 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Inference Networks: A Class of Deep Bayesian Networks for Health Profiling
Feb 06, 2019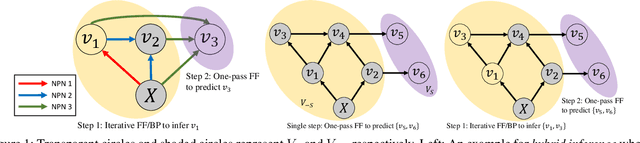
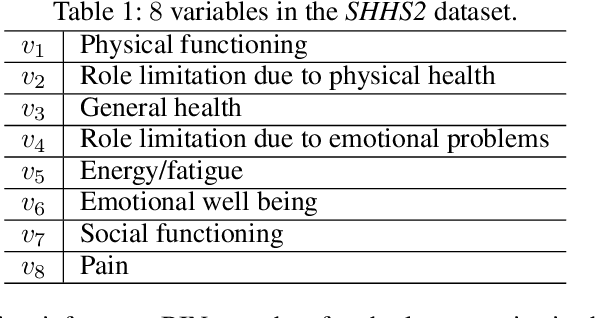
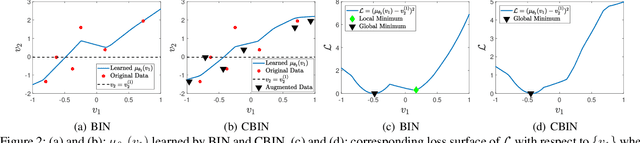
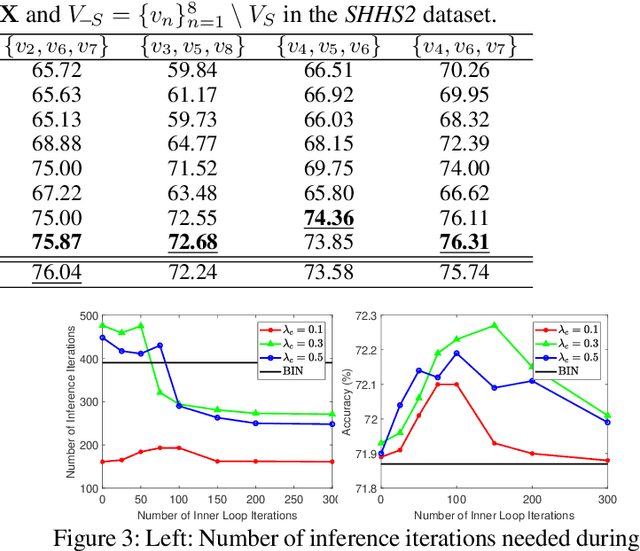
We consider the problem of inferring the values of an arbitrary set of variables (e.g., risk of diseases) given other observed variables (e.g., symptoms and diagnosed diseases) and high-dimensional signals (e.g., MRI images or EEG). This is a common problem in healthcare since variables of interest often differ for different patients. Existing methods including Bayesian networks and structured prediction either do not incorporate high-dimensional signals or fail to model conditional dependencies among variables. To address these issues, we propose bidirectional inference networks (BIN), which stich together multiple probabilistic neural networks, each modeling a conditional dependency. Predictions are then made via iteratively updating variables using backpropagation (BP) to maximize corresponding posterior probability. Furthermore, we extend BIN to composite BIN (CBIN), which involves the iterative prediction process in the training stage and improves both accuracy and computational efficiency by adaptively smoothing the optimization landscape. Experiments on synthetic and real-world datasets (a sleep study and a dermatology dataset) show that CBIN is a single model that can achieve state-of-the-art performance and obtain better accuracy in most inference tasks than multiple models each specifically trained for a different task.
Gromov-Wasserstein Alignment of Word Embedding Spaces
Aug 31, 2018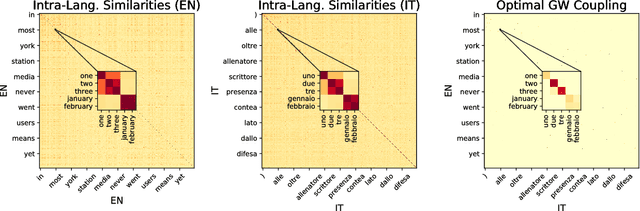
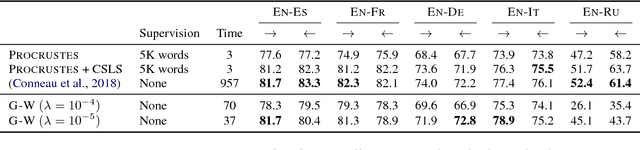
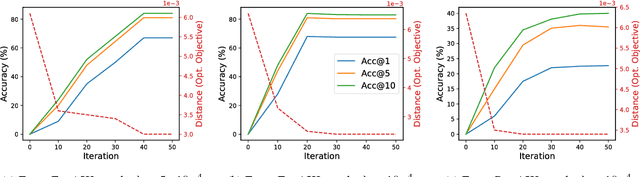
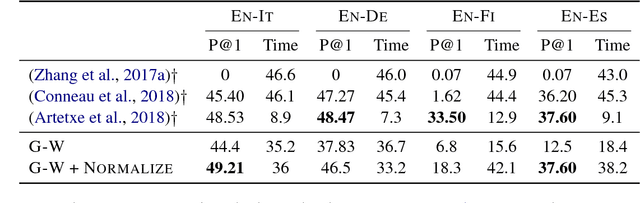
Cross-lingual or cross-domain correspondences play key roles in tasks ranging from machine translation to transfer learning. Recently, purely unsupervised methods operating on monolingual embeddings have become effective alignment tools. Current state-of-the-art methods, however, involve multiple steps, including heuristic post-hoc refinement strategies. In this paper, we cast the correspondence problem directly as an optimal transport (OT) problem, building on the idea that word embeddings arise from metric recovery algorithms. Indeed, we exploit the Gromov-Wasserstein distance that measures how similarities between pairs of words relate across languages. We show that our OT objective can be estimated efficiently, requires little or no tuning, and results in performance comparable with the state-of-the-art in various unsupervised word translation tasks.
Game-Theoretic Interpretability for Temporal Modeling
Jun 30, 2018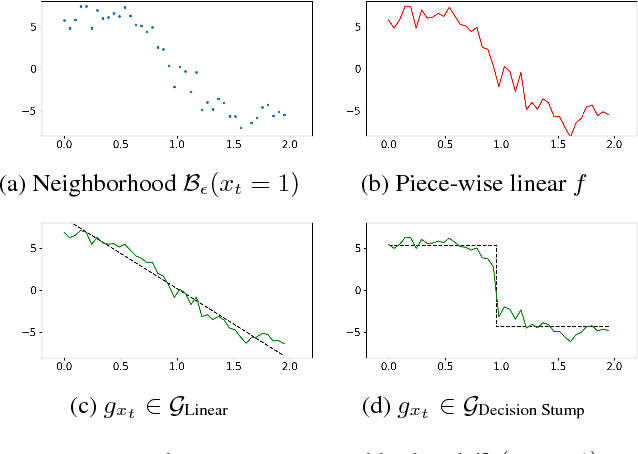
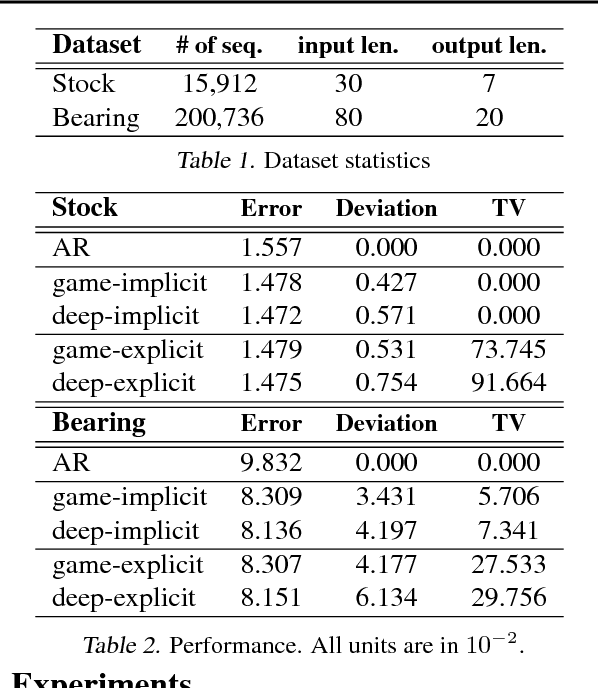
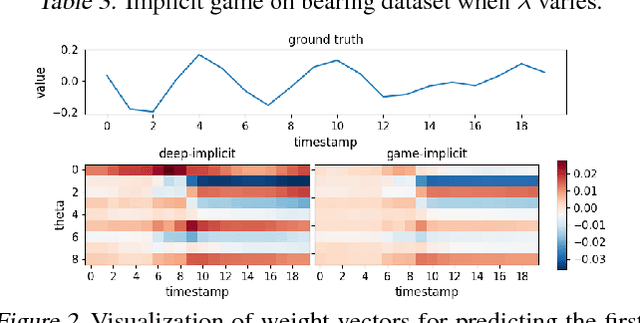
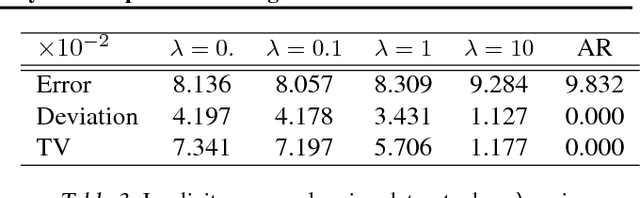
Interpretability has arisen as a key desideratum of machine learning models alongside performance. Approaches so far have been primarily concerned with fixed dimensional inputs emphasizing feature relevance or selection. In contrast, we focus on temporal modeling and the problem of tailoring the predictor, functionally, towards an interpretable family. To this end, we propose a co-operative game between the predictor and an explainer without any a priori restrictions on the functional class of the predictor. The goal of the explainer is to highlight, locally, how well the predictor conforms to the chosen interpretable family of temporal models. Our co-operative game is setup asymmetrically in terms of information sets for efficiency reasons. We develop and illustrate the framework in the context of temporal sequence models with examples.
Towards Optimal Transport with Global Invariances
Jun 25, 2018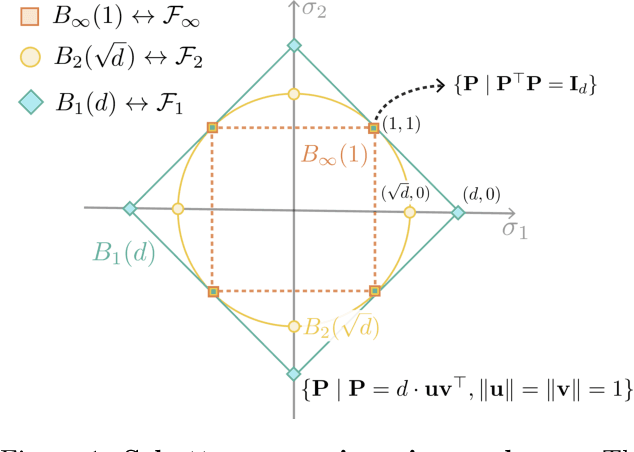
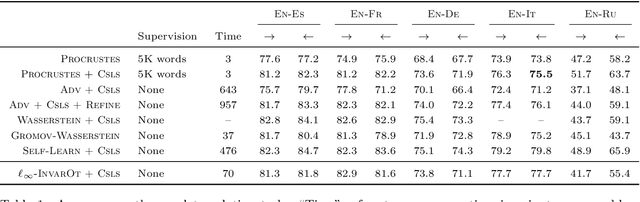
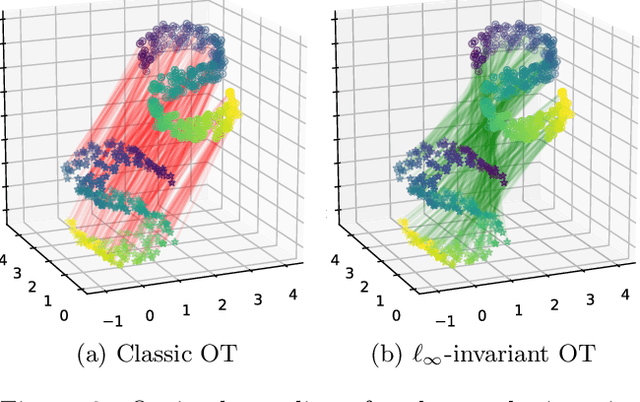
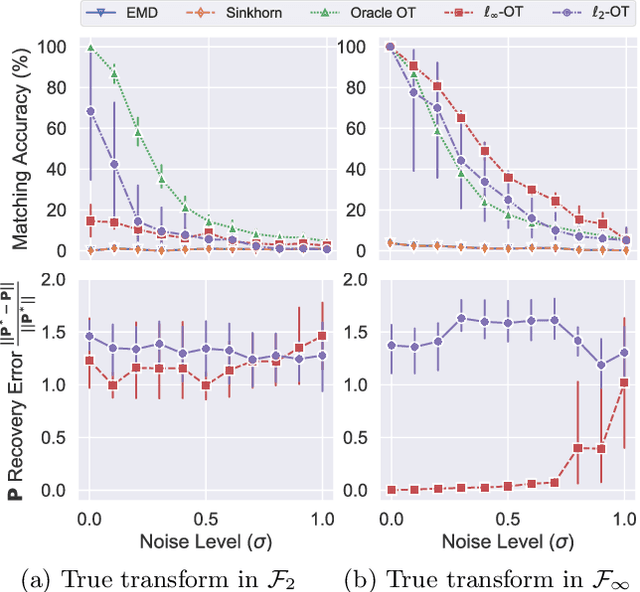
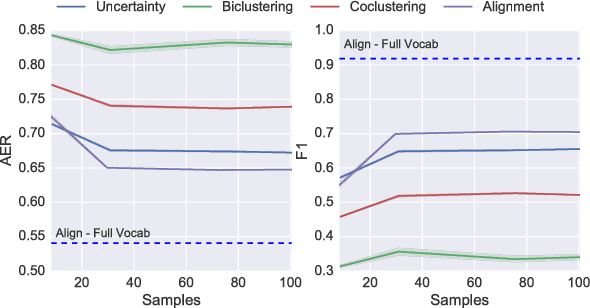
Many problems in machine learning involve calculating correspondences between sets of objects, such as point clouds or images. Discrete optimal transport (OT) provides a natural and successful approach to such tasks whenever the two sets of objects can be represented in the same space or when we can evaluate distances between the objects. Unfortunately neither requirement is likely to hold when object representations are learned from data. Indeed, automatically derived representations such as word embeddings are typically fixed only up to some global transformations, for example, reflection or rotation. As a result, pairwise distances across the two types of objects are ill-defined without specifying their relative transformation. In this work, we propose a general framework for optimal transport in the presence of latent global transformations. We discuss algorithms for the specific case of orthonormal transformations, and show promising results in unsupervised word alignment.
On the Robustness of Interpretability Methods
Jun 21, 2018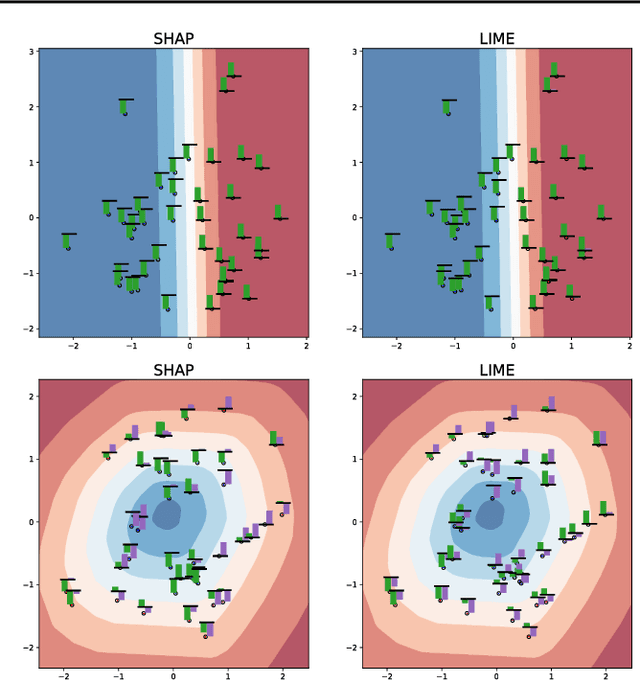
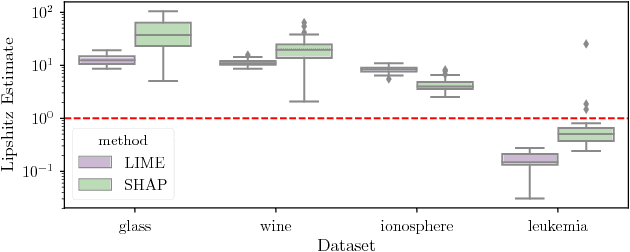
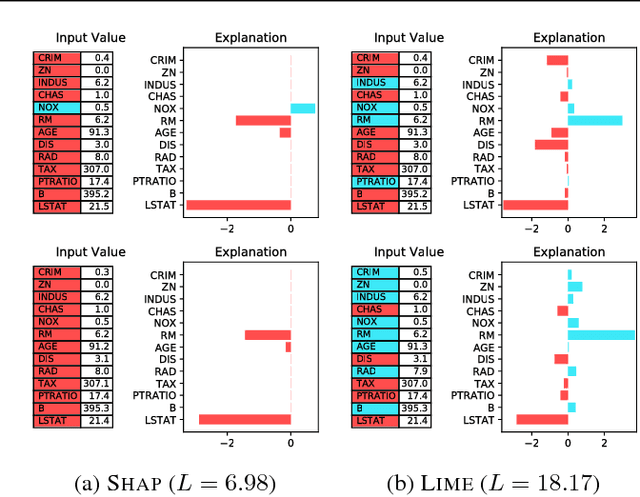
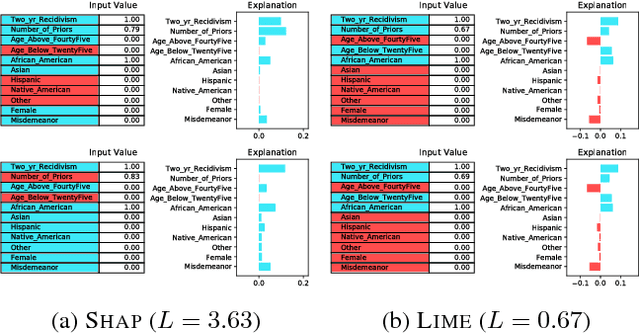
We argue that robustness of explanations---i.e., that similar inputs should give rise to similar explanations---is a key desideratum for interpretability. We introduce metrics to quantify robustness and demonstrate that current methods do not perform well according to these metrics. Finally, we propose ways that robustness can be enforced on existing interpretability approaches.
Towards Robust Interpretability with Self-Explaining Neural Networks
Jun 20, 2018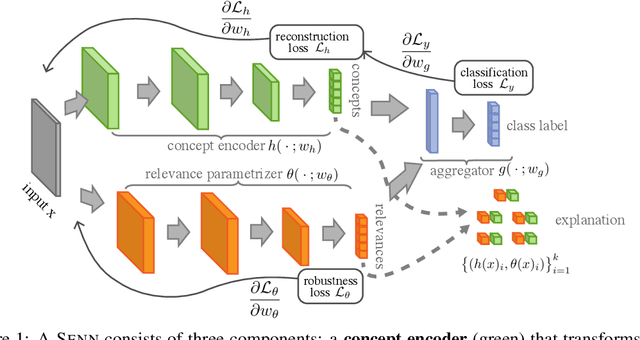
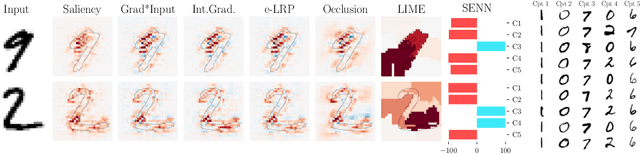
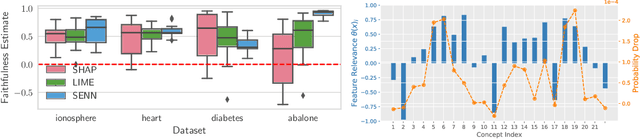
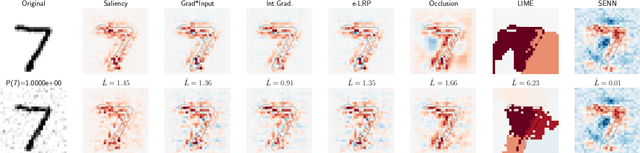
Most recent work on interpretability of complex machine learning models has focused on estimating $\textit{a posteriori}$ explanations for previously trained models around specific predictions. $\textit{Self-explaining}$ models where interpretability plays a key role already during learning have received much less attention. We propose three desiderata for explanations in general -- explicitness, faithfulness, and stability -- and show that existing methods do not satisfy them. In response, we design self-explaining models in stages, progressively generalizing linear classifiers to complex yet architecturally explicit models. Faithfulness and stability are enforced via regularization specifically tailored to such models. Experimental results across various benchmark datasets show that our framework offers a promising direction for reconciling model complexity and interpretability.
Structured Optimal Transport
Dec 17, 2017
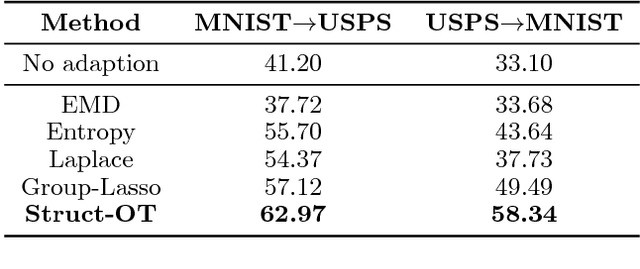

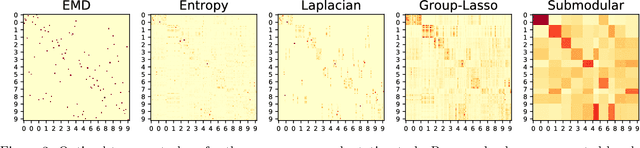
Optimal Transport has recently gained interest in machine learning for applications ranging from domain adaptation, sentence similarities to deep learning. Yet, its ability to capture frequently occurring structure beyond the "ground metric" is limited. In this work, we develop a nonlinear generalization of (discrete) optimal transport that is able to reflect much additional structure. We demonstrate how to leverage the geometry of this new model for fast algorithms, and explore connections and properties. Illustrative experiments highlight the benefit of the induced structured couplings for tasks in domain adaptation and natural language processing.
A causal framework for explaining the predictions of black-box sequence-to-sequence models
Nov 14, 2017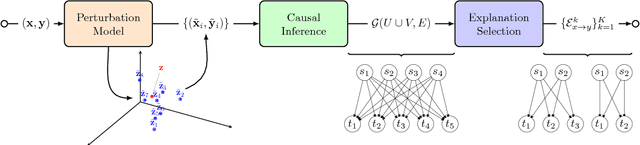
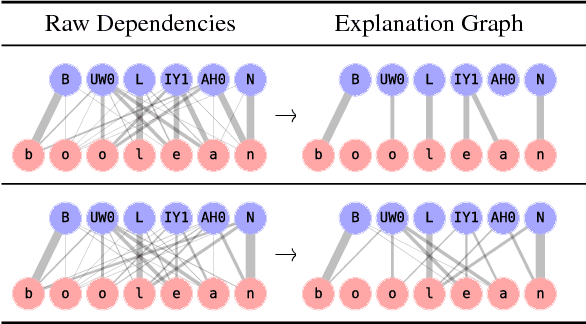

We interpret the predictions of any black-box structured input-structured output model around a specific input-output pair. Our method returns an "explanation" consisting of groups of input-output tokens that are causally related. These dependencies are inferred by querying the black-box model with perturbed inputs, generating a graph over tokens from the responses, and solving a partitioning problem to select the most relevant components. We focus the general approach on sequence-to-sequence problems, adopting a variational autoencoder to yield meaningful input perturbations. We test our method across several NLP sequence generation tasks.
From random walks to distances on unweighted graphs
Nov 02, 2015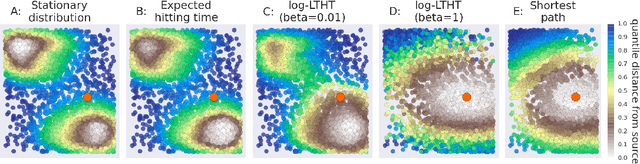
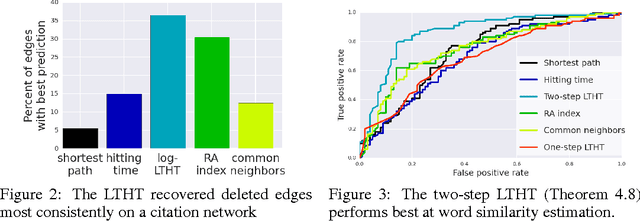
Large unweighted directed graphs are commonly used to capture relations between entities. A fundamental problem in the analysis of such networks is to properly define the similarity or dissimilarity between any two vertices. Despite the significance of this problem, statistical characterization of the proposed metrics has been limited. We introduce and develop a class of techniques for analyzing random walks on graphs using stochastic calculus. Using these techniques we generalize results on the degeneracy of hitting times and analyze a metric based on the Laplace transformed hitting time (LTHT). The metric serves as a natural, provably well-behaved alternative to the expected hitting time. We establish a general correspondence between hitting times of the Brownian motion and analogous hitting times on the graph. We show that the LTHT is consistent with respect to the underlying metric of a geometric graph, preserves clustering tendency, and remains robust against random addition of non-geometric edges. Tests on simulated and real-world data show that the LTHT matches theoretical predictions and outperforms alternatives.
Word, graph and manifold embedding from Markov processes
Sep 18, 2015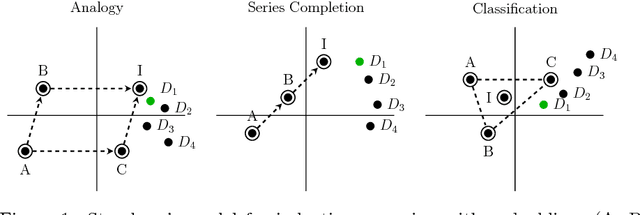
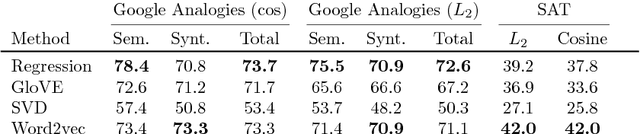

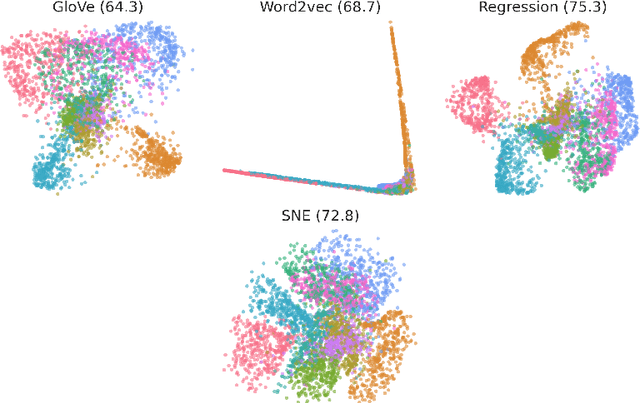
Continuous vector representations of words and objects appear to carry surprisingly rich semantic content. In this paper, we advance both the conceptual and theoretical understanding of word embeddings in three ways. First, we ground embeddings in semantic spaces studied in cognitive-psychometric literature and introduce new evaluation tasks. Second, in contrast to prior work, we take metric recovery as the key object of study, unify existing algorithms as consistent metric recovery methods based on co-occurrence counts from simple Markov random walks, and propose a new recovery algorithm. Third, we generalize metric recovery to graphs and manifolds, relating co-occurence counts on random walks in graphs and random processes on manifolds to the underlying metric to be recovered, thereby reconciling manifold estimation and embedding algorithms. We compare embedding algorithms across a range of tasks, from nonlinear dimensionality reduction to three semantic language tasks, including analogies, sequence completion, and classification.