 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinocular disparity as an explanation for the moon illusion
Sep 28, 2016


We present another explanation for the moon illusion, the phenomenon in which the moon looks larger near the horizon than near the zenith. In our model of the moon illusion, the sky is considered a spatially-contiguous and geometrically-smooth surface. When an object such as the moon breaks the contiguity of the surface, instead of perceiving the object as appearing through a hole in the surface, humans perceive an occlusion of the surface. Binocular vision dictates that the moon is distant, but this perception model contradicts our binocular vision, dictating that the moon is closer than the sky. To resolve the contradiction, the brain distorts the projections of the moon to increase the binocular disparity, which results in an increase in the perceived size of the moon. The degree of distortion depends upon the apparent distance to the sky, which is influenced by the surrounding objects and the condition of the sky. As the apparent distance to the sky decreases, the illusion becomes stronger. At the horizon, apparent distance to the sky is minimal, whereas at the zenith, few distance cues are present, causing difficulty with distance estimation and weakening the illusion.
Grouping and Recognition of Dot Patterns with Straight Offset Polygons
Mar 02, 2015

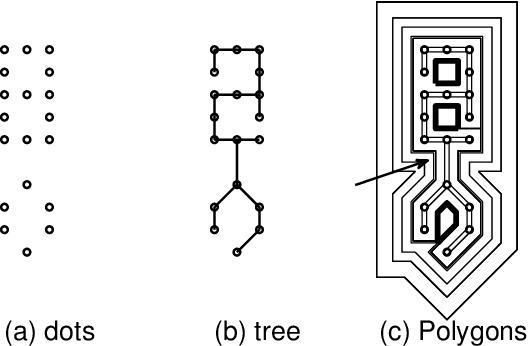

When the boundary of a familiar object is shown by a series of isolated dots, humans can often recognize the object with ease. This ability can be sustained with addition of distracting dots around the object. However, such capability has not been reproduced algorithmically on computers. We introduce a new algorithm that groups a set of dots into multiple non-disjoint subsets. It connects the dots into a spanning tree using the proximity cue. It then applies the straight polygon transformation to an initial polygon derived from the spanning tree. The straight polygon divides the space into polygons recursively and each polygon can be viewed as grouping of a subset of the dots. The number of polygons generated is O($n$). We also introduce simple shape selection and recognition algorithms that can be applied to the grouping result. We used both natural and synthetic images to show effectiveness of these algorithms.
Shape Reconstruction and Recognition with Isolated Non-directional Cues
May 10, 2013



The paper investigates a hypothesis that our visual system groups visual cues based on how they form a surface, or more specifically triangulation derived from the visual cues. To test our hypothesis, we compare shape recognition with three different representations of visual cues: a set of isolated dots delineating the outline of the shape, a set of triangles obtained from Delaunay triangulation of the set of dots, and a subset of Delaunay triangles excluding those outside of the shape. Each participant was assigned to one particular representation type and increased the number of dots (and consequentially triangles) until the underlying shape could be identified. We compare the average number of dots needed for identification among three types of representations. Our hypothesis predicts that the results from the three representations will be similar. However, they show statistically significant differences. The paper also presents triangulation based algorithms for reconstruction and recognition of a shape from a set of isolated dots. Experiments showed that the algorithms were more effective and perceptually agreeable than similar contour based ones. From these experiments, we conclude that triangulation does affect our shape recognition. However, the surface based approach presents a number of computational advantages over the contour based one and should be studied further.
Contour Completion Around a Fixation Point
Aug 16, 2012
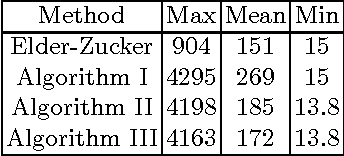


The paper presents two edge grouping algorithms for finding a closed contour starting from a particular edge point and enclosing a fixation point. Both algorithms search a shortest simple cycle in \textit{an angularly ordered graph} derived from an edge image where a vertex is an end point of a contour fragment and an undirected arc is drawn between a pair of end-points whose visual angle from the fixation point is less than a threshold value, which is set to $\pi/2$ in our experiments. The first algorithm restricts the search space by disregarding arcs that cross the line extending from the fixation point to the starting point. The second algorithm improves the solution of the first algorithm in a greedy manner. The algorithms were tested with a large number of natural images with manually placed fixation and starting points. The results are promising.
Non-Gaussian Scale Space Filtering with 2 by 2 Matrix of Linear Filters
Oct 04, 2011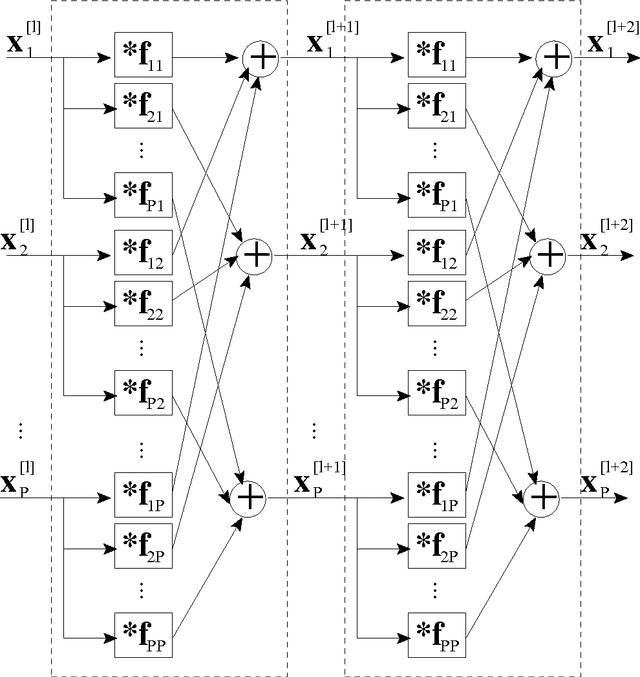



Construction of a scale space with a convolution filter has been studied extensively in the past. It has been proven that the only convolution kernel that satisfies the scale space requirements is a Gaussian type. In this paper, we consider a matrix of convolution filters introduced in [1] as a building kernel for a scale space, and shows that we can construct a non-Gaussian scale space with a $2\times 2$ matrix of filters. The paper derives sufficient conditions for the matrix of filters for being a scale space kernel, and present some numerical demonstrations.