 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCSG-Net -- Unsupervised Discovering of Constructive Solid Geometry Tree
Jul 03, 2020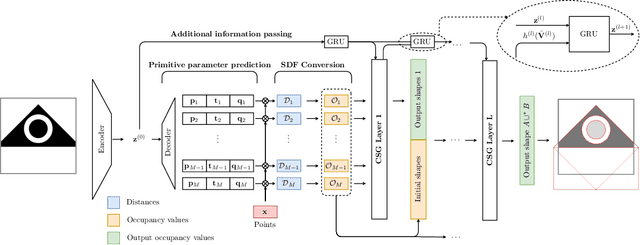
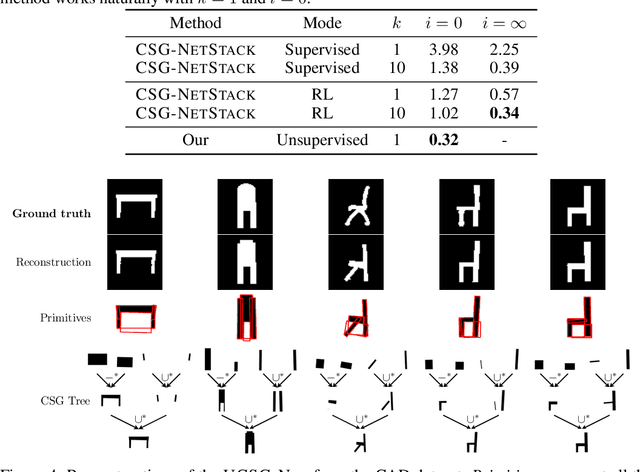

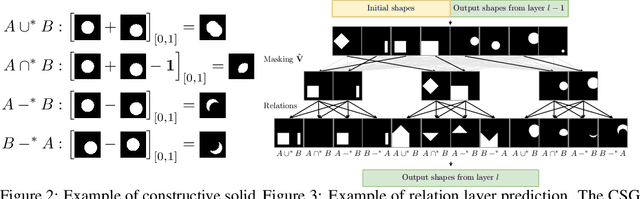
Signed distance field (SDF) is a prominent implicit representation of 3D meshes. Methods that are based on such representation achieved state-of-the-art 3D shape reconstruction quality. However, these methods struggle to reconstruct non-convex shapes. One remedy is to incorporate a constructive solid geometry framework (CSG) that represents a shape as a decomposition into primitives. It allows to embody a 3D shape of high complexity and non-convexity with a simple tree representation of Boolean operations. Nevertheless, existing approaches are supervised and require the entire CSG parse tree that is given upfront during the training process. On the contrary, we propose a model that extracts a CSG parse tree without any supervision - UCSG-Net. Our model predicts parameters of primitives and binarizes their SDF representation through differentiable indicator function. It is achieved jointly with discovering the structure of a Boolean operators tree. The model selects dynamically which operator combination over primitives leads to the reconstruction of high fidelity. We evaluate our method on 2D and 3D autoencoding tasks. We show that the predicted parse tree representation is interpretable and can be used in CAD software.
Political Advertising Dataset: the use case of the Polish 2020 Presidential Elections
Jun 17, 2020
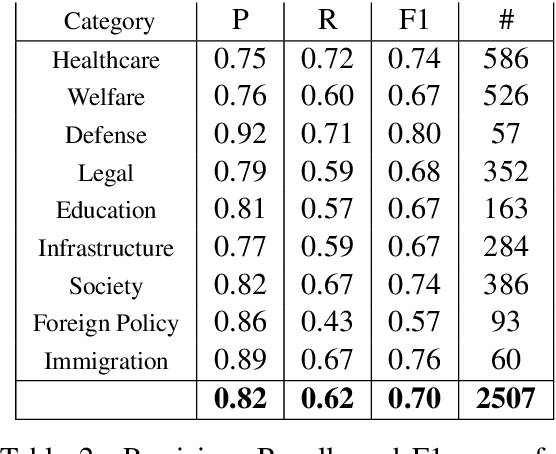
Political campaigns are full of political ads posted by candidates on social media. Political advertisements constitute a basic form of campaigning, subjected to various social requirements. We present the first publicly open dataset for detecting specific text chunks and categories of political advertising in the Polish language. It contains 1,705 human-annotated tweets tagged with nine categories, which constitute campaigning under Polish electoral law. We achieved a 0.65 inter-annotator agreement (Cohen's kappa score). An additional annotator resolved the mismatches between the first two annotators improving the consistency and complexity of the annotation process. We used the newly created dataset to train a well established neural tagger (achieving a 70% percent points F1 score). We also present a possible direction of use cases for such datasets and models with an initial analysis of the Polish 2020 Presidential Elections on Twitter.
Comprehensive Analysis of Aspect Term Extraction Methods using Various Text Embeddings
Sep 11, 2019
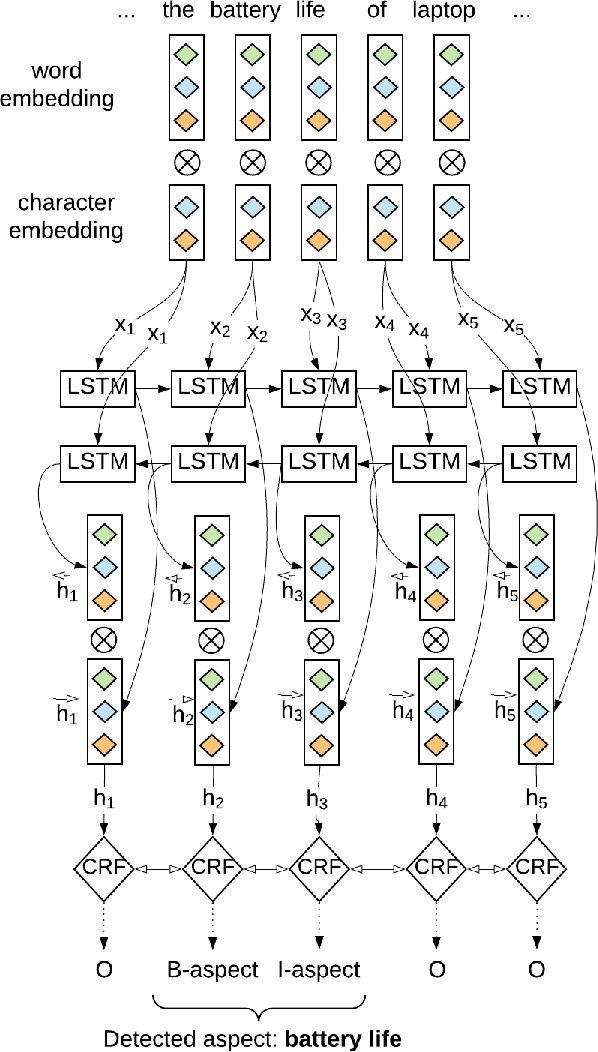
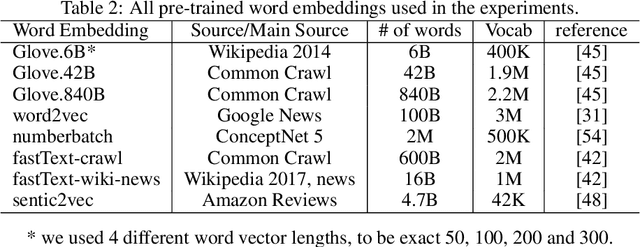
Recently, a variety of model designs and methods have blossomed in the context of the sentiment analysis domain. However, there is still a lack of wide and comprehensive studies of aspect-based sentiment analysis (ABSA). We want to fill this gap and propose a comparison with ablation analysis of aspect term extraction using various text embedding methods. We particularly focused on architectures based on long short-term memory (LSTM) with optional conditional random field (CRF) enhancement using different pre-trained word embeddings. Moreover, we analyzed the influence on the performance of extending the word vectorization step with character embedding. The experimental results on SemEval datasets revealed that not only does bi-directional long short-term memory (BiLSTM) outperform regular LSTM, but also word embedding coverage and its source highly affect aspect detection performance. An additional CRF layer consistently improves the results as well.
Extracting Aspects Hierarchies using Rhetorical Structure Theory
Sep 04, 2019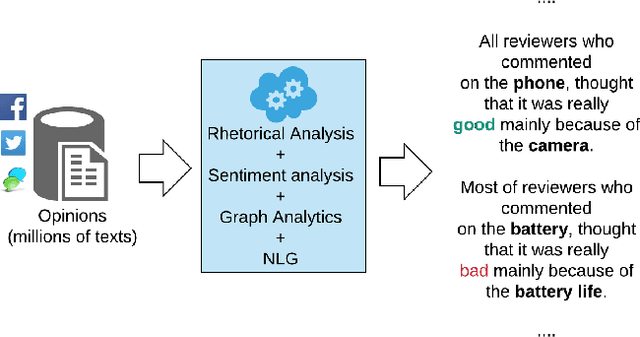

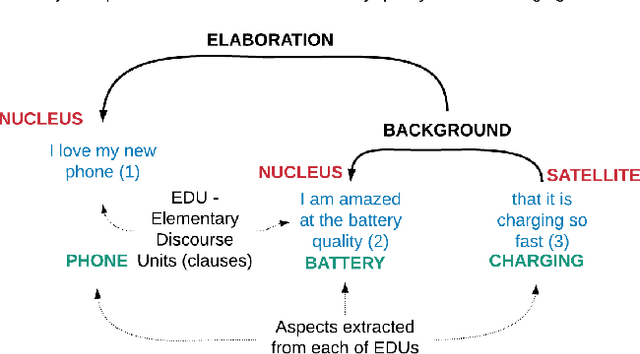
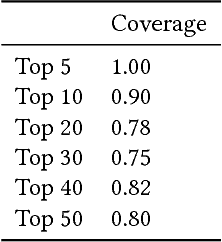
We propose a novel approach to generate aspect hierarchies that proved to be consistently correct compared with human-generated hierarchies. We present an unsupervised technique using Rhetorical Structure Theory and graph analysis. We evaluated our approach based on 100,000 reviews from Amazon and achieved an astonishing 80% coverage compared with human-generated hierarchies coded in ConceptNet. The method could be easily extended with a sentiment analysis model and used to describe sentiment on different levels of aspect granularity. Hence, besides the flat aspect structure, we can differentiate between aspects and describe if the charging aspect is related to battery or price.
* ACAI 2018 MLNLP
Aspect Detection using Word and Char Embeddings with (Bi)LSTM and CRF
Sep 03, 2019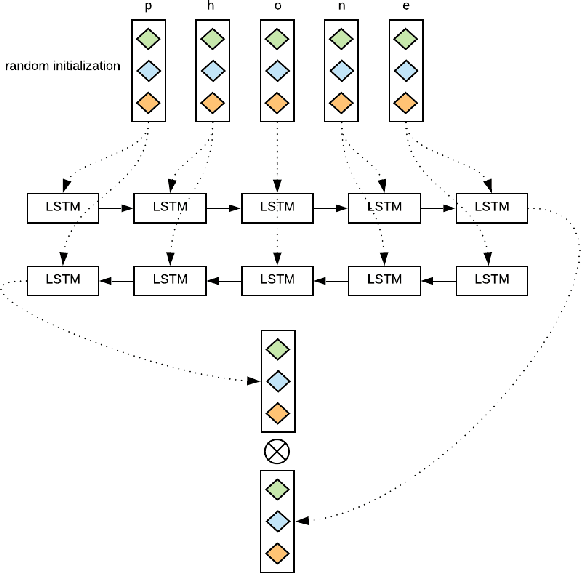
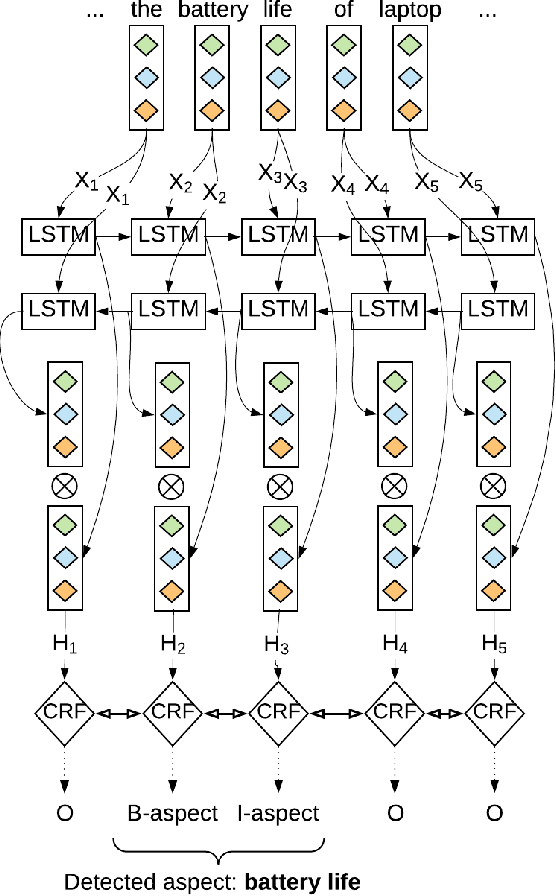
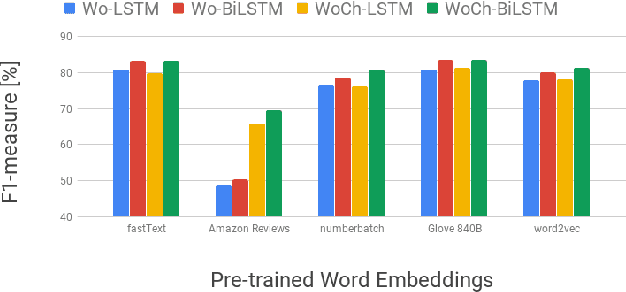
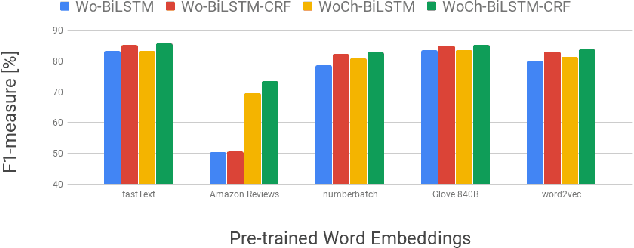
We proposed a~new accurate aspect extraction method that makes use of both word and character-based embeddings. We have conducted experiments of various models of aspect extraction using LSTM and BiLSTM including CRF enhancement on five different pre-trained word embeddings extended with character embeddings. The results revealed that BiLSTM outperforms regular LSTM, but also word embedding coverage in train and test sets profoundly impacted aspect detection performance. Moreover, the additional CRF layer consistently improves the results across different models and text embeddings. Summing up, we obtained state-of-the-art F-score results for SemEval Restaurants (85%) and Laptops (80%).
* IEEE AIKE
Incremental embedding for temporal networks
Apr 06, 2019
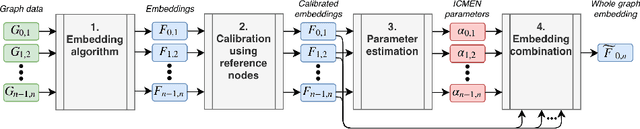
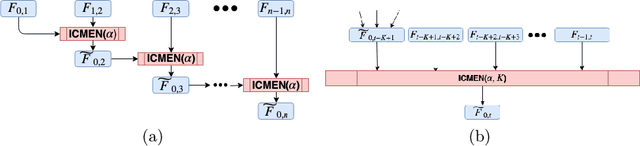
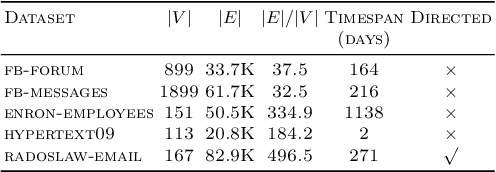
Prediction over edges and nodes in graphs requires appropriate and efficiently achieved data representation. Recent research on representation learning for dynamic networks resulted in a significant progress. However, the more precise and accurate methods, the greater computational and memory complexity. Here, we introduce ICMEN - the first-in-class incremental meta-embedding method that produces vector representations of nodes respecting temporal dependencies in the graph. ICMEN efficiently constructs nodes' embedding from historical representations by linearly convex combinations making the process less memory demanding than state-of-the-art embedding algorithms. The method is capable of constructing representation for inactive and new nodes without a need to re-embed. The results of link prediction on several real-world datasets shown that applying ICMEN incremental meta-method to any base embedding approach, we receive similar results and save memory and computational power. Taken together, our work proposes a new way of efficient online representation learning in dynamic complex networks.
LNEMLC: Label Network Embeddings for Multi-Label Classification
Jan 01, 2019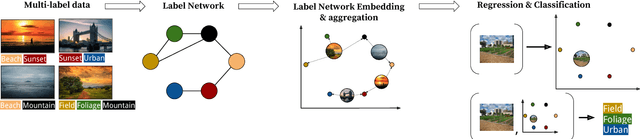
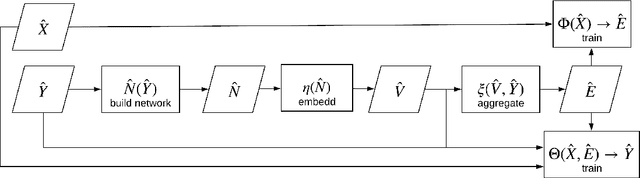
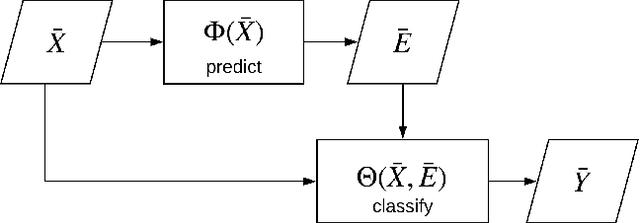
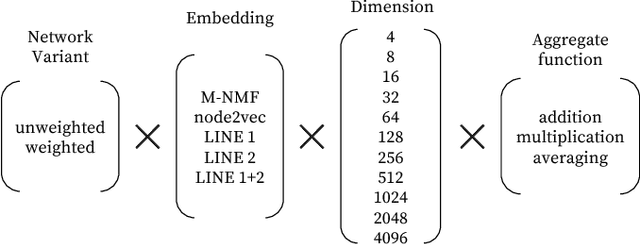
Multi-label classification aims to classify instances with discrete non-exclusive labels. Most approaches on multi-label classification focus on effective adaptation or transformation of existing binary and multi-class learning approaches but fail in modelling the joint probability of labels or do not preserve generalization abilities for unseen label combinations. To address these issues we propose a new multi-label classification scheme, LNEMLC - Label Network Embedding for Multi-Label Classification, that embeds the label network and uses it to extend input space in learning and inference of any base multi-label classifier. The approach allows capturing of labels' joint probability at low computational complexity providing results comparable to the best methods reported in the literature. We demonstrate how the method reveals statistically significant improvements over the simple kNN baseline classifier. We also provide hints for selecting the robust configuration that works satisfactorily across data domains.
Method for Aspect-Based Sentiment Annotation Using Rhetorical Analysis
Sep 13, 2017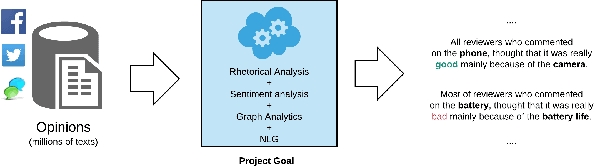
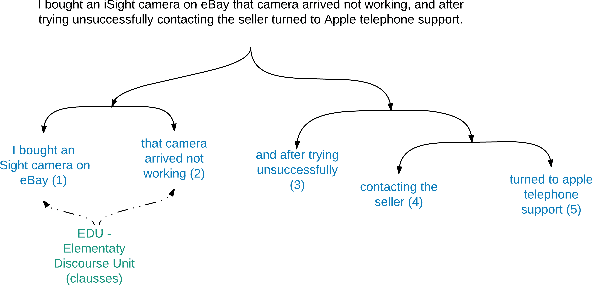
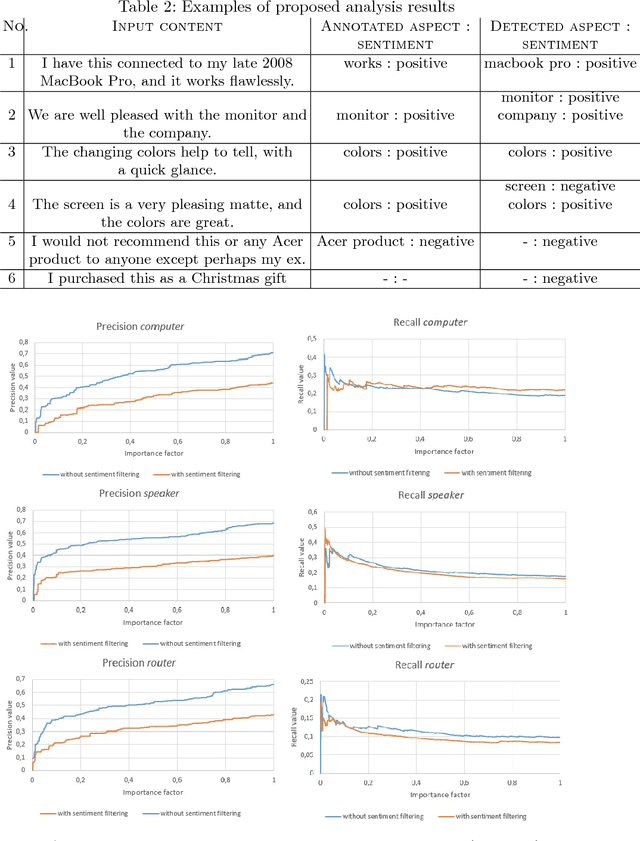
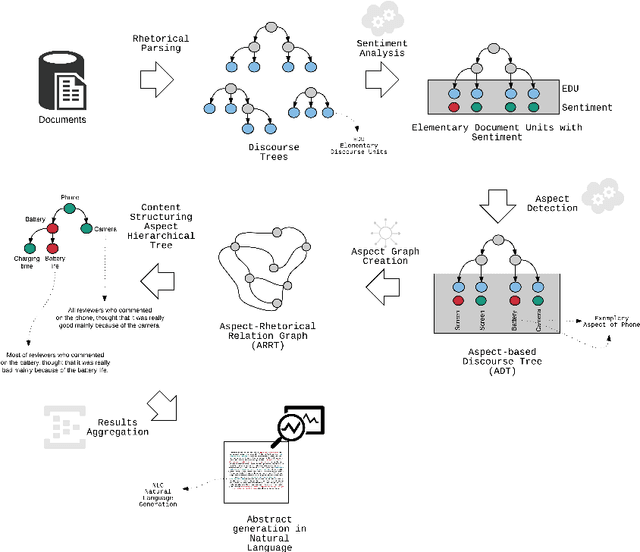
This paper fills a gap in aspect-based sentiment analysis and aims to present a new method for preparing and analysing texts concerning opinion and generating user-friendly descriptive reports in natural language. We present a comprehensive set of techniques derived from Rhetorical Structure Theory and sentiment analysis to extract aspects from textual opinions and then build an abstractive summary of a set of opinions. Moreover, we propose aspect-aspect graphs to evaluate the importance of aspects and to filter out unimportant ones from the summary. Additionally, the paper presents a prototype solution of data flow with interesting and valuable results. The proposed method's results proved the high accuracy of aspect detection when applied to the gold standard dataset.
A Network Perspective on Stratification of Multi-Label Data
Apr 27, 2017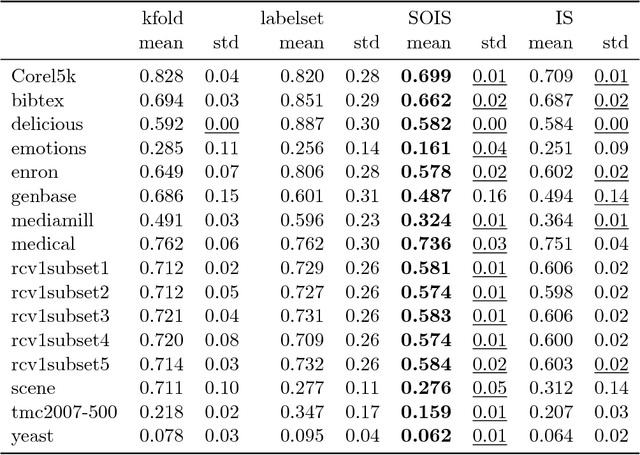
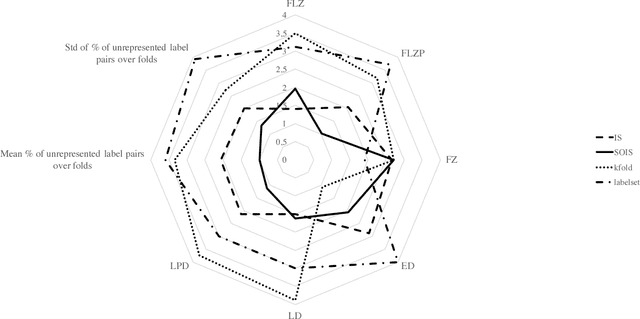
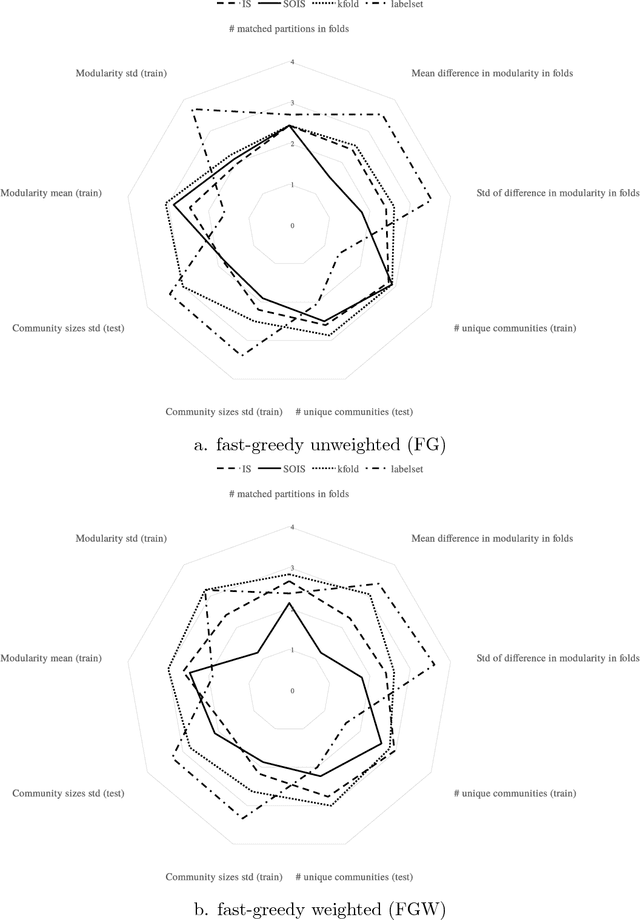
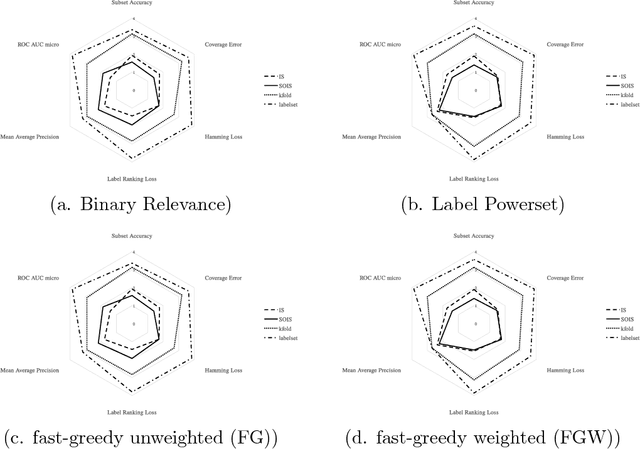
In the recent years, we have witnessed the development of multi-label classification methods which utilize the structure of the label space in a divide and conquer approach to improve classification performance and allow large data sets to be classified efficiently. Yet most of the available data sets have been provided in train/test splits that did not account for maintaining a distribution of higher-order relationships between labels among splits or folds. We present a new approach to stratifying multi-label data for classification purposes based on the iterative stratification approach proposed by Sechidis et. al. in an ECML PKDD 2011 paper. Our method extends the iterative approach to take into account second-order relationships between labels. Obtained results are evaluated using statistical properties of obtained strata as presented by Sechidis. We also propose new statistical measures relevant to second-order quality: label pairs distribution, the percentage of label pairs without positive evidence in folds and label pair - fold pairs that have no positive evidence for the label pair. We verify the impact of new methods on classification performance of Binary Relevance, Label Powerset and a fast greedy community detection based label space partitioning classifier. Random Forests serve as base classifiers. We check the variation of the number of communities obtained per fold, and the stability of their modularity score. Second-Order Iterative Stratification is compared to standard k-fold, label set, and iterative stratification. The proposed approach lowers the variance of classification quality, improves label pair oriented measures and example distribution while maintaining a competitive quality in label-oriented measures. We also witness an increase in stability of network characteristics.
Is a Data-Driven Approach still Better than Random Choice with Naive Bayes classifiers?
Feb 13, 2017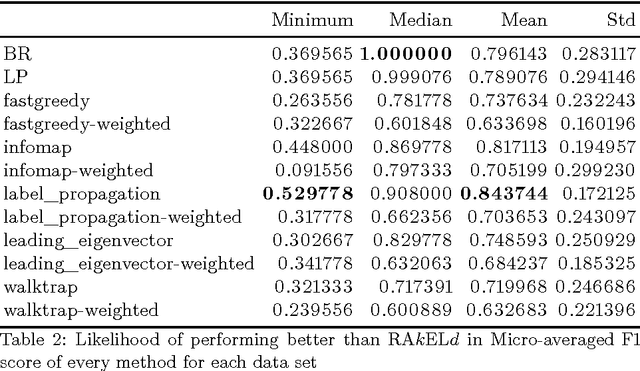
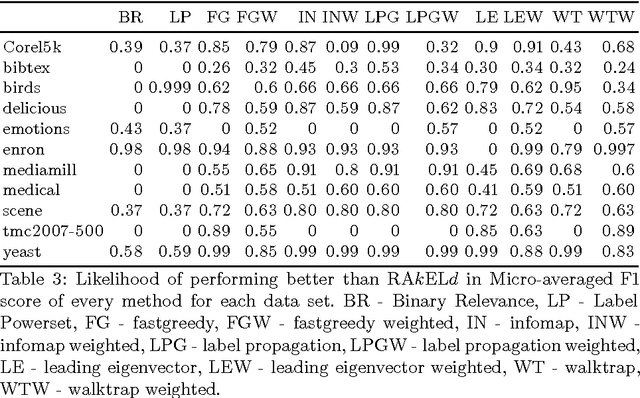
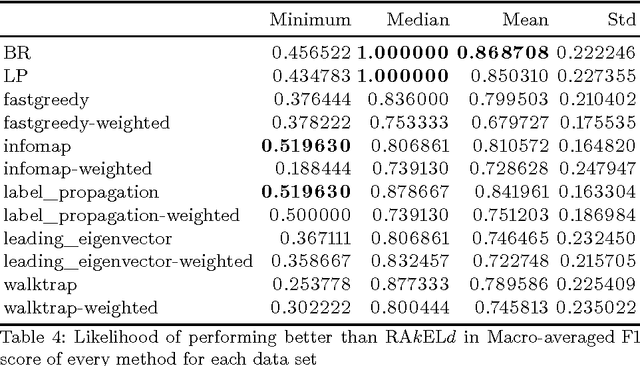
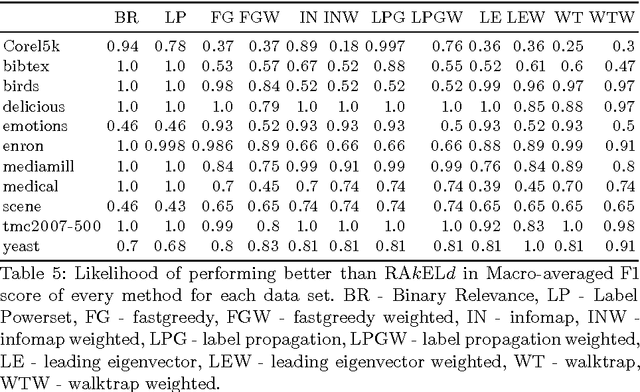
We study the performance of data-driven, a priori and random approaches to label space partitioning for multi-label classification with a Gaussian Naive Bayes classifier. Experiments were performed on 12 benchmark data sets and evaluated on 5 established measures of classification quality: micro and macro averaged F1 score, Subset Accuracy and Hamming loss. Data-driven methods are significantly better than an average run of the random baseline. In case of F1 scores and Subset Accuracy - data driven approaches were more likely to perform better than random approaches than otherwise in the worst case. There always exists a method that performs better than a priori methods in the worst case. The advantage of data-driven methods against a priori methods with a weak classifier is lesser than when tree classifiers are used.