 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Weighted Maximum Representative Subsampling
Mar 01, 2026In the social sciences, it is often necessary to debias studies and surveys before valid conclusions can be drawn. Debiasing algorithms enable the computational removal of bias using sample weights. However, an issue arises when only a subset of features is highly biased, while the rest is already representative. Algorithms need to strongly alter the sample distribution to manage a few highly biased features, which can in turn introduce bias into already representative variables. To address this issue, we developed a method that uses feature weights to minimize the impact of highly biased features on the computation of sample weights. Our algorithm is based on Maximum Representative Subsampling (MRS), which debiases datasets by aligning a non-representative sample with a representative one through iterative removal of elements to create a representative subsample. The new algorithm, named feature-weighted MRS (FW-MRS), decreases the emphasis on highly biased features, allowing it to retain more instances for downstream tasks. The feature weights are derived from the feature importance of a domain classifier trained to differentiate between the representative and non-representative datasets. We validated FW-MRS using eight tabular datasets, each of which we artificially biased. Biased features can be important for downstream tasks, and focusing less on them could lead to a decline in generalization. For this reason, we assessed the generalization performance of FW-MRS on downstream tasks and found no statistically significant differences. Additionally, FW-MRS was applied to a real-world dataset from the social sciences. The source code is available at https://github.com/kramerlab/FeatureWeightDebiasing.
A Fair Experimental Comparison of Neural Network Architectures for Latent Representations of Multi-Omics for Drug Response Prediction
Aug 31, 2022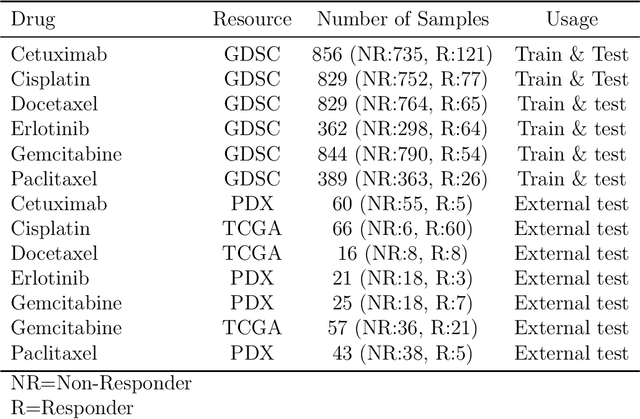

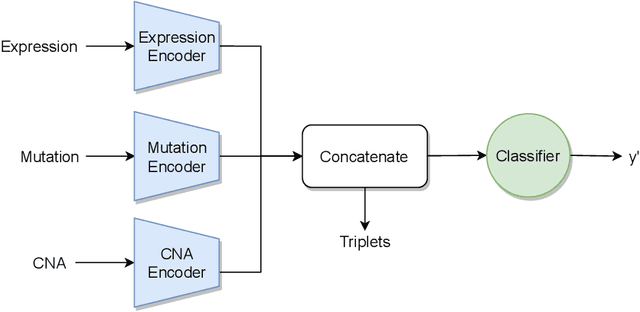
Recent years have seen a surge of novel neural network architectures for the integration of multi-omics data for prediction. Most of the architectures include either encoders alone or encoders and decoders, i.e., autoencoders of various sorts, to transform multi-omics data into latent representations. One important parameter is the depth of integration: the point at which the latent representations are computed or merged, which can be either early, intermediate, or late. The literature on integration methods is growing steadily, however, close to nothing is known about the relative performance of these methods under fair experimental conditions and under consideration of different use cases. We developed a comparison framework that trains and optimizes multi-omics integration methods under equal conditions. We incorporated early integration and four recently published deep learning methods: MOLI, Super.FELT, OmiEmbed, and MOMA. Further, we devised a novel method, Omics Stacking, that combines the advantages of intermediate and late integration. Experiments were conducted on a public drug response data set with multiple omics data (somatic point mutations, somatic copy number profiles and gene expression profiles) that was obtained from cell lines, patient-derived xenografts, and patient samples. Our experiments confirmed that early integration has the lowest predictive performance. Overall, architectures that integrate triplet loss achieved the best results. Statistical differences can, overall, rarely be observed, however, in terms of the average ranks of methods, Super.FELT is consistently performing best in a cross-validation setting and Omics Stacking best in an external test set setting. The source code of all experiments is available under \url{https://github.com/kramerlab/Multi-Omics_analysis}