 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Constraint Programming: A Scenario-Based Approach
Mar 06, 2009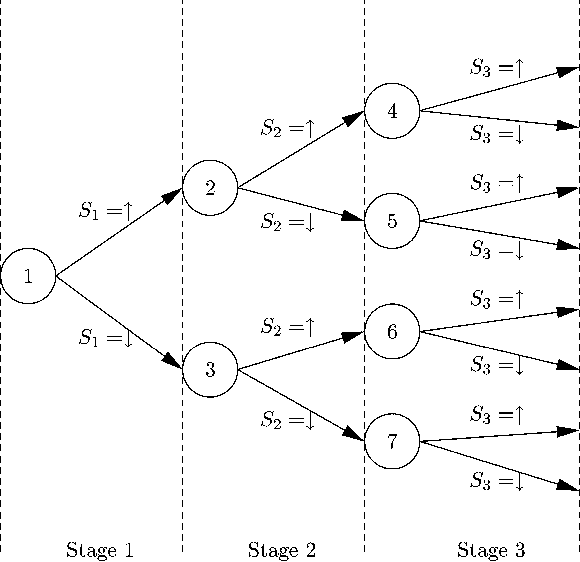
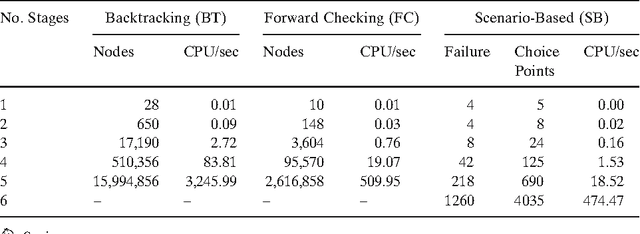
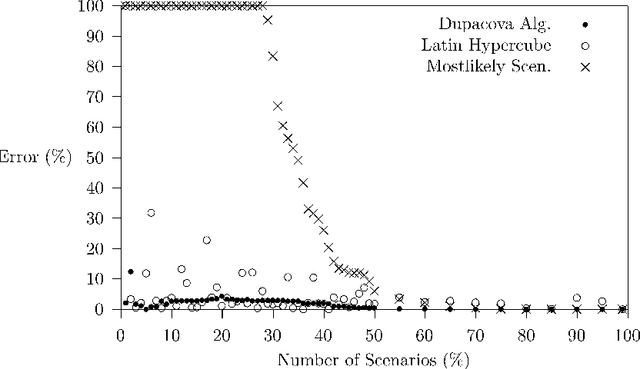

To model combinatorial decision problems involving uncertainty and probability, we introduce scenario based stochastic constraint programming. Stochastic constraint programs contain both decision variables, which we can set, and stochastic variables, which follow a discrete probability distribution. We provide a semantics for stochastic constraint programs based on scenario trees. Using this semantics, we can compile stochastic constraint programs down into conventional (non-stochastic) constraint programs. This allows us to exploit the full power of existing constraint solvers. We have implemented this framework for decision making under uncertainty in stochastic OPL, a language which is based on the OPL constraint modelling language [Hentenryck et al., 1999]. To illustrate the potential of this framework, we model a wide range of problems in areas as diverse as portfolio diversification, agricultural planning and production/inventory management.
Tetravex is NP-complete
Mar 06, 2009
Tetravex is a widely played one person computer game in which you are given $n^2$ unit tiles, each edge of which is labelled with a number. The objective is to place each tile within a $n$ by $n$ square such that all neighbouring edges are labelled with an identical number. Unfortunately, playing Tetravex is computationally hard. More precisely, we prove that deciding if there is a tiling of the Tetravex board is NP-complete. Deciding where to place the tiles is therefore NP-hard. This may help to explain why Tetravex is a good puzzle. This result compliments a number of similar results for one person games involving tiling. For example, NP-completeness results have been shown for: the offline version of Tetris, KPlumber (which involves rotating tiles containing drawings of pipes to make a connected network), and shortest sliding puzzle problems. It raises a number of open questions. For example, is the infinite version Turing-complete? How do we generate Tetravex problems which are truly puzzling as random NP-complete problems are often surprising easy to solve? Can we observe phase transition behaviour? What about the complexity of the problem when it is guaranteed to have an unique solution? How do we generate puzzles with unique solutions?
Breaking Value Symmetry
Mar 06, 2009One common type of symmetry is when values are symmetric. For example, if we are assigning colours (values) to nodes (variables) in a graph colouring problem then we can uniformly interchange the colours throughout a colouring. For a problem with value symmetries, all symmetric solutions can be eliminated in polynomial time. However, as we show here, both static and dynamic methods to deal with symmetry have computational limitations. With static methods, pruning all symmetric values is NP-hard in general. With dynamic methods, we can take exponential time on problems which static methods solve without search.
The Complexity of Reasoning with Global Constraints
Mar 06, 2009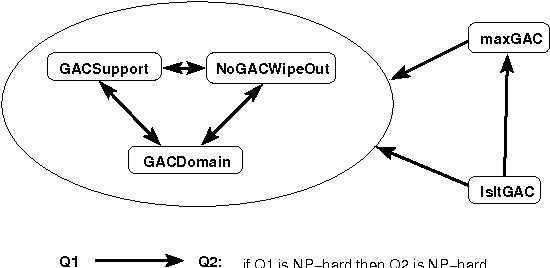
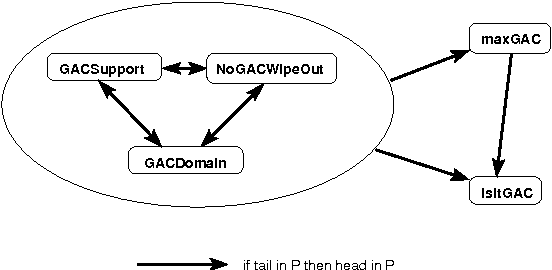
Constraint propagation is one of the techniques central to the success of constraint programming. To reduce search, fast algorithms associated with each constraint prune the domains of variables. With global (or non-binary) constraints, the cost of such propagation may be much greater than the quadratic cost for binary constraints. We therefore study the computational complexity of reasoning with global constraints. We first characterise a number of important questions related to constraint propagation. We show that such questions are intractable in general, and identify dependencies between the tractability and intractability of the different questions. We then demonstrate how the tools of computational complexity can be used in the design and analysis of specific global constraints. In particular, we illustrate how computational complexity can be used to determine when a lesser level of local consistency should be enforced, when constraints can be safely generalized, when decomposing constraints will reduce the amount of pruning, and when combining constraints is tractable.
Complexity of Terminating Preference Elicitation
Mar 06, 2009Complexity theory is a useful tool to study computational issues surrounding the elicitation of preferences, as well as the strategic manipulation of elections aggregating together preferences of multiple agents. We study here the complexity of determining when we can terminate eliciting preferences, and prove that the complexity depends on the elicitation strategy. We show, for instance, that it may be better from a computational perspective to elicit all preferences from one agent at a time than to elicit individual preferences from multiple agents. We also study the connection between the strategic manipulation of an election and preference elicitation. We show that what we can manipulate affects the computational complexity of manipulation. In particular, we prove that there are voting rules which are easy to manipulate if we can change all of an agent's vote, but computationally intractable if we can change only some of their preferences. This suggests that, as with preference elicitation, a fine-grained view of manipulation may be informative. Finally, we study the connection between predicting the winner of an election and preference elicitation. Based on this connection, we identify a voting rule where it is computationally difficult to decide the probability of a candidate winning given a probability distribution over the votes.
* 7th International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS 2008)
Symmetry Breaking Using Value Precedence
Mar 06, 2009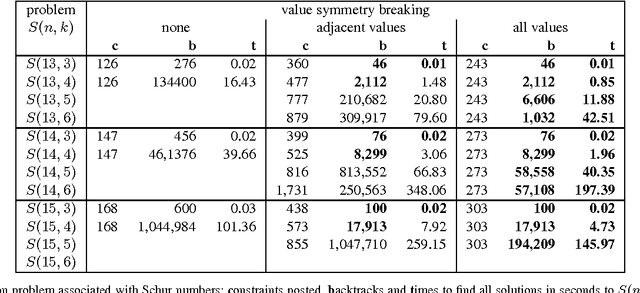
We present a comprehensive study of the use of value precedence constraints to break value symmetry. We first give a simple encoding of value precedence into ternary constraints that is both efficient and effective at breaking symmetry. We then extend value precedence to deal with a number of generalizations like wreath value and partial interchangeability. We also show that value precedence is closely related to lexicographical ordering. Finally, we consider the interaction between value precedence and symmetry breaking constraints for variable symmetries.
* 17th European Conference on Artificial Intelligence
Online Estimation of SAT Solving Runtime
Mar 04, 2009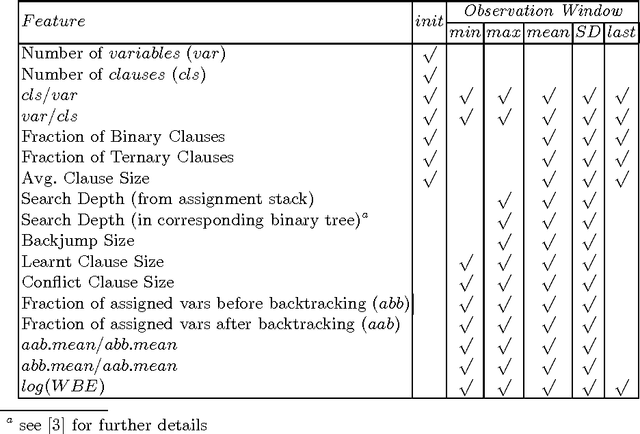
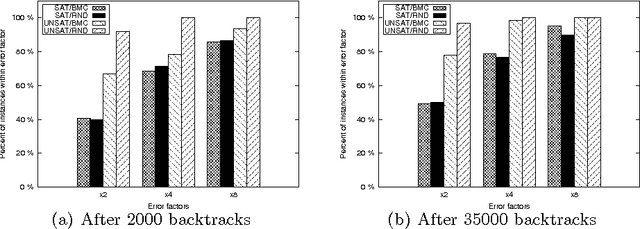
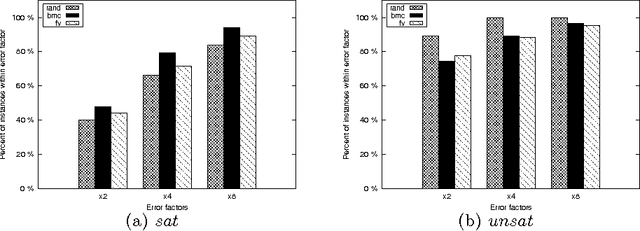
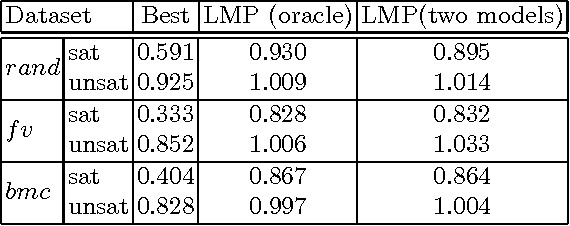
We present an online method for estimating the cost of solving SAT problems. Modern SAT solvers present several challenges to estimate search cost including non-chronological backtracking, learning and restarts. Our method uses a linear model trained on data gathered at the start of search. We show the effectiveness of this method using random and structured problems. We demonstrate that predictions made in early restarts can be used to improve later predictions. We also show that we can use such cost estimations to select a solver from a portfolio.
Combining Symmetry Breaking and Global Constraints
Mar 03, 2009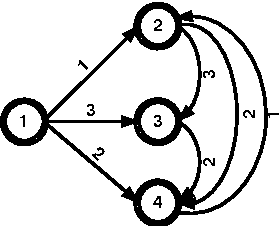
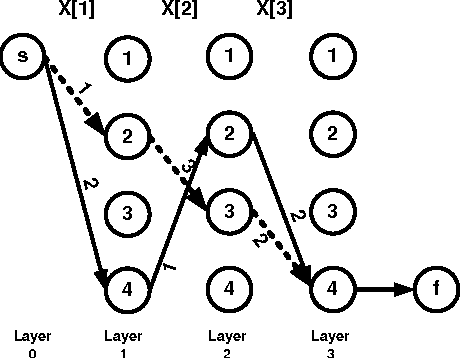
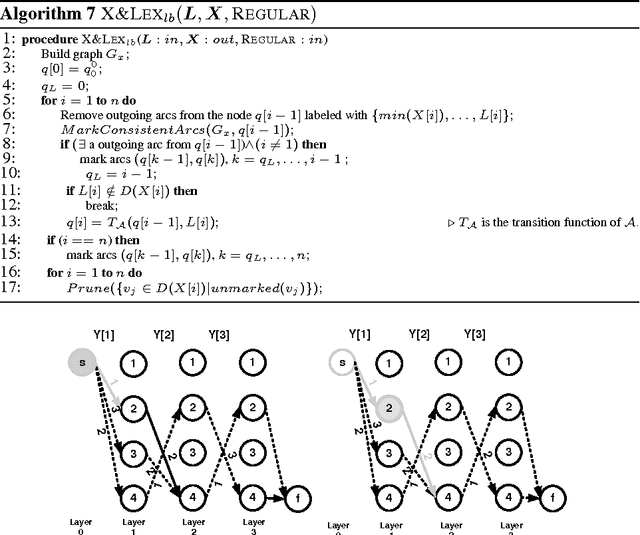
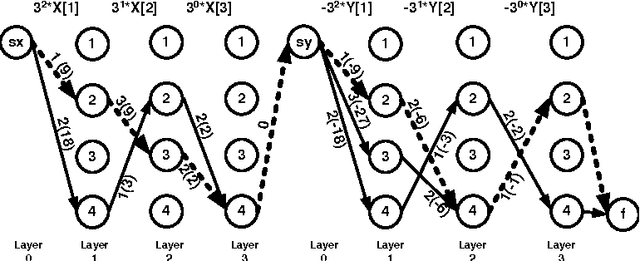
We propose a new family of constraints which combine together lexicographical ordering constraints for symmetry breaking with other common global constraints. We give a general purpose propagator for this family of constraints, and show how to improve its complexity by exploiting properties of the included global constraints.
Reformulating Global Grammar Constraints
Mar 03, 2009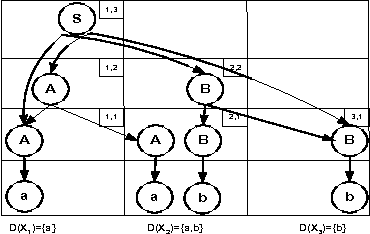
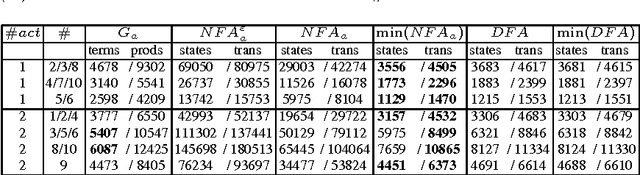
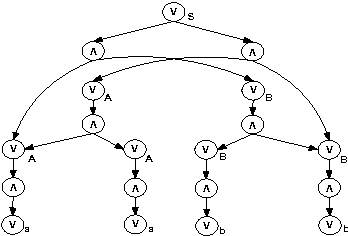
An attractive mechanism to specify global constraints in rostering and other domains is via formal languages. For instance, the Regular and Grammar constraints specify constraints in terms of the languages accepted by an automaton and a context-free grammar respectively. Taking advantage of the fixed length of the constraint, we give an algorithm to transform a context-free grammar into an automaton. We then study the use of minimization techniques to reduce the size of such automata and speed up propagation. We show that minimizing such automata after they have been unfolded and domains initially reduced can give automata that are more compact than minimizing before unfolding and reducing. Experimental results show that such transformations can improve the size of rostering problems that we can 'model and run'.
SLIDE: A Useful Special Case of the CARDPATH Constraint
Mar 03, 2009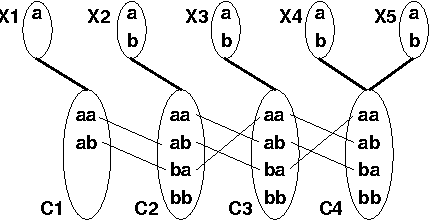
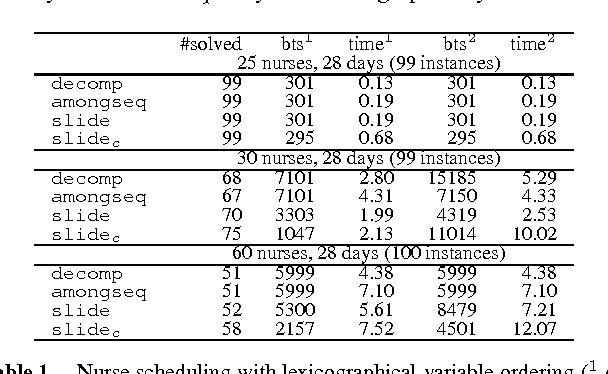
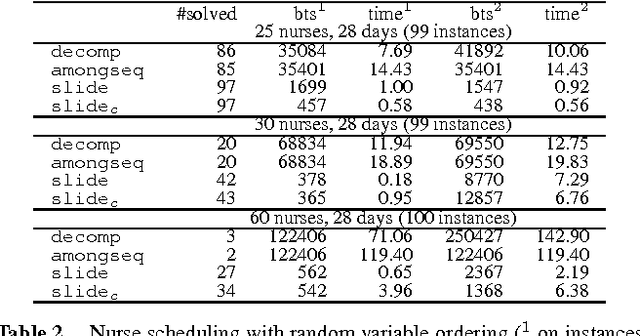
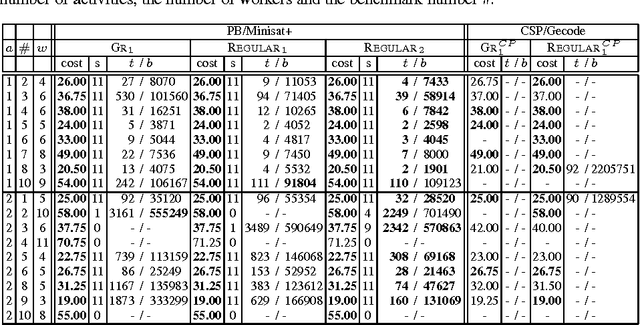
We study the CardPath constraint. This ensures a given constraint holds a number of times down a sequence of variables. We show that SLIDE, a special case of CardPath where the slid constraint must hold always, can be used to encode a wide range of sliding sequence constraints including CardPath itself. We consider how to propagate SLIDE and provide a complete propagator for CardPath. Since propagation is NP-hard in general, we identify special cases where propagation takes polynomial time. Our experiments demonstrate that using SLIDE to encode global constraints can be as efficient and effective as specialised propagators.
* 18th European Conference on Artificial Intelligence