 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Agnostic Neural Architecture for Class Incremental Continual Learning in Document Processing Platform
Jul 11, 2023Production deployments in complex systems require ML architectures to be highly efficient and usable against multiple tasks. Particularly demanding are classification problems in which data arrives in a streaming fashion and each class is presented separately. Recent methods with stochastic gradient learning have been shown to struggle in such setups or have limitations like memory buffers, and being restricted to specific domains that disable its usage in real-world scenarios. For this reason, we present a fully differentiable architecture based on the Mixture of Experts model, that enables the training of high-performance classifiers when examples from each class are presented separately. We conducted exhaustive experiments that proved its applicability in various domains and ability to learn online in production environments. The proposed technique achieves SOTA results without a memory buffer and clearly outperforms the reference methods.
Massively Multilingual Corpus of Sentiment Datasets and Multi-faceted Sentiment Classification Benchmark
Jun 13, 2023Despite impressive advancements in multilingual corpora collection and model training, developing large-scale deployments of multilingual models still presents a significant challenge. This is particularly true for language tasks that are culture-dependent. One such example is the area of multilingual sentiment analysis, where affective markers can be subtle and deeply ensconced in culture. This work presents the most extensive open massively multilingual corpus of datasets for training sentiment models. The corpus consists of 79 manually selected datasets from over 350 datasets reported in the scientific literature based on strict quality criteria. The corpus covers 27 languages representing 6 language families. Datasets can be queried using several linguistic and functional features. In addition, we present a multi-faceted sentiment classification benchmark summarizing hundreds of experiments conducted on different base models, training objectives, dataset collections, and fine-tuning strategies.
Graph-level representations using ensemble-based readout functions
Mar 03, 2023Graph machine learning models have been successfully deployed in a variety of application areas. One of the most prominent types of models - Graph Neural Networks (GNNs) - provides an elegant way of extracting expressive node-level representation vectors, which can be used to solve node-related problems, such as classifying users in a social network. However, many tasks require representations at the level of the whole graph, e.g., molecular applications. In order to convert node-level representations into a graph-level vector, a so-called readout function must be applied. In this work, we study existing readout methods, including simple non-trainable ones, as well as complex, parametrized models. We introduce a concept of ensemble-based readout functions that combine either representations or predictions. Our experiments show that such ensembles allow for better performance than simple single readouts or similar performance as the complex, parametrized ones, but at a fraction of the model complexity.
RAFEN -- Regularized Alignment Framework for Embeddings of Nodes
Mar 03, 2023



Learning representations of nodes has been a crucial area of the graph machine learning research area. A well-defined node embedding model should reflect both node features and the graph structure in the final embedding. In the case of dynamic graphs, this problem becomes even more complex as both features and structure may change over time. The embeddings of particular nodes should remain comparable during the evolution of the graph, what can be achieved by applying an alignment procedure. This step was often applied in existing works after the node embedding was already computed. In this paper, we introduce a framework -- RAFEN -- that allows to enrich any existing node embedding method using the aforementioned alignment term and learning aligned node embedding during training time. We propose several variants of our framework and demonstrate its performance on six real-world datasets. RAFEN achieves on-par or better performance than existing approaches without requiring additional processing steps.
Neural Architecture for Online Ensemble Continual Learning
Nov 27, 2022Continual learning with an increasing number of classes is a challenging task. The difficulty rises when each example is presented exactly once, which requires the model to learn online. Recent methods with classic parameter optimization procedures have been shown to struggle in such setups or have limitations like non-differentiable components or memory buffers. For this reason, we present the fully differentiable ensemble method that allows us to efficiently train an ensemble of neural networks in the end-to-end regime. The proposed technique achieves SOTA results without a memory buffer and clearly outperforms the reference methods. The conducted experiments have also shown a significant increase in the performance for small ensembles, which demonstrates the capability of obtaining relatively high classification accuracy with a reduced number of classifiers.
This is the way: designing and compiling LEPISZCZE, a comprehensive NLP benchmark for Polish
Nov 23, 2022The availability of compute and data to train larger and larger language models increases the demand for robust methods of benchmarking the true progress of LM training. Recent years witnessed significant progress in standardized benchmarking for English. Benchmarks such as GLUE, SuperGLUE, or KILT have become de facto standard tools to compare large language models. Following the trend to replicate GLUE for other languages, the KLEJ benchmark has been released for Polish. In this paper, we evaluate the progress in benchmarking for low-resourced languages. We note that only a handful of languages have such comprehensive benchmarks. We also note the gap in the number of tasks being evaluated by benchmarks for resource-rich English/Chinese and the rest of the world. In this paper, we introduce LEPISZCZE (the Polish word for glew, the Middle English predecessor of glue), a new, comprehensive benchmark for Polish NLP with a large variety of tasks and high-quality operationalization of the benchmark. We design LEPISZCZE with flexibility in mind. Including new models, datasets, and tasks is as simple as possible while still offering data versioning and model tracking. In the first run of the benchmark, we test 13 experiments (task and dataset pairs) based on the five most recent LMs for Polish. We use five datasets from the Polish benchmark and add eight novel datasets. As the paper's main contribution, apart from LEPISZCZE, we provide insights and experiences learned while creating the benchmark for Polish as the blueprint to design similar benchmarks for other low-resourced languages.
* 10 pages, 8 pages appendix
Assessment of Massively Multilingual Sentiment Classifiers
Apr 11, 2022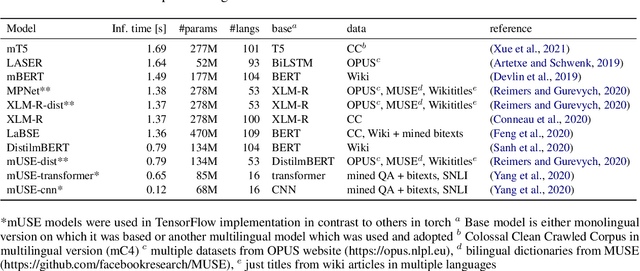
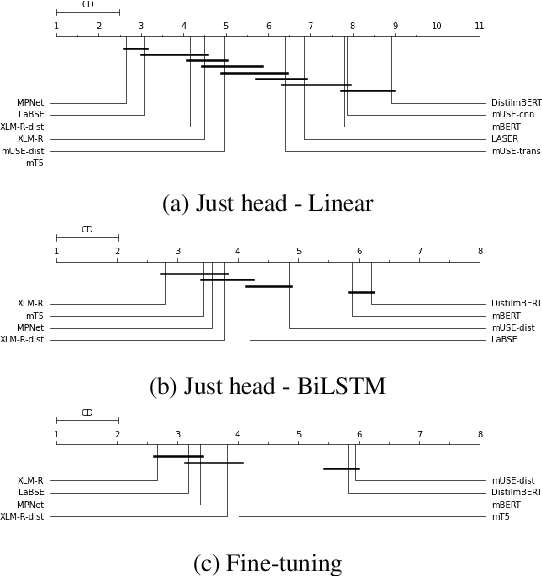
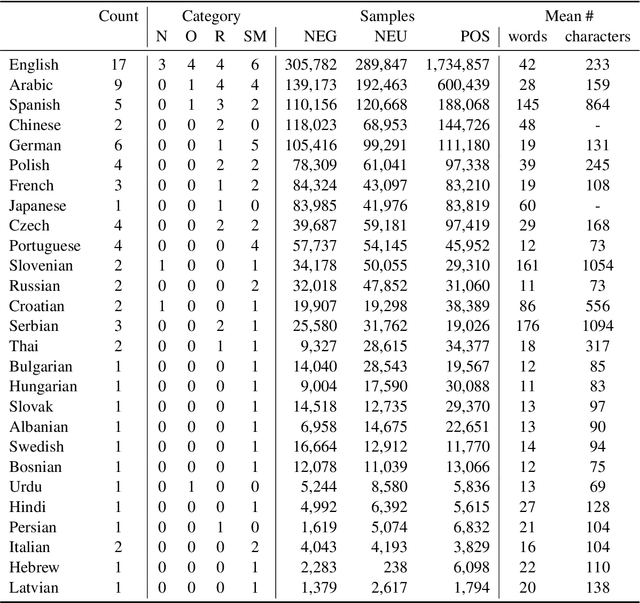
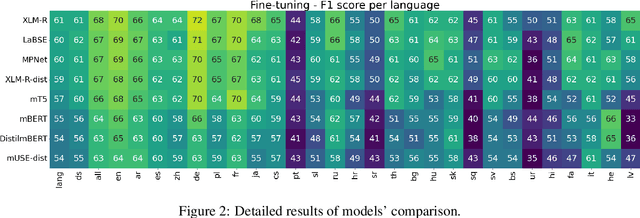
Models are increasing in size and complexity in the hunt for SOTA. But what if those 2\% increase in performance does not make a difference in a production use case? Maybe benefits from a smaller, faster model outweigh those slight performance gains. Also, equally good performance across languages in multilingual tasks is more important than SOTA results on a single one. We present the biggest, unified, multilingual collection of sentiment analysis datasets. We use these to assess 11 models and 80 high-quality sentiment datasets (out of 342 raw datasets collected) in 27 languages and included results on the internally annotated datasets. We deeply evaluate multiple setups, including fine-tuning transformer-based models for measuring performance. We compare results in numerous dimensions addressing the imbalance in both languages coverage and dataset sizes. Finally, we present some best practices for working with such a massive collection of datasets and models from a multilingual perspective.
Spatial Data Mining of Public Transport Incidents reported in Social Media
Oct 11, 2021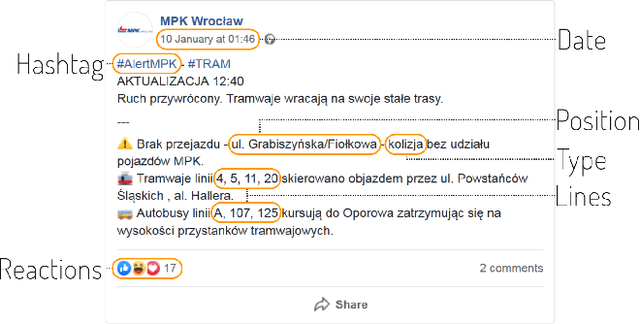
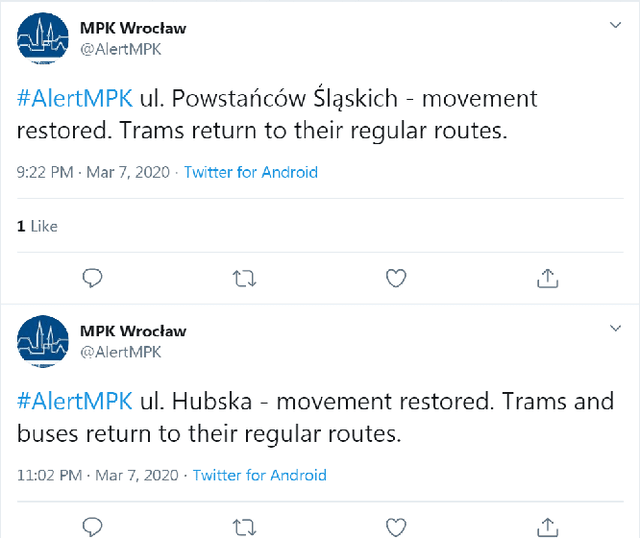
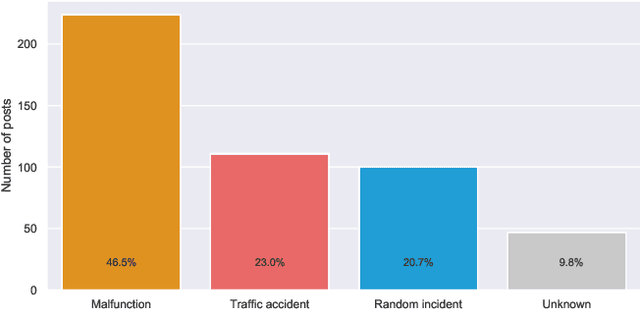
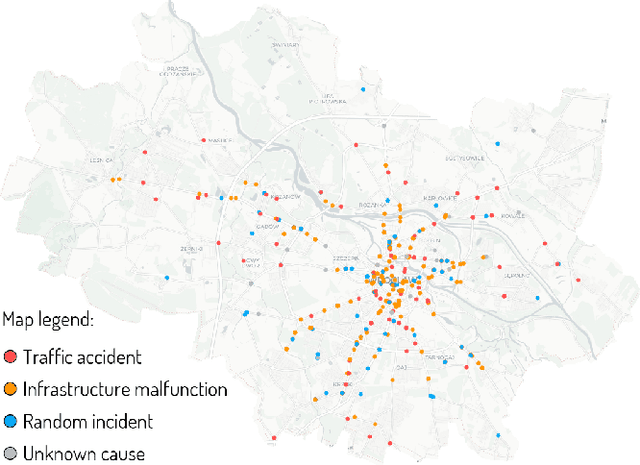
Public transport agencies use social media as an essential tool for communicating mobility incidents to passengers. However, while the short term, day-to-day information about transport phenomena is usually posted in social media with low latency, its availability is short term as the content is rarely made an aggregated form. Social media communication of transport phenomena usually lacks GIS annotations as most social media platforms do not allow attaching non-POI GPS coordinates to posts. As a result, the analysis of transport phenomena information is minimal. We collected three years of social media posts of a polish public transport company with user comments. Through exploration, we infer a six-class transport information typology. We successfully build an information type classifier for social media posts, detect stop names in posts, and relate them to GPS coordinates, obtaining a spatial understanding of long-term aggregated phenomena. We show that our approach enables citizen science and use it to analyze the impact of three years of infrastructure incidents on passenger mobility, and the sentiment and reaction scale towards each of the events. All these results are achieved for Polish, an under-resourced language when it comes to spatial language understanding, especially in social media contexts. To improve the situation, we released two of our annotated data sets: social media posts with incident type labels and matched stop names and social media comments with the annotated sentiment. We also opensource the experimental codebase.
Graph Barlow Twins: A self-supervised representation learning framework for graphs
Jun 04, 2021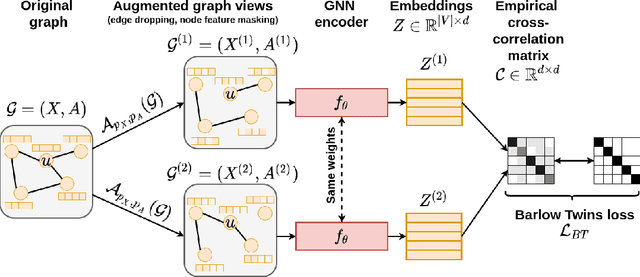
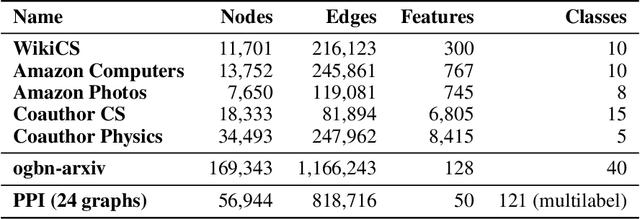
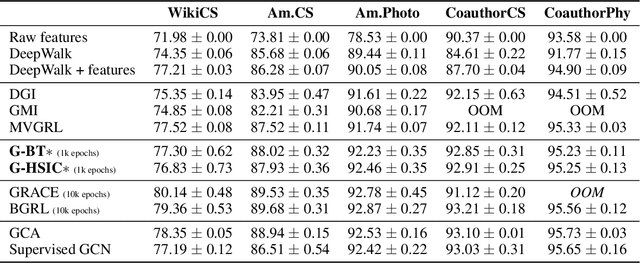
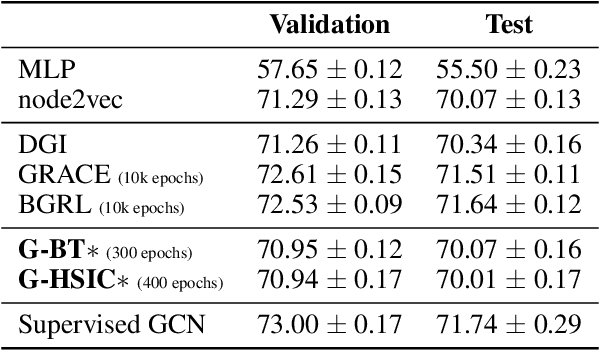
The self-supervised learning (SSL) paradigm is an essential exploration area, which tries to eliminate the need for expensive data labeling. Despite the great success of SSL methods in computer vision and natural language processing, most of them employ contrastive learning objectives that require negative samples, which are hard to define. This becomes even more challenging in the case of graphs and is a bottleneck for achieving robust representations. To overcome such limitations, we propose a framework for self-supervised graph representation learning -- Graph Barlow Twins, which utilizes a cross-correlation-based loss function instead of negative samples. Moreover, it does not rely on non-symmetric neural network architectures -- in contrast to state-of-the-art self-supervised graph representation learning method BGRL. We show that our method achieves as competitive results as BGRL, best self-supervised methods, and fully supervised ones while requiring substantially fewer hyperparameters and converging in an order of magnitude training steps earlier.
AttrE2vec: Unsupervised Attributed Edge Representation Learning
Dec 29, 2020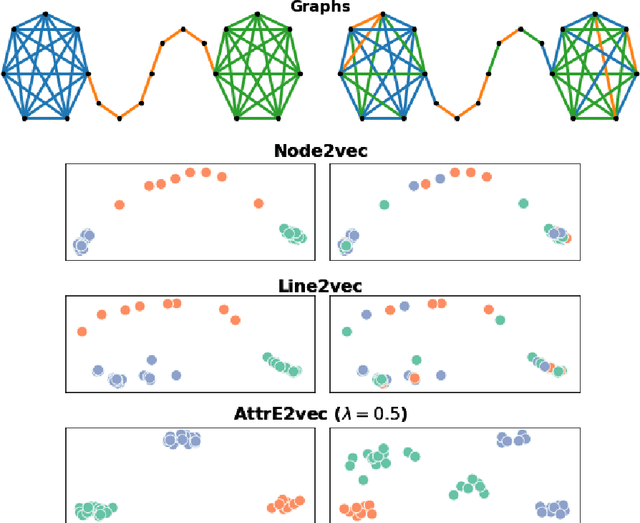
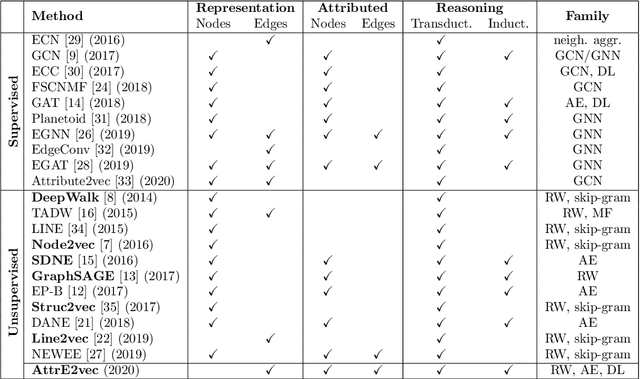
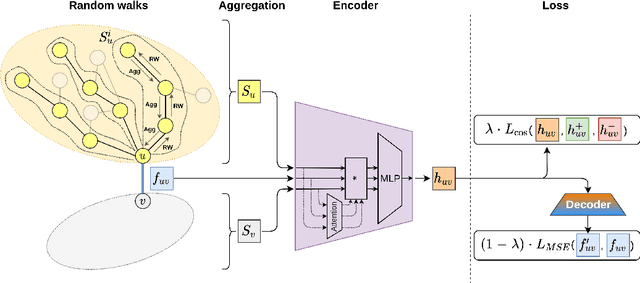
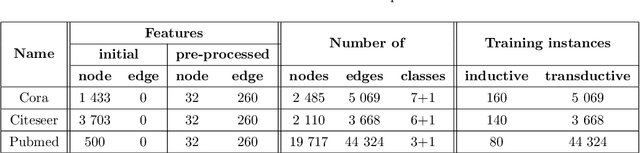
Representation learning has overcome the often arduous and manual featurization of networks through (unsupervised) feature learning as it results in embeddings that can apply to a variety of downstream learning tasks. The focus of representation learning on graphs has focused mainly on shallow (node-centric) or deep (graph-based) learning approaches. While there have been approaches that work on homogeneous and heterogeneous networks with multi-typed nodes and edges, there is a gap in learning edge representations. This paper proposes a novel unsupervised inductive method called AttrE2Vec, which learns a low-dimensional vector representation for edges in attributed networks. It systematically captures the topological proximity, attributes affinity, and feature similarity of edges. Contrary to current advances in edge embedding research, our proposal extends the body of methods providing representations for edges, capturing graph attributes in an inductive and unsupervised manner. Experimental results show that, compared to contemporary approaches, our method builds more powerful edge vector representations, reflected by higher quality measures (AUC, accuracy) in downstream tasks as edge classification and edge clustering. It is also confirmed by analyzing low-dimensional embedding projections.