 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Multi-Task Learning for Adjustable Joint Noise Reduction and Hearing Loss Compensation
Mar 20, 2026A multi-task learning framework is proposed for optimizing a single deep neural network (DNN) for joint noise reduction (NR) and hearing loss compensation (HLC). A distinct training objective is defined for each task, and the DNN predicts two time-frequency masks. During inference, the amounts of NR and HLC can be adjusted independently by exponentiating each mask before combining them. In contrast to recent approaches that rely on training an auditory-model emulator to define a differentiable training objective, we propose an auditory model that is inherently differentiable, thus allowing end-to-end optimization. The audiogram is provided as an input to the DNN, thereby enabling listener-specific personalization without the need for retraining. Results show that the proposed approach not only allows adjusting the amounts of NR and HLC individually, but also improves objective metrics compared to optimizing a single training objective. It also outperforms a cascade of two DNNs that were separately trained for NR and HLC, and shows competitive HLC performance compared to a traditional hearing-aid prescription. To the best of our knowledge, this is the first study that uses an auditory model to train a single DNN for both NR and HLC across a wide range of listener profiles.
A comparative study of eight human auditory models of monaural processing
Jul 05, 2021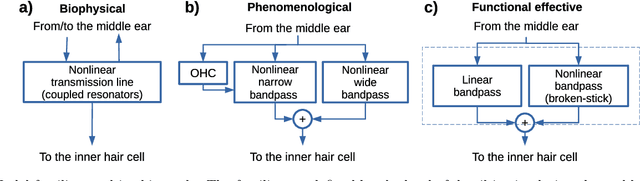
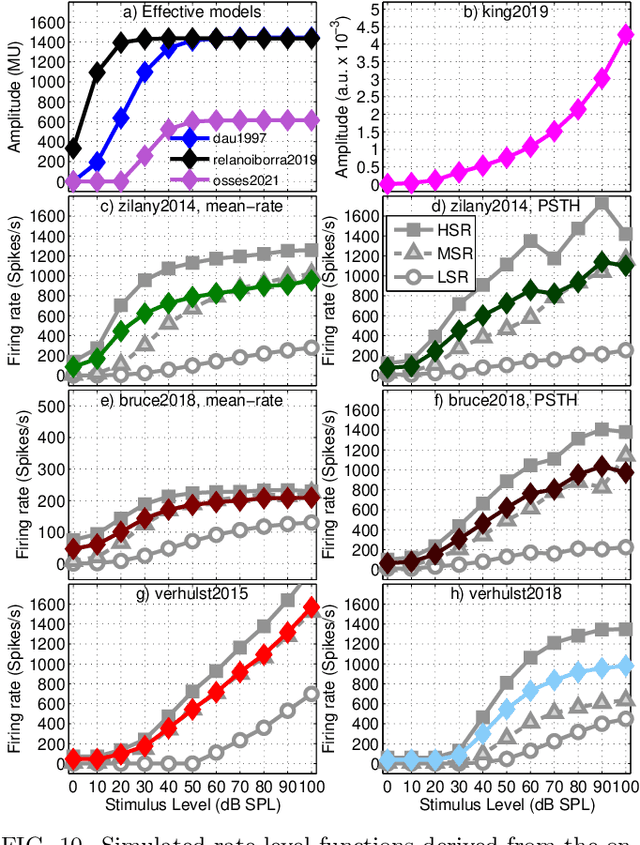
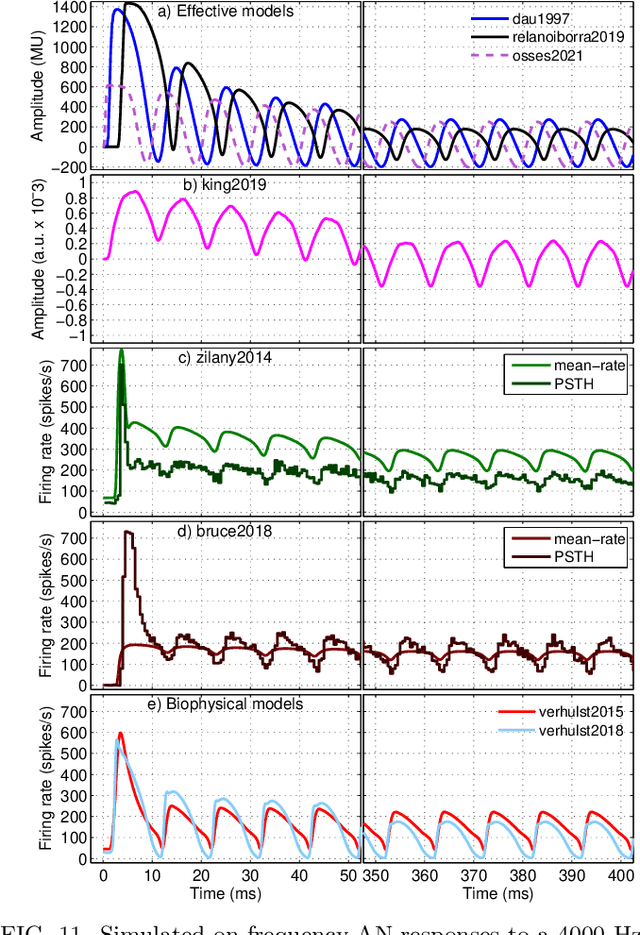
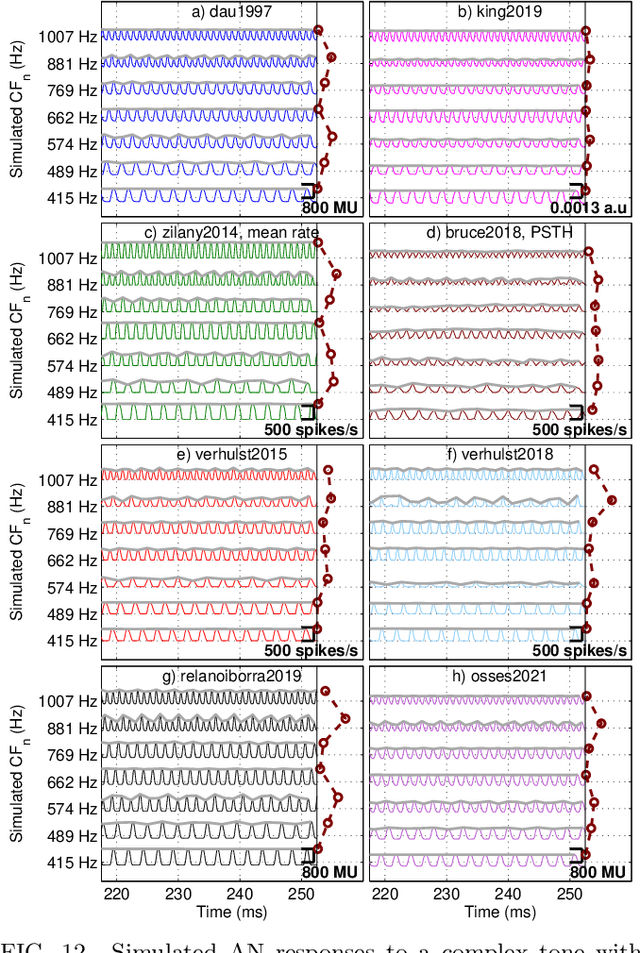
A number of auditory models have been developed using diverging approaches, either physiological or perceptual, but they share comparable stages of signal processing, as they are inspired by the same constitutive parts of the auditory system. We compare eight monaural models that are openly accessible in the Auditory Modelling Toolbox. We discuss the considerations required to make the model outputs comparable to each other, as well as the results for the following model processing stages or their equivalents: outer and middle ear, cochlear filter bank, inner hair cell, auditory nerve synapse, cochlear nucleus, and inferior colliculus. The discussion includes some practical considerations related to the use of monaural stages in binaural frameworks.