 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Universal Gating Network for Mixtures of Experts
Nov 03, 2020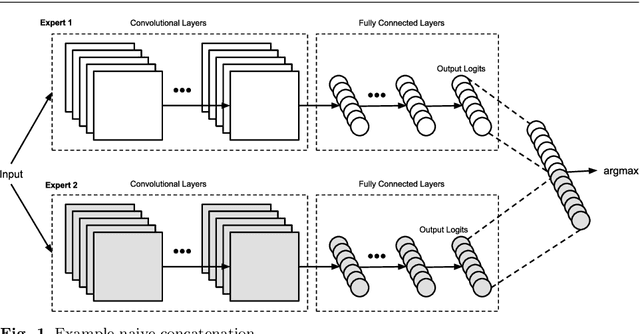


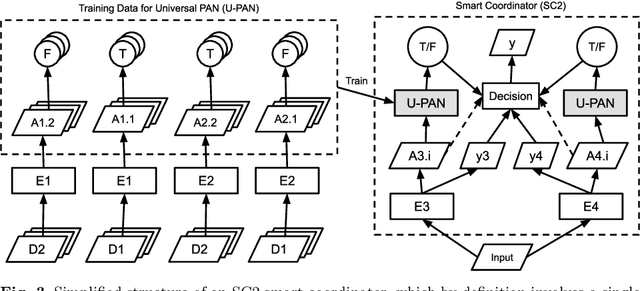
The combination and aggregation of knowledge from multiple neural networks can be commonly seen in the form of mixtures of experts. However, such combinations are usually done using networks trained on the same tasks, with little mention of the combination of heterogeneous pre-trained networks, especially in the data-free regime. This paper proposes multiple data-free methods for the combination of heterogeneous neural networks, ranging from the utilization of simple output logit statistics, to training specialized gating networks. The gating networks decide whether specific inputs belong to specific networks based on the nature of the expert activations generated. The experiments revealed that the gating networks, including the universal gating approach, constituted the most accurate approach, and therefore represent a pragmatic step towards applications with heterogeneous mixtures of experts in a data-free regime. The code for this project is hosted on github at https://github.com/cwkang1998/network-merging.
Data Augmentation by AutoEncoders for Unsupervised Anomaly Detection
Dec 21, 2019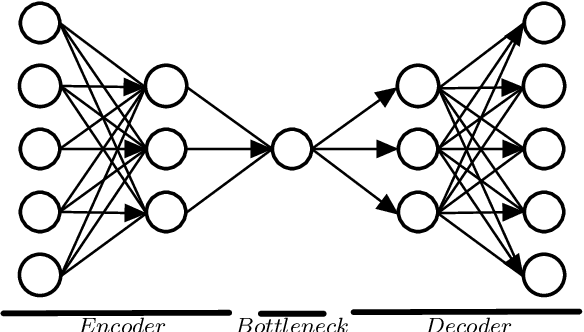
This paper proposes an autoencoder (AE) that is used for improving the performance of once-class classifiers for the purpose of detecting anomalies. Traditional one-class classifiers (OCCs) perform poorly under certain conditions such as high-dimensionality and sparsity. Also, the size of the training set plays an important role on the performance of one-class classifiers. Autoencoders have been widely used for obtaining useful latent variables from high-dimensional datasets. In the proposed approach, the AE is capable of deriving meaningful features from high-dimensional datasets while doing data augmentation at the same time. The augmented data is used for training the OCC algorithms. The experimental results show that the proposed approach enhance the performance of OCC algorithms and also outperforms other well-known approaches.
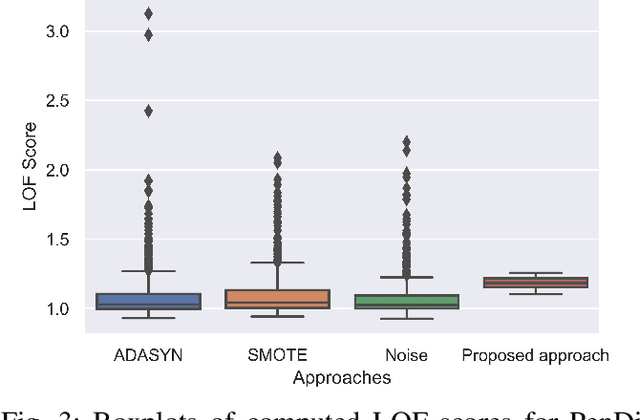
AEGR: A simple approach to gradient reversal in autoencoders for network anomaly detection
Dec 21, 2019
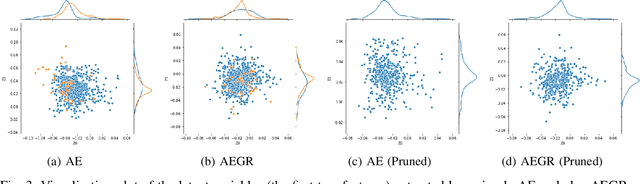

Anomaly detection is referred to as a process in which the aim is to detect data points that follow a different pattern from the majority of data points. Anomaly detection methods suffer from several well-known challenges that hinder their performance such as high dimensionality. Autoencoders are unsupervised neural networks that have been used for the purpose of reducing dimensionality and also detecting network anomalies in large datasets. The performance of autoencoders debilitates when the training set contains noise and anomalies. In this paper, a new gradient-reversal method is proposed to overcome the influence of anomalies on the training phase for the purpose of detecting network anomalies. The method is different from other approaches as it does not require an anomaly-free training set and is based on reconstruction error. Once latent variables are extracted from the network, Local Outlier Factor is used to separate normal data points from anomalies. A simple pruning approach and data augmentation is also added to further improve performance. The experimental results show that the proposed model can outperform other well-know approaches.
Detecting Point Outliers Using Prune-based Outlier Factor (PLOF)
Nov 05, 2019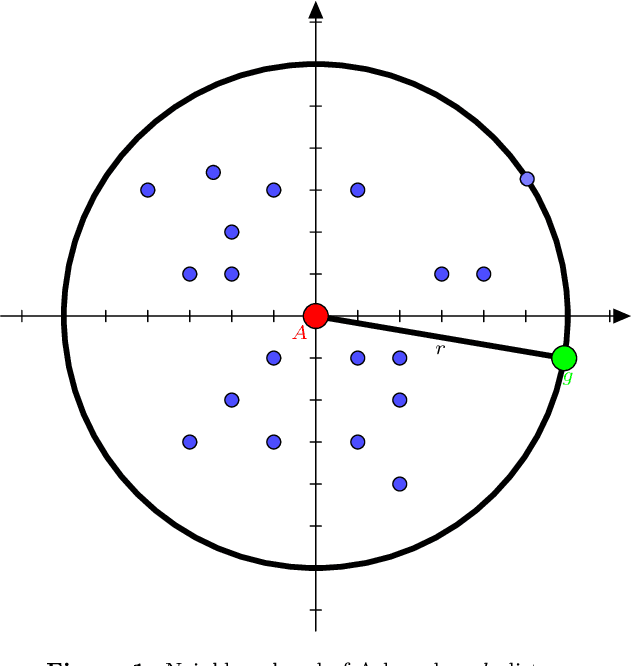
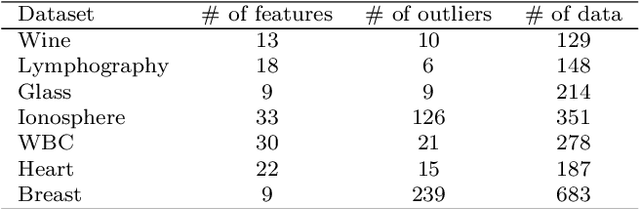
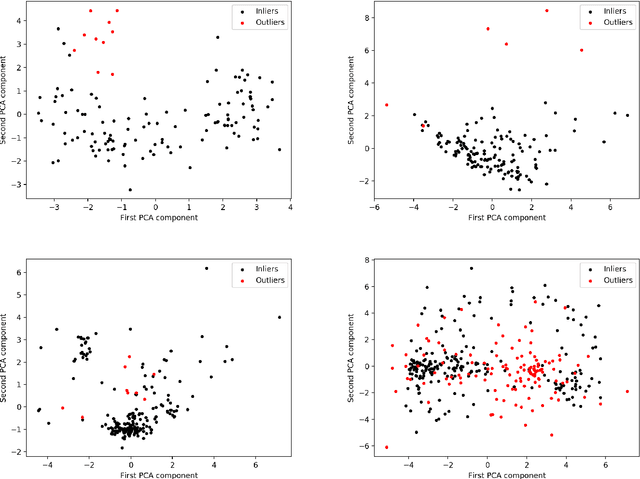
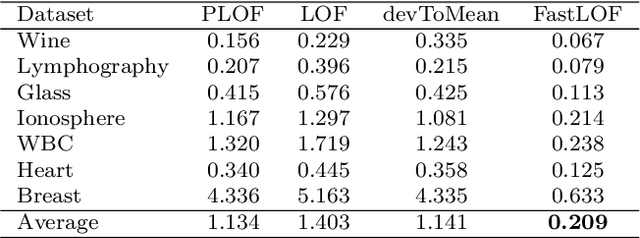
Outlier detection (also known as anomaly detection or deviation detection) is a process of detecting data points in which their patterns deviate significantly from others. It is common to have outliers in industry applications, which could be generated by different causes such as human error, fraudulent activities, or system failure. Recently, density-based methods have shown promising results, particularly among which Local Outlier Factor (LOF) is arguably dominating. However, one of the major drawbacks of LOF is that it is computationally expensive. Motivated by the mentioned problem, this research presents a novel pruning-based procedure in which the execution time of LOF is reduced while the performance is maintained. A novel Prune-based Local Outlier Factor (PLOF) approach is proposed, in which prior to employing LOF, outlierness of each data instance is measured. Next, based on a threshold, data instances that require further investigation are separated and LOF score is only computed for these points. Extensive experiments have been conducted and results are promising. Comparison experiments with the original LOF and two state-of-the-art variants of LOF have shown that PLOF produces higher accuracy and precision while reducing execution time.