 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Future of Work to Future of Workers: Addressing Asymptomatic AI Harms for Dignified Human-AI Interaction
Jan 29, 2026In the future of work discourse, AI is touted as the ultimate productivity amplifier. Yet, beneath the efficiency gains lie subtle erosions of human expertise and agency. This paper shifts focus from the future of work to the future of workers by navigating the AI-as-Amplifier Paradox: AI's dual role as enhancer and eroder, simultaneously strengthening performance while eroding underlying expertise. We present a year-long study on the longitudinal use of AI in a high-stakes workplace among cancer specialists. Initial operational gains hid ``intuition rust'': the gradual dulling of expert judgment. These asymptomatic effects evolved into chronic harms, such as skill atrophy and identity commoditization. Building on these findings, we offer a framework for dignified Human-AI interaction co-constructed with professional knowledge workers facing AI-induced skill erosion without traditional labor protections. The framework operationalizes sociotechnical immunity through dual-purpose mechanisms that serve institutional quality goals while building worker power to detect, contain, and recover from skill erosion, and preserve human identity. Evaluated across healthcare and software engineering, our work takes a foundational step toward dignified human-AI interaction futures by balancing productivity with the preservation of human expertise.
A novel data-driven algorithm to predict anomalous prescription based on patient's feature set
Nov 30, 2021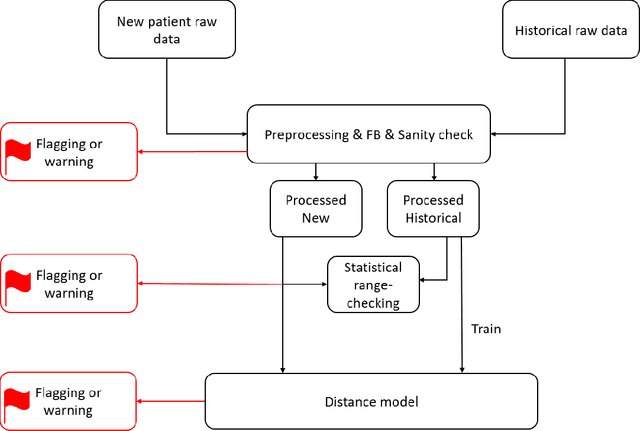
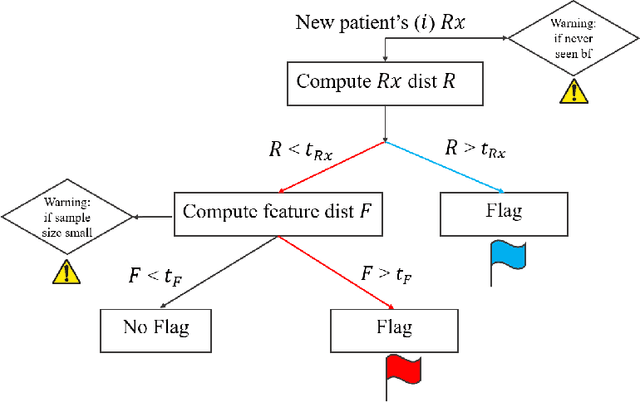
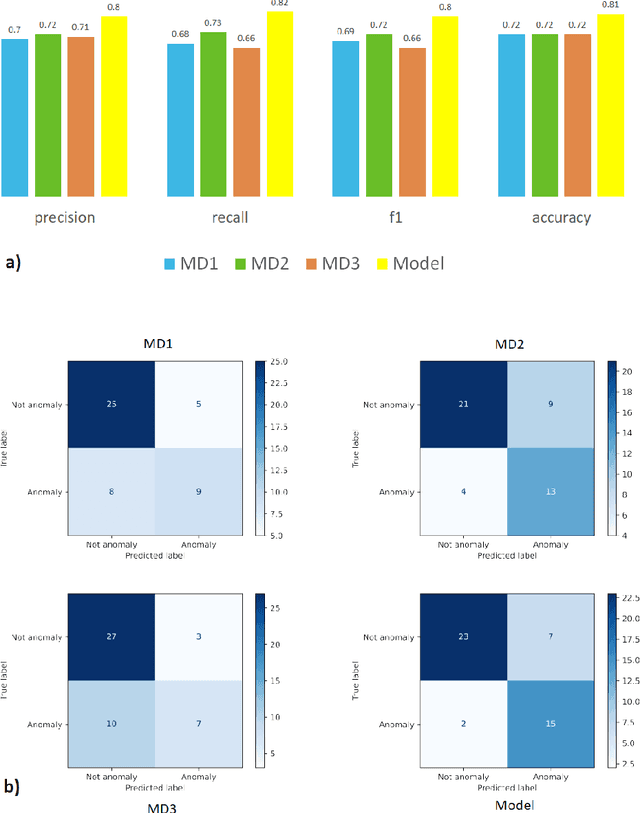
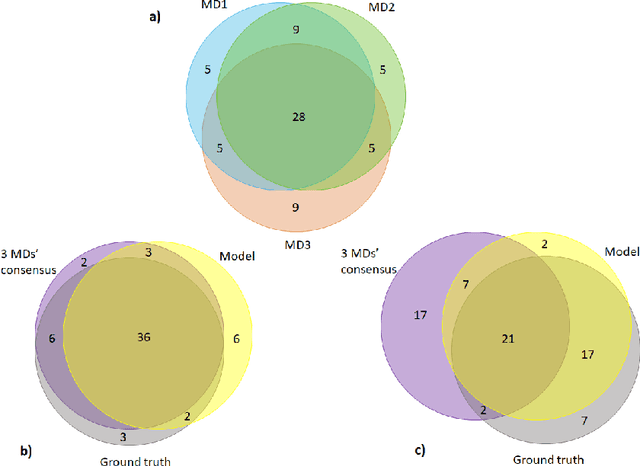
Appropriate dosing of radiation is crucial to patient safety in radiotherapy. Current quality assurance depends heavily on a peer-review process, where the physicians' peer review on each patient's treatment plan, including dose and fractionation. However, such a process is manual and laborious. Physicians may not identify errors due to time constraints and caseload. We designed a novel prescription anomaly detection algorithm that utilizes historical data to predict anomalous cases. Such a tool can serve as an electronic peer who will assist the peer-review process providing extra safety to the patients. In our primary model, we created two dissimilarity metrics, R and F. R defining how far a new patient's prescription is from historical prescriptions. F represents how far away a patient's feature set is from the group with an identical or similar prescription. We flag prescription if either metric is greater than specific optimized cut-off values. We used thoracic cancer patients (n=2356) as an example and extracted seven features. Here, we report our testing f1 score, between 75%-94% for different treatment technique groups. We also independently validate our results by conducting a mock peer review with three thoracic specialists. Our model has a lower type 2 error rate compared to manual peer-review physicians. Our model has many advantages over traditional machine learning algorithms, particularly in that it does not suffer from class imbalance. It can also explain why it flags each case and separate prescription and non-prescription-related features without learning from the data.