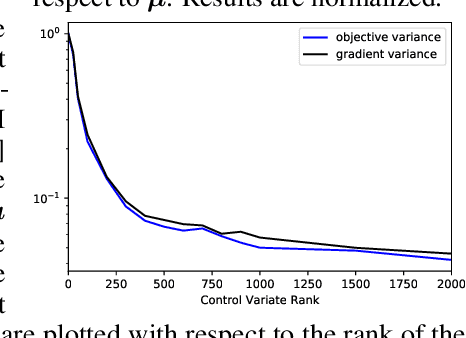
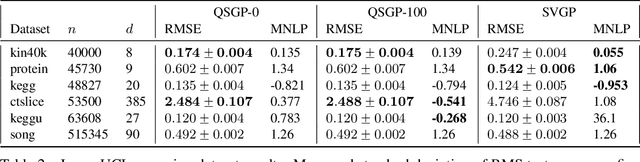
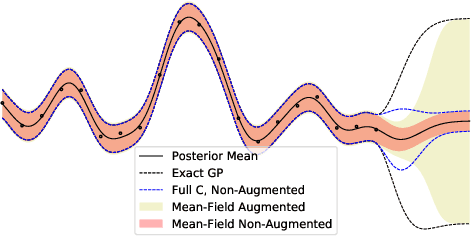
We introduce a stochastic variational inference procedure for training scalable Gaussian process (GP) models whose per-iteration complexity is independent of both the number of training points, $n$, and the number basis functions used in the kernel approximation, $m$. Our central contributions include an unbiased stochastic estimator of the evidence lower bound (ELBO) for a Gaussian likelihood, as well as a stochastic estimator that lower bounds the ELBO for several other likelihoods such as Laplace and logistic. Independence of the stochastic optimization update complexity on $n$ and $m$ enables inference on huge datasets using large capacity GP models. We demonstrate accurate inference on large classification and regression datasets using GPs and relevance vector machines with up to $m = 10^7$ basis functions.
Discretely Relaxing Continuous Variables for tractable Variational Inference
Oct 31, 2018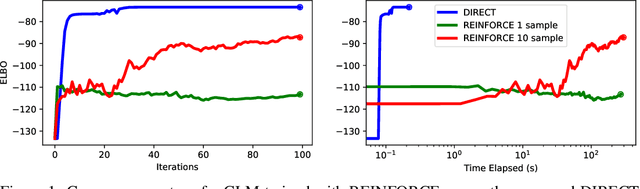
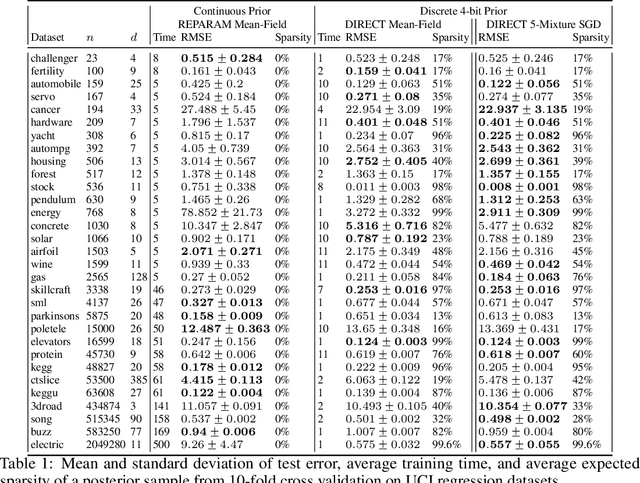
We explore a new research direction in Bayesian variational inference with discrete latent variable priors where we exploit Kronecker matrix algebra for efficient and exact computations of the evidence lower bound (ELBO). The proposed "DIRECT" approach has several advantages over its predecessors; (i) it can exactly compute ELBO gradients (i.e. unbiased, zero-variance gradient estimates), eliminating the need for high-variance stochastic gradient estimators and enabling the use of quasi-Newton optimization methods; (ii) its training complexity is independent of the number of training points, permitting inference on large datasets; and (iii) its posterior samples consist of sparse and low-precision quantized integers which permit fast inference on hardware limited devices. In addition, our DIRECT models can exactly compute statistical moments of the parameterized predictive posterior without relying on Monte Carlo sampling. The DIRECT approach is not practical for all likelihoods, however, we identify a popular model structure which is practical, and demonstrate accurate inference using latent variables discretized as extremely low-precision 4-bit quantized integers. While the ELBO computations considered in the numerical studies require over $10^{2352}$ log-likelihood evaluations, we train on datasets with over two-million points in just seconds.
Exploiting Structure for Fast Kernel Learning
Aug 09, 2018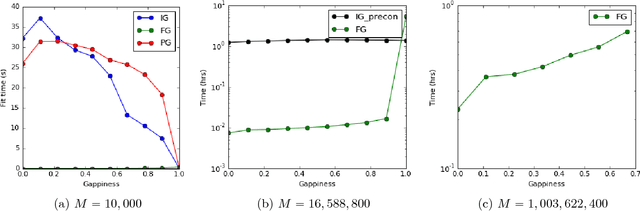
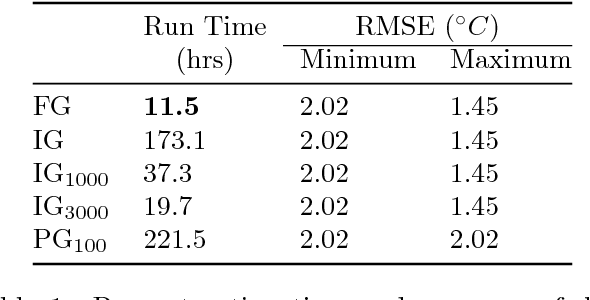
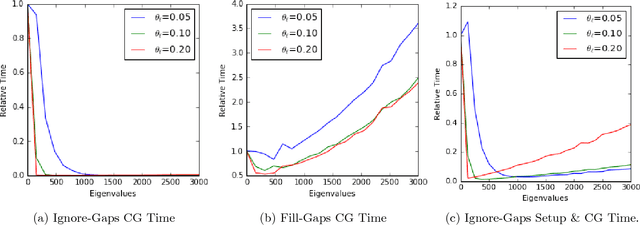
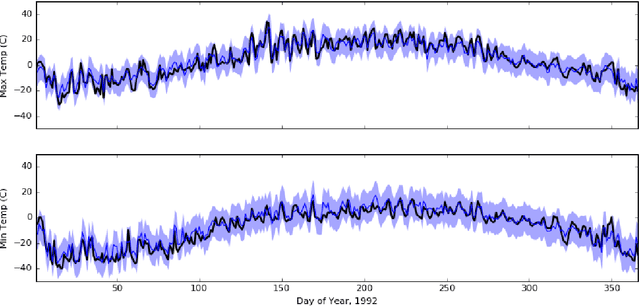
We propose two methods for exact Gaussian process (GP) inference and learning on massive image, video, spatial-temporal, or multi-output datasets with missing values (or "gaps") in the observed responses. The first method ignores the gaps using sparse selection matrices and a highly effective low-rank preconditioner is introduced to accelerate computations. The second method introduces a novel approach to GP training whereby response values are inferred on the gaps before explicitly training the model. We find this second approach to be greatly advantageous for the class of problems considered. Both of these novel approaches make extensive use of Kronecker matrix algebra to design massively scalable algorithms which have low memory requirements. We demonstrate exact GP inference for a spatial-temporal climate modelling problem with 3.7 million training points as well as a video reconstruction problem with 1 billion points.
Scalable Gaussian Processes with Grid-Structured Eigenfunctions (GP-GRIEF)
Aug 01, 2018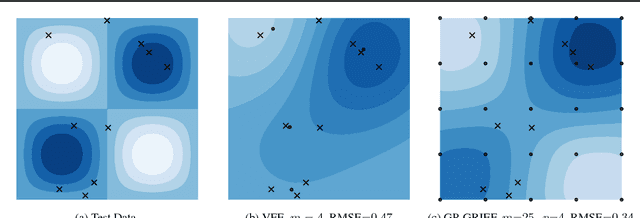
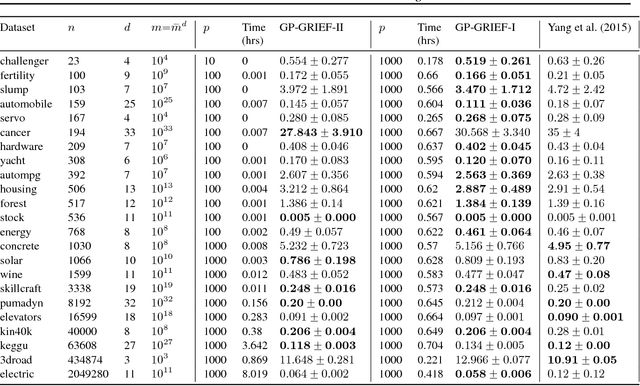
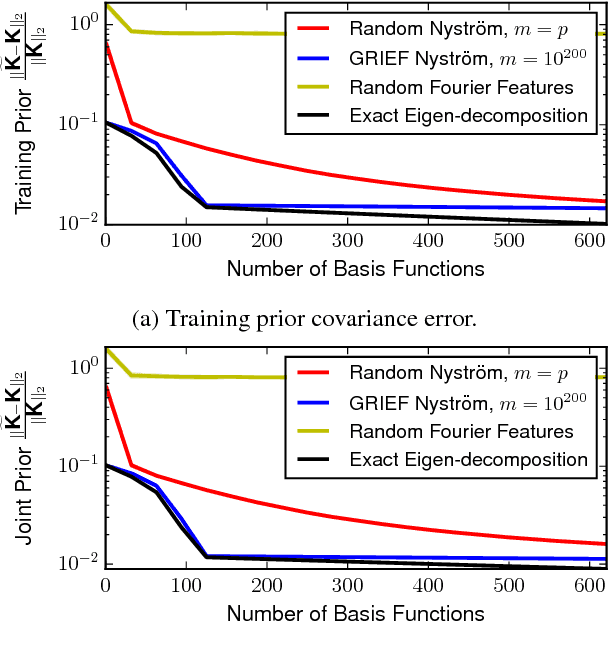
We introduce a kernel approximation strategy that enables computation of the Gaussian process log marginal likelihood and all hyperparameter derivatives in $\mathcal{O}(p)$ time. Our GRIEF kernel consists of $p$ eigenfunctions found using a Nystrom approximation from a dense Cartesian product grid of inducing points. By exploiting algebraic properties of Kronecker and Khatri-Rao tensor products, computational complexity of the training procedure can be practically independent of the number of inducing points. This allows us to use arbitrarily many inducing points to achieve a globally accurate kernel approximation, even in high-dimensional problems. The fast likelihood evaluation enables type-I or II Bayesian inference on large-scale datasets. We benchmark our algorithms on real-world problems with up to two-million training points and $10^{33}$ inducing points.