 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effectiveness of Style Vectors for Steering Large Language Models: A Human Evaluation
Jan 29, 2026Controlling the behavior of large language models (LLMs) at inference time is essential for aligning outputs with human abilities and safety requirements. \emph{Activation steering} provides a lightweight alternative to prompt engineering and fine-tuning by directly modifying internal activations to guide generation. This research advances the literature in three significant directions. First, while previous work demonstrated the technical feasibility of steering emotional tone using automated classifiers, this paper presents the first human evaluation of activation steering concerning the emotional tone of LLM outputs, collecting over 7,000 crowd-sourced ratings from 190 participants via Prolific ($n=190$). These ratings assess both perceived emotional intensity and overall text quality. Second, we find strong alignment between human and model-based quality ratings (mean $r=0.776$, range $0.157$--$0.985$), indicating automatic scoring can proxy perceived quality. Moderate steering strengths ($λ\approx 0.15$) reliably amplify target emotions while preserving comprehensibility, with the strongest effects for disgust ($η_p^2 = 0.616$) and fear ($η_p^2 = 0.540$), and minimal effects for surprise ($η_p^2 = 0.042$). Finally, upgrading from Alpaca to LlaMA-3 yielded more consistent steering with significant effects across emotions and strengths (all $p < 0.001$). Inter-rater reliability was high (ICC $= 0.71$--$0.87$), underscoring the robustness of the findings. These findings support activation-based control as a scalable method for steering LLM behavior across affective dimensions.
Towards a Reliable Offline Personal AI Assistant for Long Duration Spaceflight
Oct 21, 2024

As humanity prepares for new missions to the Moon and Mars, astronauts will need to operate with greater autonomy, given the communication delays that make real-time support from Earth difficult. For instance, messages between Mars and Earth can take up to 24 minutes, making quick responses impossible. This limitation poses a challenge for astronauts who must rely on in-situ tools to access the large volume of data from spacecraft sensors, rovers, and satellites, data that is often fragmented and difficult to use. To bridge this gap, systems like the Mars Exploration Telemetry-Driven Information System (METIS) are being developed. METIS is an AI assistant designed to handle routine tasks, monitor spacecraft systems, and detect anomalies, all while reducing the reliance on mission control. Current Generative Pretrained Transformer (GPT) Models, while powerful, struggle in safety-critical environments. They can generate plausible but incorrect responses, a phenomenon known as "hallucination," which could endanger astronauts. To overcome these limitations, this paper proposes enhancing systems like METIS by integrating GPTs, Retrieval-Augmented Generation (RAG), Knowledge Graphs (KGs), and Augmented Reality (AR). The idea is to allow astronauts to interact with their data more intuitively, using natural language queries and visualizing real-time information through AR. KGs will be used to easily access live telemetry and multimodal data, ensuring that astronauts have the right information at the right time. By combining AI, KGs, and AR, this new system will empower astronauts to work more autonomously, safely, and efficiently during future space missions.
AI Assistants for Spaceflight Procedures: Combining Generative Pre-Trained Transformer and Retrieval-Augmented Generation on Knowledge Graphs With Augmented Reality Cues
Sep 21, 2024
This paper describes the capabilities and potential of the intelligent personal assistant (IPA) CORE (Checklist Organizer for Research and Exploration), designed to support astronauts during procedures onboard the International Space Station (ISS), the Lunar Gateway station, and beyond. We reflect on the importance of a reliable and flexible assistant capable of offline operation and highlight the usefulness of audiovisual interaction using augmented reality elements to intuitively display checklist information. We argue that current approaches to the design of IPAs in space operations fall short of meeting these criteria. Therefore, we propose CORE as an assistant that combines Knowledge Graphs (KGs), Retrieval-Augmented Generation (RAG) for a Generative Pre-Trained Transformer (GPT), and Augmented Reality (AR) elements to ensure an intuitive understanding of procedure steps, reliability, offline availability, and flexibility in terms of response style and procedure updates.
Style Vectors for Steering Generative Large Language Model
Feb 02, 2024



This research explores strategies for steering the output of large language models (LLMs) towards specific styles, such as sentiment, emotion, or writing style, by adding style vectors to the activations of hidden layers during text generation. We show that style vectors can be simply computed from recorded layer activations for input texts in a specific style in contrast to more complex training-based approaches. Through a series of experiments, we demonstrate the effectiveness of activation engineering using such style vectors to influence the style of generated text in a nuanced and parameterisable way, distinguishing it from prompt engineering. The presented research constitutes a significant step towards developing more adaptive and effective AI-empowered interactive systems.
Predicting Winning Regions in Parity Games via Graph Neural Networks (Extended Abstract)
Oct 18, 2022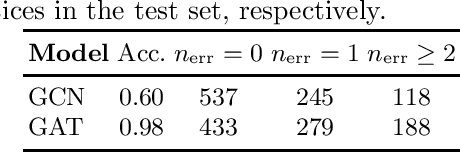
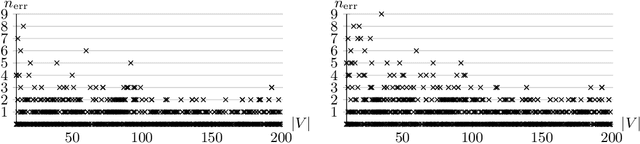
Solving parity games is a major building block for numerous applications in reactive program verification and synthesis. While there exist efficient approaches to solving parity games in practice, none of these have a polynomial worst-case runtime complexity. We present a incomplete approach to determining the winning regions of parity games via graph neural networks. Our evaluation on 900 randomly generated parity games shows that this approach is efficient in practice. It moreover correctly determines the winning regions of ~60% of the games in our data set and only incurs minor errors in the remaining ones.
Topic Modelling of Empirical Text Corpora: Validity, Reliability, and Reproducibility in Comparison to Semantic Maps
Jun 04, 2018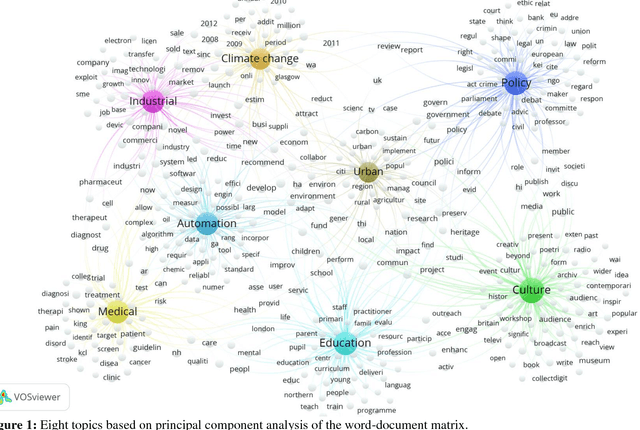
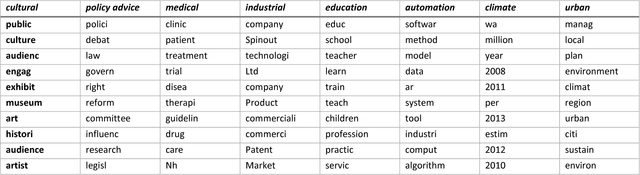
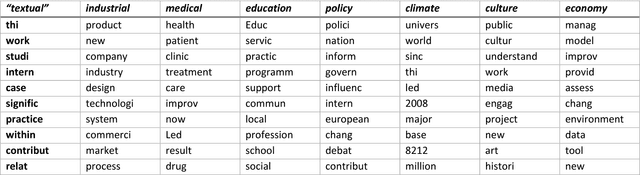
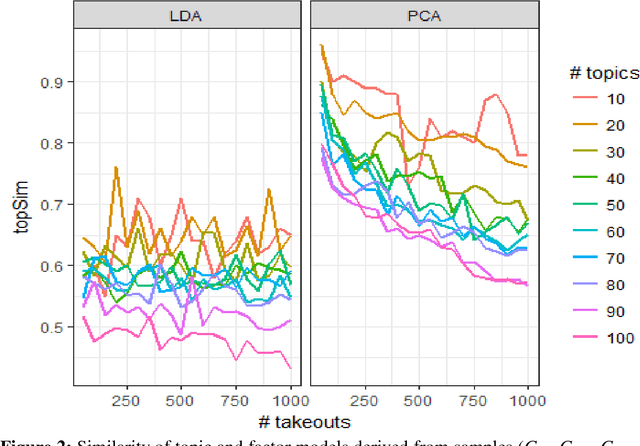
Using the 6,638 case descriptions of societal impact submitted for evaluation in the Research Excellence Framework (REF 2014), we replicate the topic model (Latent Dirichlet Allocation or LDA) made in this context and compare the results with factor-analytic results using a traditional word-document matrix (Principal Component Analysis or PCA). Removing a small fraction of documents from the sample, for example, has on average a much larger impact on LDA than on PCA-based models to the extent that the largest distortion in the case of PCA has less effect than the smallest distortion of LDA-based models. In terms of semantic coherence, however, LDA models outperform PCA-based models. The topic models inform us about the statistical properties of the document sets under study, but the results are statistical and should not be used for a semantic interpretation - for example, in grant selections and micro-decision making, or scholarly work-without follow-up using domain-specific semantic maps.