 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised AUC Optimization based on Positive-Unlabeled Learning
Oct 16, 2017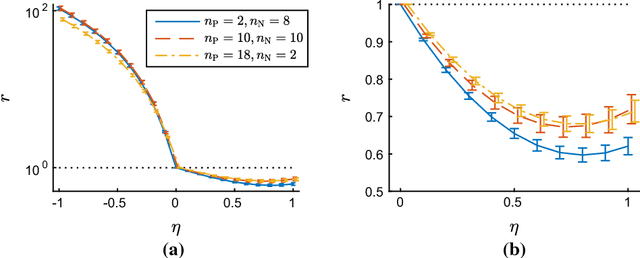
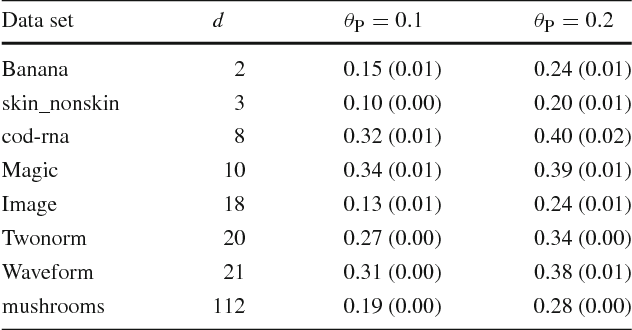
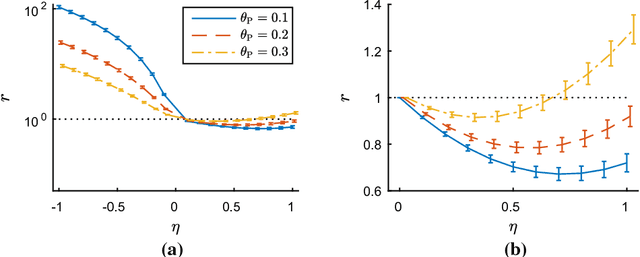
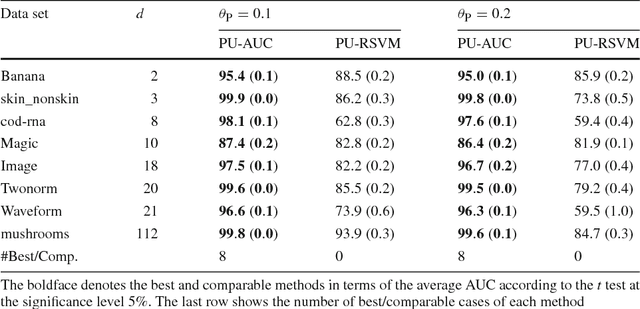
Maximizing the area under the receiver operating characteristic curve (AUC) is a standard approach to imbalanced classification. So far, various supervised AUC optimization methods have been developed and they are also extended to semi-supervised scenarios to cope with small sample problems. However, existing semi-supervised AUC optimization methods rely on strong distributional assumptions, which are rarely satisfied in real-world problems. In this paper, we propose a novel semi-supervised AUC optimization method that does not require such restrictive assumptions. We first develop an AUC optimization method based only on positive and unlabeled data (PU-AUC) and then extend it to semi-supervised learning by combining it with a supervised AUC optimization method. We theoretically prove that, without the restrictive distributional assumptions, unlabeled data contribute to improving the generalization performance in PU and semi-supervised AUC optimization methods. Finally, we demonstrate the practical usefulness of the proposed methods through experiments.
Semi-Supervised Classification Based on Classification from Positive and Unlabeled Data
Jun 16, 2017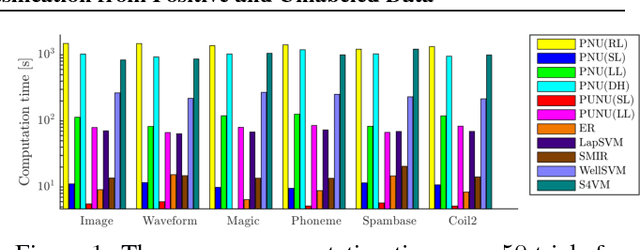
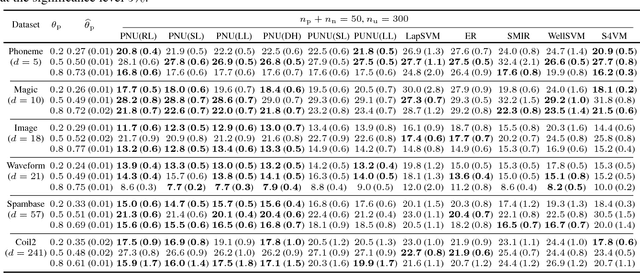
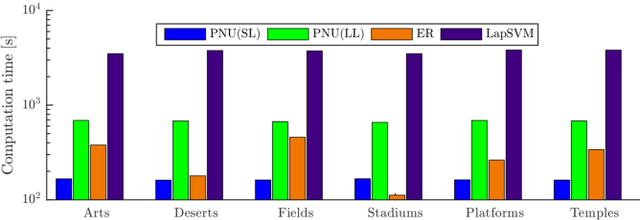
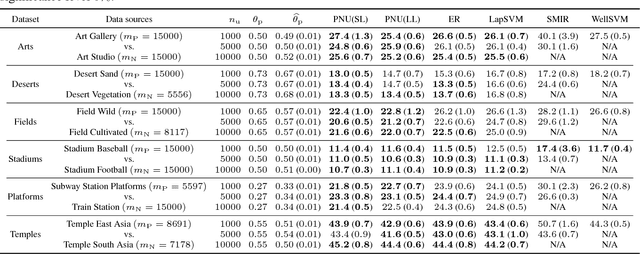
Most of the semi-supervised classification methods developed so far use unlabeled data for regularization purposes under particular distributional assumptions such as the cluster assumption. In contrast, recently developed methods of classification from positive and unlabeled data (PU classification) use unlabeled data for risk evaluation, i.e., label information is directly extracted from unlabeled data. In this paper, we extend PU classification to also incorporate negative data and propose a novel semi-supervised classification approach. We establish generalization error bounds for our novel methods and show that the bounds decrease with respect to the number of unlabeled data without the distributional assumptions that are required in existing semi-supervised classification methods. Through experiments, we demonstrate the usefulness of the proposed methods.
Theoretical Comparisons of Positive-Unlabeled Learning against Positive-Negative Learning
Oct 28, 2016
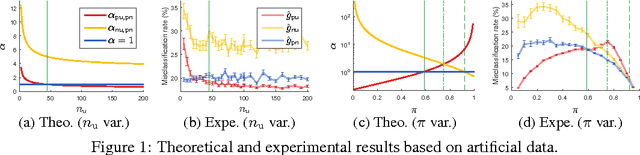

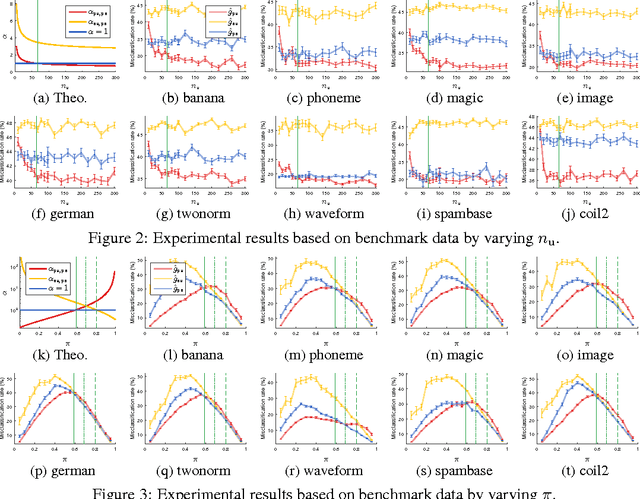
In PU learning, a binary classifier is trained from positive (P) and unlabeled (U) data without negative (N) data. Although N data is missing, it sometimes outperforms PN learning (i.e., ordinary supervised learning). Hitherto, neither theoretical nor experimental analysis has been given to explain this phenomenon. In this paper, we theoretically compare PU (and NU) learning against PN learning based on the upper bounds on estimation errors. We find simple conditions when PU and NU learning are likely to outperform PN learning, and we prove that, in terms of the upper bounds, either PU or NU learning (depending on the class-prior probability and the sizes of P and N data) given infinite U data will improve on PN learning. Our theoretical findings well agree with the experimental results on artificial and benchmark data even when the experimental setup does not match the theoretical assumptions exactly.
Multiple pattern classification by sparse subspace decomposition
Aug 04, 2009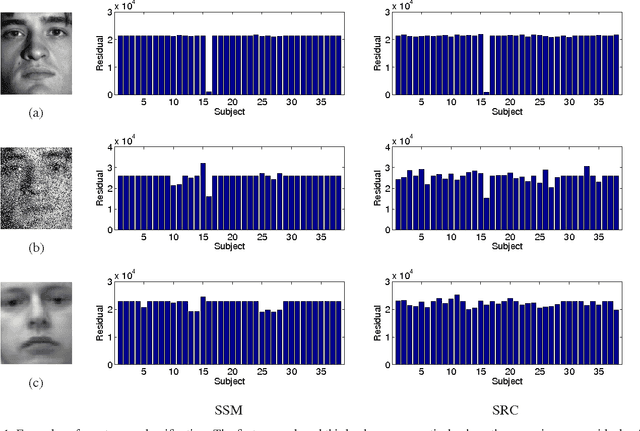
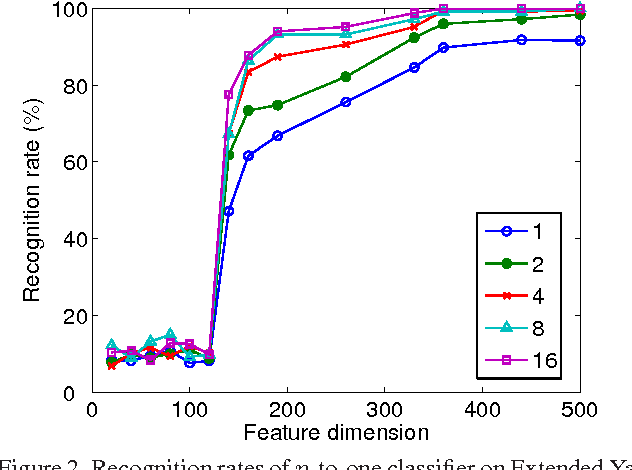
A robust classification method is developed on the basis of sparse subspace decomposition. This method tries to decompose a mixture of subspaces of unlabeled data (queries) into class subspaces as few as possible. Each query is classified into the class whose subspace significantly contributes to the decomposed subspace. Multiple queries from different classes can be simultaneously classified into their respective classes. A practical greedy algorithm of the sparse subspace decomposition is designed for the classification. The present method achieves high recognition rate and robust performance exploiting joint sparsity.