 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Aided Annealed Langevin Dynamics for Rapid Optimization of Programmable Channels
Oct 21, 2025Emerging technologies such as Reconfigurable Intelligent Surfaces (RIS) make it possible to optimize some parameters of wireless channels. Conventional approaches require relating the channel and its programmable parameters via a simple model that supports rapid optimization, e.g., re-tuning the parameters each time the users move. However, in practice such models are often crude approximations of the channel, and a more faithful description can be obtained via complex simulators, or only by measurements. In this work, we introduce a novel approach for rapid optimization of programmable channels based on AI-aided Annealed Langevin Dynamics (ALD), which bypasses the need for explicit channel modeling. By framing the ALD algorithm using the MAP estimate, we design a deep unfolded ALD algorithm that leverages a Deep Neural Network (DNN) to estimate score gradients for optimizing channel parameters. We introduce a training method that overcomes the need for channel modeling using zero-order gradients, combined with active learning to enhance generalization, enabling optimization in complex and dynamically changing environments. We evaluate the proposed method in RIS-aided scenarios subject to rich-scattering effects. Our results demonstrate that our AI-aided ALD method enables rapid and reliable channel parameter tuning with limited latency.
Unveiling and Mitigating Adversarial Vulnerabilities in Iterative Optimizers
Apr 26, 2025



Machine learning (ML) models are often sensitive to carefully crafted yet seemingly unnoticeable perturbations. Such adversarial examples are considered to be a property of ML models, often associated with their black-box operation and sensitivity to features learned from data. This work examines the adversarial sensitivity of non-learned decision rules, and particularly of iterative optimizers. Our analysis is inspired by the recent developments in deep unfolding, which cast such optimizers as ML models. We show that non-learned iterative optimizers share the sensitivity to adversarial examples of ML models, and that attacking iterative optimizers effectively alters the optimization objective surface in a manner that modifies the minima sought. We then leverage the ability to cast iteration-limited optimizers as ML models to enhance robustness via adversarial training. For a class of proximal gradient optimizers, we rigorously prove how their learning affects adversarial sensitivity. We numerically back our findings, showing the vulnerability of various optimizers, as well as the robustness induced by unfolding and adversarial training.
Joint Privacy Enhancement and Quantization in Federated Learning
Aug 23, 2022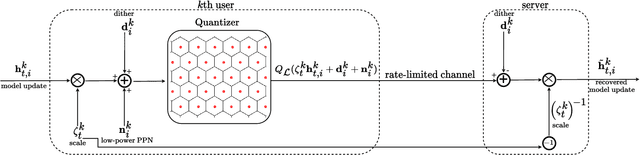
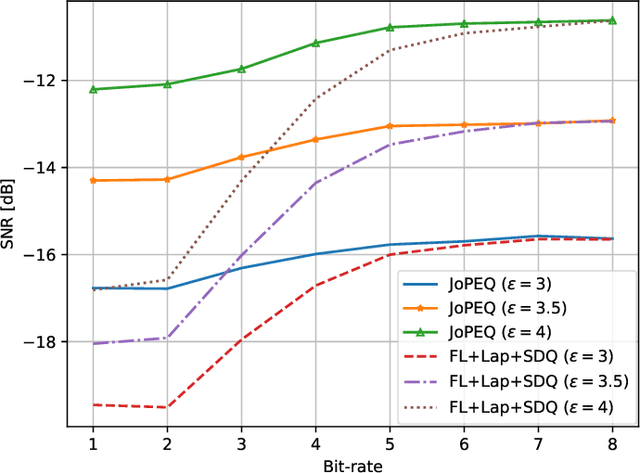
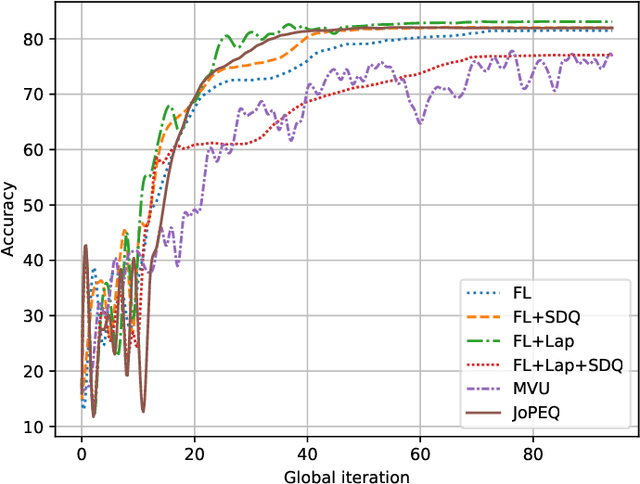
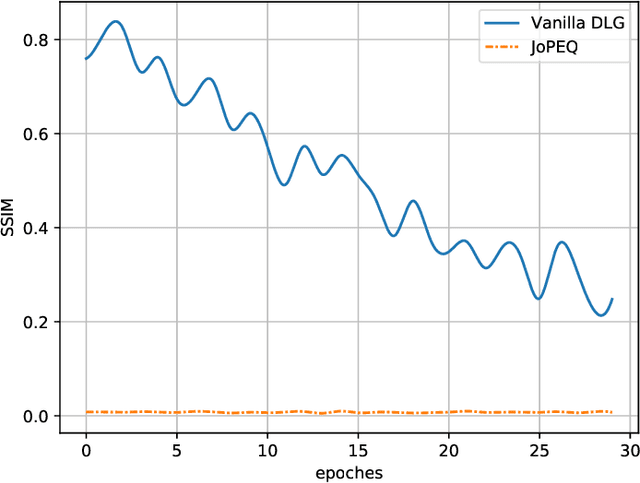
Federated learning (FL) is an emerging paradigm for training machine learning models using possibly private data available at edge devices. The distributed operation of FL gives rise to challenges that are not encountered in centralized machine learning, including the need to preserve the privacy of the local datasets, and the communication load due to the repeated exchange of updated models. These challenges are often tackled individually via techniques that induce some distortion on the updated models, e.g., local differential privacy (LDP) mechanisms and lossy compression. In this work we propose a method coined joint privacy enhancement and quantization (JoPEQ), which jointly implements lossy compression and privacy enhancement in FL settings. In particular, JoPEQ utilizes vector quantization based on random lattice, a universal compression technique whose byproduct distortion is statistically equivalent to additive noise. This distortion is leveraged to enhance privacy by augmenting the model updates with dedicated multivariate privacy preserving noise. We show that JoPEQ simultaneously quantizes data according to a required bit-rate while holding a desired privacy level, without notably affecting the utility of the learned model. This is shown via analytical LDP guarantees, distortion and convergence bounds derivation, and numerical studies. Finally, we empirically assert that JoPEQ demolishes common attacks known to exploit privacy leakage.