 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydraViT: Adaptive Multi-Branch Transformer for Multi-Label Disease Classification from Chest X-ray Images
Oct 09, 2023Chest X-ray is an essential diagnostic tool in the identification of chest diseases given its high sensitivity to pathological abnormalities in the lungs. However, image-driven diagnosis is still challenging due to heterogeneity in size and location of pathology, as well as visual similarities and co-occurrence of separate pathology. Since disease-related regions often occupy a relatively small portion of diagnostic images, classification models based on traditional convolutional neural networks (CNNs) are adversely affected given their locality bias. While CNNs were previously augmented with attention maps or spatial masks to guide focus on potentially critical regions, learning localization guidance under heterogeneity in the spatial distribution of pathology is challenging. To improve multi-label classification performance, here we propose a novel method, HydraViT, that synergistically combines a transformer backbone with a multi-branch output module with learned weighting. The transformer backbone enhances sensitivity to long-range context in X-ray images, while using the self-attention mechanism to adaptively focus on task-critical regions. The multi-branch output module dedicates an independent branch to each disease label to attain robust learning across separate disease classes, along with an aggregated branch across labels to maintain sensitivity to co-occurrence relationships among pathology. Experiments demonstrate that, on average, HydraViT outperforms competing attention-guided methods by 1.2%, region-guided methods by 1.4%, and semantic-guided methods by 1.0% in multi-label classification performance.
CalibFPA: A Focal Plane Array Imaging System based on Online Deep-Learning Calibration
Sep 20, 2023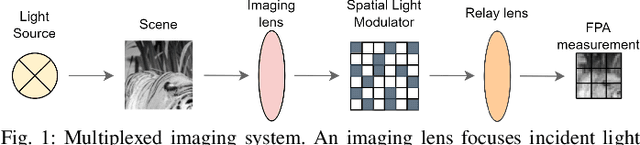
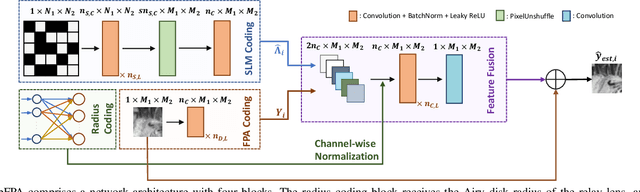
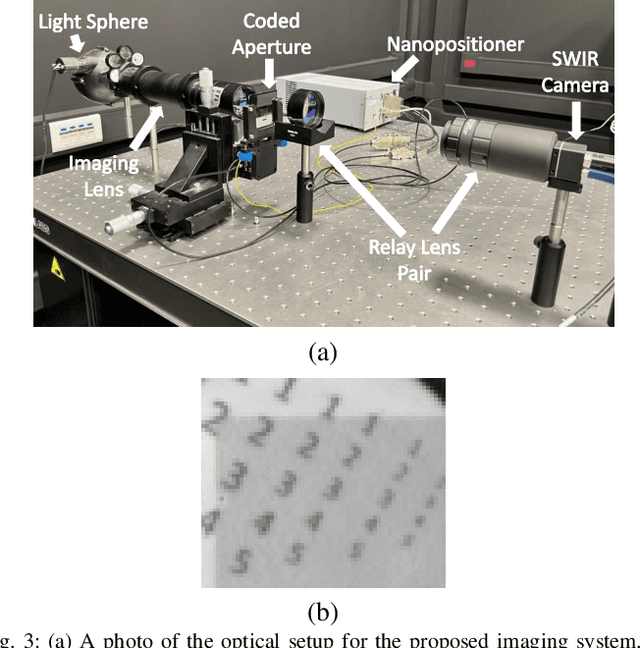
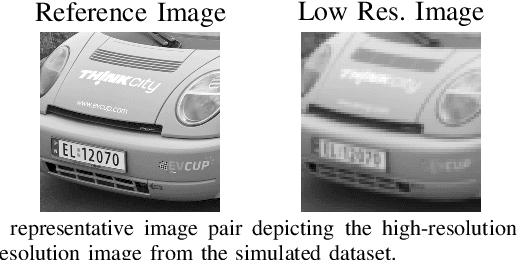
Compressive focal plane arrays (FPA) enable cost-effective high-resolution (HR) imaging by acquisition of several multiplexed measurements on a low-resolution (LR) sensor. Multiplexed encoding of the visual scene is typically performed via electronically controllable spatial light modulators (SLM). An HR image is then reconstructed from the encoded measurements by solving an inverse problem that involves the forward model of the imaging system. To capture system non-idealities such as optical aberrations, a mainstream approach is to conduct an offline calibration scan to measure the system response for a point source at each spatial location on the imaging grid. However, it is challenging to run calibration scans when using structured SLMs as they cannot encode individual grid locations. In this study, we propose a novel compressive FPA system based on online deep-learning calibration of multiplexed LR measurements (CalibFPA). We introduce a piezo-stage that locomotes a pre-printed fixed coded aperture. A deep neural network is then leveraged to correct for the influences of system non-idealities in multiplexed measurements without the need for offline calibration scans. Finally, a deep plug-and-play algorithm is used to reconstruct images from corrected measurements. On simulated and experimental datasets, we demonstrate that CalibFPA outperforms state-of-the-art compressive FPA methods. We also report analyses to validate the design elements in CalibFPA and assess computational complexity.
Learning Fourier-Constrained Diffusion Bridges for MRI Reconstruction
Aug 04, 2023



Recent years have witnessed a surge in deep generative models for accelerated MRI reconstruction. Diffusion priors in particular have gained traction with their superior representational fidelity and diversity. Instead of the target transformation from undersampled to fully-sampled data, common diffusion priors are trained to learn a multi-step transformation from Gaussian noise onto fully-sampled data. During inference, data-fidelity projections are injected in between reverse diffusion steps to reach a compromise solution within the span of both the diffusion prior and the imaging operator. Unfortunately, suboptimal solutions can arise as the normality assumption of the diffusion prior causes divergence between learned and target transformations. To address this limitation, here we introduce the first diffusion bridge for accelerated MRI reconstruction. The proposed Fourier-constrained diffusion bridge (FDB) leverages a generalized process to transform between undersampled and fully-sampled data via random noise addition and random frequency removal as degradation operators. Unlike common diffusion priors that use an asymptotic endpoint based on Gaussian noise, FDB captures a transformation between finite endpoints where the initial endpoint is based on moderate degradation of fully-sampled data. Demonstrations on brain MRI indicate that FDB outperforms state-of-the-art reconstruction methods including conventional diffusion priors.
DreaMR: Diffusion-driven Counterfactual Explanation for Functional MRI
Jul 18, 2023Deep learning analyses have offered sensitivity leaps in detection of cognitive states from functional MRI (fMRI) measurements across the brain. Yet, as deep models perform hierarchical nonlinear transformations on their input, interpreting the association between brain responses and cognitive states is challenging. Among common explanation approaches for deep fMRI classifiers, attribution methods show poor specificity and perturbation methods show limited plausibility. While counterfactual generation promises to address these limitations, previous methods use variational or adversarial priors that yield suboptimal sample fidelity. Here, we introduce the first diffusion-driven counterfactual method, DreaMR, to enable fMRI interpretation with high specificity, plausibility and fidelity. DreaMR performs diffusion-based resampling of an input fMRI sample to alter the decision of a downstream classifier, and then computes the minimal difference between the original and counterfactual samples for explanation. Unlike conventional diffusion methods, DreaMR leverages a novel fractional multi-phase-distilled diffusion prior to improve sampling efficiency without compromising fidelity, and it employs a transformer architecture to account for long-range spatiotemporal context in fMRI scans. Comprehensive experiments on neuroimaging datasets demonstrate the superior specificity, fidelity and efficiency of DreaMR in sample generation over state-of-the-art counterfactual methods for fMRI interpretation.
FD-Net: An Unsupervised Deep Forward-Distortion Model for Susceptibility Artifact Correction in EPI
Mar 18, 2023Recent learning-based correction approaches in EPI estimate a displacement field, unwarp the reversed-PE image pair with the estimated field, and average the unwarped pair to yield a corrected image. Unsupervised learning in these unwarping-based methods is commonly attained via a similarity constraint between the unwarped images in reversed-PE directions, neglecting consistency to the acquired EPI images. This work introduces an unsupervised deep-learning method for fast and effective correction of susceptibility artifacts in reversed phase-encode (PE) image pairs acquired with EPI. FD-Net predicts both the susceptibility-induced displacement field and the underlying anatomically-correct image. Unlike previous methods, FD-Net enforces the forward-distortions of the correct image in both PE directions to be consistent with the acquired reversed-PE image pair. FD-Net further leverages a multiresolution architecture to maintain high local and global performance. FD-Net performs competitively with a gold-standard reference method (TOPUP) in image quality, while enabling a leap in computational efficiency. Furthermore, FD-Net outperforms recent unwarping-based methods for unsupervised correction in terms of both image and field quality. The unsupervised FD-Net method introduces a deep forward-distortion approach to enable fast, high-fidelity correction of susceptibility artifacts in EPI by maintaining consistency to measured data. Therefore, it holds great promise for improving the anatomical accuracy of EPI imaging.
Learning Deep MRI Reconstruction Models from Scratch in Low-Data Regimes
Jan 06, 2023Magnetic resonance imaging (MRI) is an essential diagnostic tool that suffers from prolonged scan times. Reconstruction methods can alleviate this limitation by recovering clinically usable images from accelerated acquisitions. In particular, learning-based methods promise performance leaps by employing deep neural networks as data-driven priors. A powerful approach uses scan-specific (SS) priors that leverage information regarding the underlying physical signal model for reconstruction. SS priors are learned on each individual test scan without the need for a training dataset, albeit they suffer from computationally burdening inference with nonlinear networks. An alternative approach uses scan-general (SG) priors that instead leverage information regarding the latent features of MRI images for reconstruction. SG priors are frozen at test time for efficiency, albeit they require learning from a large training dataset. Here, we introduce a novel parallel-stream fusion model (PSFNet) that synergistically fuses SS and SG priors for performant MRI reconstruction in low-data regimes, while maintaining competitive inference times to SG methods. PSFNet implements its SG prior based on a nonlinear network, yet it forms its SS prior based on a linear network to maintain efficiency. A pervasive framework for combining multiple priors in MRI reconstruction is algorithmic unrolling that uses serially alternated projections, causing error propagation under low-data regimes. To alleviate error propagation, PSFNet combines its SS and SG priors via a novel parallel-stream architecture with learnable fusion parameters. Demonstrations are performed on multi-coil brain MRI for varying amounts of training data. PSFNet outperforms SG methods in low-data regimes, and surpasses SS methods with few tens of training samples.
A plug-in graph neural network to boost temporal sensitivity in fMRI analysis
Jan 01, 2023Learning-based methods have recently enabled performance leaps in analysis of high-dimensional functional MRI (fMRI) time series. Deep learning models that receive as input functional connectivity (FC) features among brain regions have been commonly adopted in the literature. However, many models focus on temporally static FC features across a scan, reducing sensitivity to dynamic features of brain activity. Here, we describe a plug-in graph neural network that can be flexibly integrated into a main learning-based fMRI model to boost its temporal sensitivity. Receiving brain regions as nodes and blood-oxygen-level-dependent (BOLD) signals as node inputs, the proposed GraphCorr method leverages a node embedder module based on a transformer encoder to capture temporally-windowed latent representations of BOLD signals. GraphCorr also leverages a lag filter module to account for delayed interactions across nodes by computing cross-correlation of windowed BOLD signals across a range of time lags. Information captured by the two modules is fused via a message passing algorithm executed on the graph, and enhanced node features are then computed at the output. These enhanced features are used to drive a subsequent learning-based model to analyze fMRI time series with elevated sensitivity. Comprehensive demonstrations on two public datasets indicate improved classification performance and interpretability for several state-of-the-art graphical and convolutional methods that employ GraphCorr-derived feature representations of fMRI time series as their input.
DEQ-MPI: A Deep Equilibrium Reconstruction with Learned Consistency for Magnetic Particle Imaging
Dec 26, 2022Magnetic particle imaging (MPI) offers unparalleled contrast and resolution for tracing magnetic nanoparticles. A common imaging procedure calibrates a system matrix (SM) that is used to reconstruct data from subsequent scans. The ill-posed reconstruction problem can be solved by simultaneously enforcing data consistency based on the SM and regularizing the solution based on an image prior. Traditional hand-crafted priors cannot capture the complex attributes of MPI images, whereas recent MPI methods based on learned priors can suffer from extensive inference times or limited generalization performance. Here, we introduce a novel physics-driven method for MPI reconstruction based on a deep equilibrium model with learned data consistency (DEQ-MPI). DEQ-MPI reconstructs images by augmenting neural networks into an iterative optimization, as inspired by unrolling methods in deep learning. Yet, conventional unrolling methods are computationally restricted to few iterations resulting in non-convergent solutions, and they use hand-crafted consistency measures that can yield suboptimal capture of the data distribution. DEQ-MPI instead trains an implicit mapping to maximize the quality of a convergent solution, and it incorporates a learned consistency measure to better account for the data distribution. Demonstrations on simulated and experimental data indicate that DEQ-MPI achieves superior image quality and competitive inference time to state-of-the-art MPI reconstruction methods.
Unsupervised Simplification of Legal Texts
Sep 01, 2022
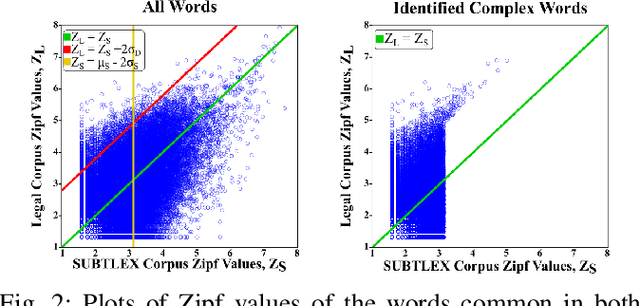
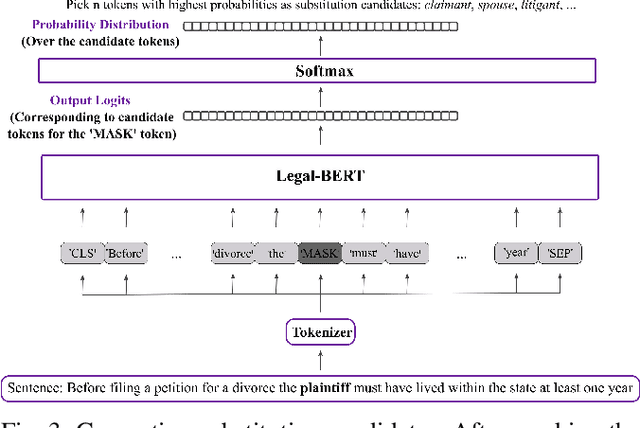

The processing of legal texts has been developing as an emerging field in natural language processing (NLP). Legal texts contain unique jargon and complex linguistic attributes in vocabulary, semantics, syntax, and morphology. Therefore, the development of text simplification (TS) methods specific to the legal domain is of paramount importance for facilitating comprehension of legal text by ordinary people and providing inputs to high-level models for mainstream legal NLP applications. While a recent study proposed a rule-based TS method for legal text, learning-based TS in the legal domain has not been considered previously. Here we introduce an unsupervised simplification method for legal texts (USLT). USLT performs domain-specific TS by replacing complex words and splitting long sentences. To this end, USLT detects complex words in a sentence, generates candidates via a masked-transformer model, and selects a candidate for substitution based on a rank score. Afterward, USLT recursively decomposes long sentences into a hierarchy of shorter core and context sentences while preserving semantic meaning. We demonstrate that USLT outperforms state-of-the-art domain-general TS methods in text simplicity while keeping the semantics intact.
Unsupervised Medical Image Translation with Adversarial Diffusion Models
Jul 17, 2022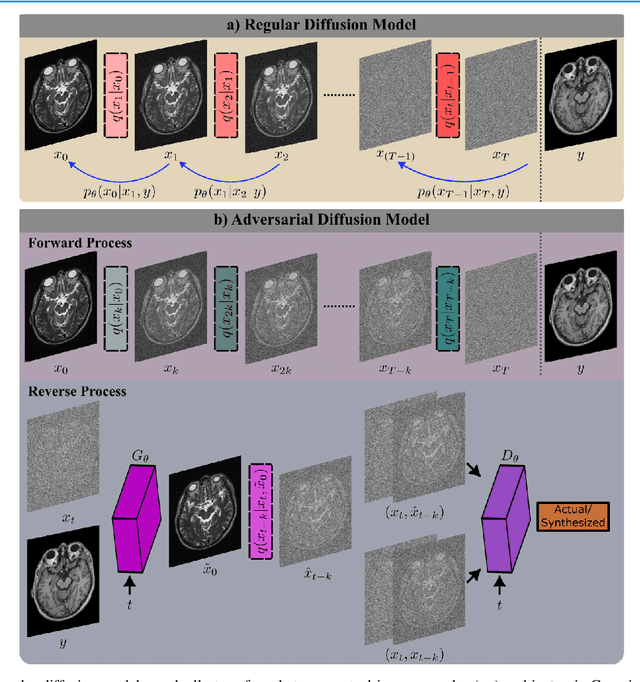
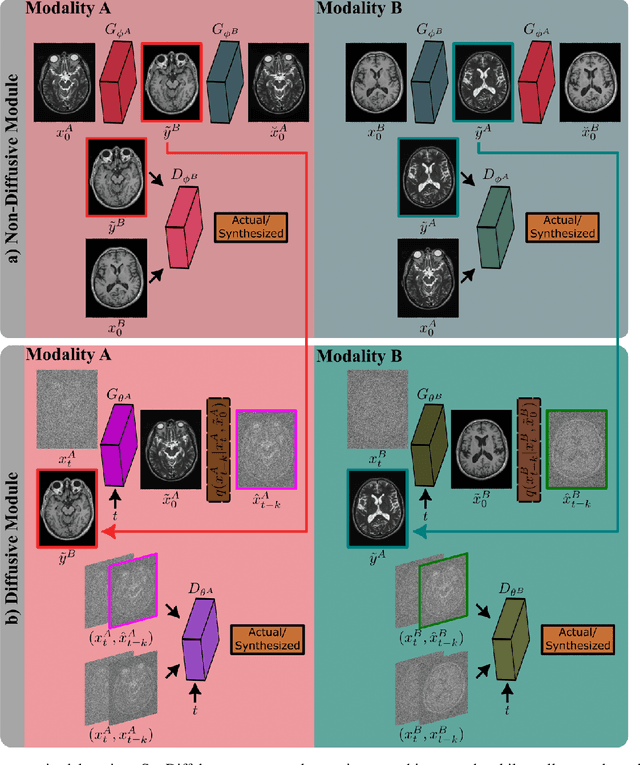
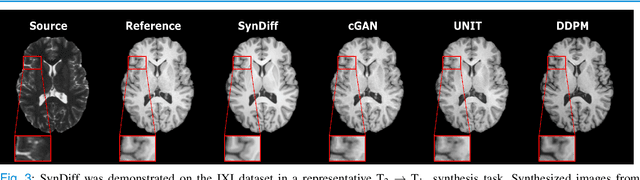
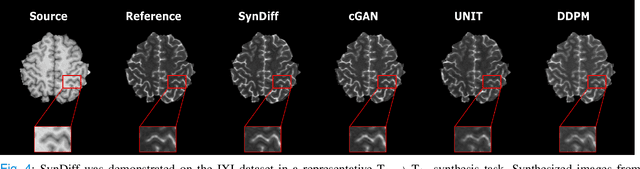
Imputation of missing images via source-to-target modality translation can facilitate downstream tasks in medical imaging. A pervasive approach for synthesizing target images involves one-shot mapping through generative adversarial networks (GAN). Yet, GAN models that implicitly characterize the image distribution can suffer from limited sample fidelity and diversity. Here, we propose a novel method based on adversarial diffusion modeling, SynDiff, for improved reliability in medical image synthesis. To capture a direct correlate of the image distribution, SynDiff leverages a conditional diffusion process to progressively map noise and source images onto the target image. For fast and accurate image sampling during inference, large diffusion steps are coupled with adversarial projections in the reverse diffusion direction. To enable training on unpaired datasets, a cycle-consistent architecture is devised with two coupled diffusion processes to synthesize the target given source and the source given target. Extensive assessments are reported on the utility of SynDiff against competing GAN and diffusion models in multi-contrast MRI and MRI-CT translation. Our demonstrations indicate that SynDiff offers superior performance against competing baselines both qualitatively and quantitatively.