 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Multi-modal LLMs with ART: Art-based Reinforcement Training
Jun 10, 2026There are two main Parameter-Efficient Fine-Tuning (PEFT) techniques for Large Language Models (LLMs). While Low-Rank Adaptation (LoRA) introduces additional weights between the LLM layers, Soft Prompting introduces additional fine-tuning-specific raw tokens to an LLM input. However, both require modification to the computational graphs of precompiled, preoptimized LLMs. As a result, neither is fully supported in high-throughput engines like vLLM. We propose fine-tuning with ART (Art-based Reinforcement Training). The method injects information into a frozen Multimodal Large Language Model (MLLM) by optimizing only its raw visual input, thus enabling the soft-token approach on pre-compiled computational graphs. It relies on backpropagation of gradients back into a plain pixel array and thus supports any fine-tuning objective. Moreover, the optimized visual input can be stylized as task-relevant computational artworks. The approach's effectiveness is confirmed for different sizes of a popular open Qwen architecture and for several textual benchmarks. Specifically, ART reaches accuracy competitive with LoRA across mathematics and structured-tool-use benchmarks.
Better Modelling Out-of-Distribution Regression on Distributed Acoustic Sensor Data Using Anchored Hidden State Mixup
Feb 23, 2022

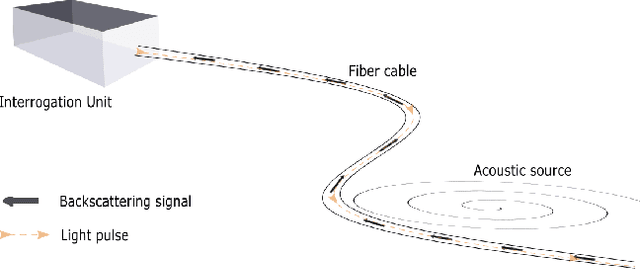

Generalizing the application of machine learning models to situations where the statistical distribution of training and test data are different has been a complex problem. Our contributions in this paper are threefold: (1) we introduce an anchored-based Out of Distribution (OOD) Regression Mixup algorithm, leveraging manifold hidden state mixup and observation similarities to form a novel regularization penalty, (2) we provide a first of its kind, high resolution Distributed Acoustic Sensor (DAS) dataset that is suitable for testing OOD regression modelling, allowing other researchers to benchmark progress in this area, and (3) we demonstrate with an extensive evaluation the generalization performance of the proposed method against existing approaches, then show that our method achieves state-of-the-art performance. Lastly, we also demonstrate a wider applicability of the proposed method by exhibiting improved generalization performances on other types of regression datasets, including Udacity and Rotation-MNIST datasets.