 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Hardware Supported Domain Generalization in DNN-Based Edge Computing Devices for Health Monitoring
Mar 12, 2025



Deep neural network (DNN) models have shown remarkable success in many real-world scenarios, such as object detection and classification. Unfortunately, these models are not yet widely adopted in health monitoring due to exceptionally high requirements for model robustness and deployment in highly resource-constrained devices. In particular, the acquisition of biosignals, such as electrocardiogram (ECG), is subject to large variations between training and deployment, necessitating domain generalization (DG) for robust classification quality across sensors and patients. The continuous monitoring of ECG also requires the execution of DNN models in convenient wearable devices, which is achieved by specialized ECG accelerators with small form factor and ultra-low power consumption. However, combining DG capabilities with ECG accelerators remains a challenge. This article provides a comprehensive overview of ECG accelerators and DG methods and discusses the implication of the combination of both domains, such that multi-domain ECG monitoring is enabled with emerging algorithm-hardware co-optimized systems. Within this context, an approach based on correction layers is proposed to deploy DG capabilities on the edge. Here, the DNN fine-tuning for unknown domains is limited to a single layer, while the remaining DNN model remains unmodified. Thus, computational complexity (CC) for DG is reduced with minimal memory overhead compared to conventional fine-tuning of the whole DNN model. The DNN model-dependent CC is reduced by more than 2.5x compared to DNN fine-tuning at an average increase of F1 score by more than 20% on the generalized target domain. In summary, this article provides a novel perspective on robust DNN classification on the edge for health monitoring applications.
Post-Training Quantization for Energy Efficient Realization of Deep Neural Networks
Oct 14, 2022
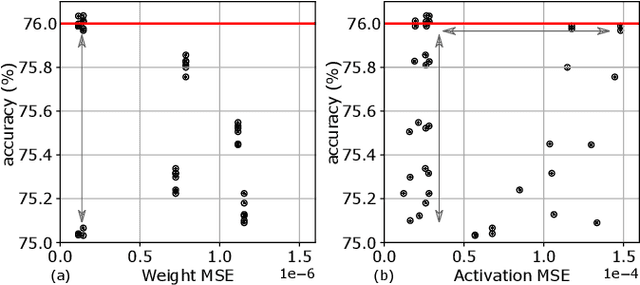
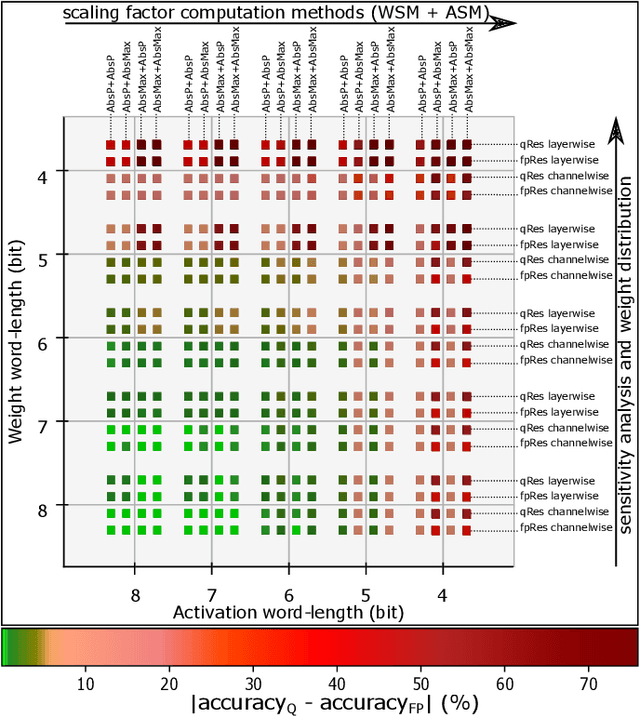
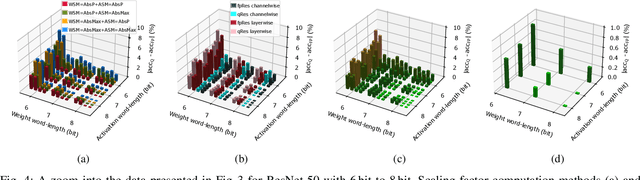
The biggest challenge for the deployment of Deep Neural Networks (DNNs) close to the generated data on edge devices is their size, i.e., memory footprint and computational complexity. Both are significantly reduced with quantization. With the resulting lower word-length, the energy efficiency of DNNs increases proportionally. However, lower word-length typically causes accuracy degradation. To counteract this effect, the quantized DNN is retrained. Unfortunately, training costs up to 5000x more energy than the inference of the quantized DNN. To address this issue, we propose a post-training quantization flow without the need for retraining. For this, we investigated different quantization options. Furthermore, our analysis systematically assesses the impact of reduced word-lengths of weights and activations revealing a clear trend for the choice of word-length. Both aspects have not been systematically investigated so far. Our results are independent of the depth of the DNNs and apply to uniform quantization, allowing fast quantization of a given pre-trained DNN. We excel state-of-the-art for 6 bit by 2.2% Top-1 accuracy for ImageNet. Without retraining, our quantization to 8 bit surpasses floating-point accuracy.
Design of High-Throughput Mixed-Precision CNN Accelerators on FPGA
Aug 09, 2022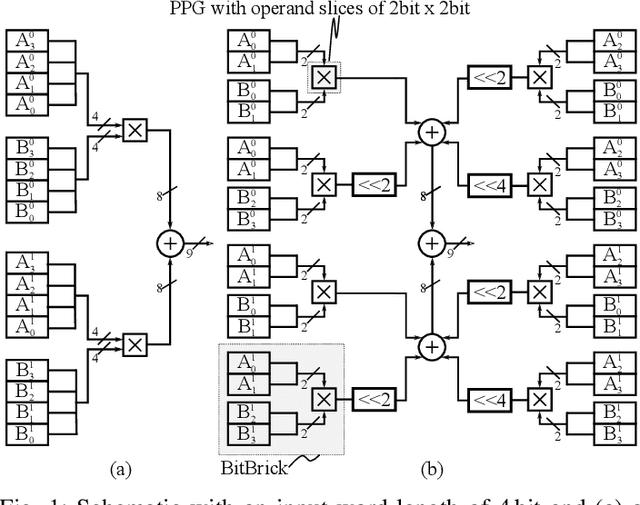
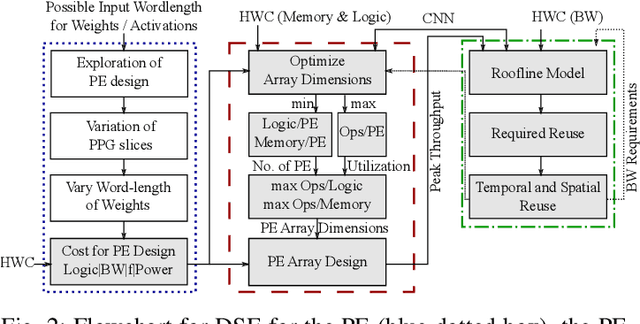
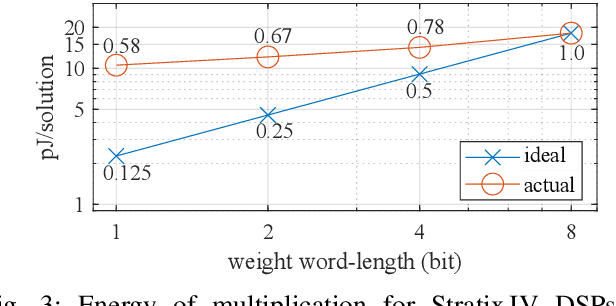
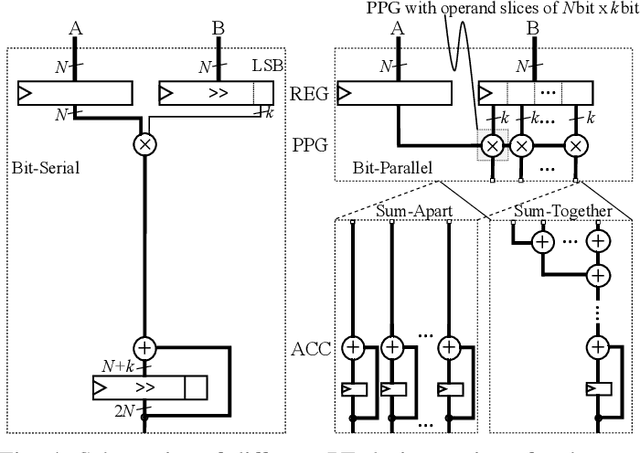
Convolutional Neural Networks (CNNs) reach high accuracies in various application domains, but require large amounts of computation and incur costly data movements. One method to decrease these costs while trading accuracy is weight and/or activation word-length reduction. Thereby, layer-wise mixed-precision quantization allows for more efficient results while inflating the design space. In this work, we present an in-depth quantitative methodology to efficiently explore the design space considering the limited hardware resources of a given FPGA. Our holistic exploration approach vertically traverses the various design entry levels from the architectural down to the logic level, and laterally covers optimization from processing elements to dataflow for an efficient mixed-precision CNN accelerator. Our resulting hardware accelerators implement truly mixed-precision operations that enable efficient execution of layer-wise and channel-wise quantized CNNs. Mapping feed-forward and identity-shortcut-connection mixed-precision CNNs result in competitive accuracy-throughout trade-offs: 245 frames/s with 87.48% Top-5 accuracy for ResNet-18 and 92.9% Top-5 accuracy with 1.13 TOps/s for ResNet-152, respectively. Thereby, the required memory footprint for parameters is reduced by 4.9x and 9.4x compared to the respective floating-point baseline.
Cascaded Classifier for Pareto-Optimal Accuracy-Cost Trade-Off Using off-the-Shelf ANNs
Oct 27, 2021



Machine-learning classifiers provide high quality of service in classification tasks. Research now targets cost reduction measured in terms of average processing time or energy per solution. Revisiting the concept of cascaded classifiers, we present a first of its kind analysis of optimal pass-on criteria between the classifier stages. Based on this analysis, we derive a methodology to maximize accuracy and efficiency of cascaded classifiers. On the one hand, our methodology allows cost reduction of 1.32x while preserving reference classifier's accuracy. On the other hand, it allows to scale cost over two orders while gracefully degrading accuracy. Thereby, the final classifier stage sets the top accuracy. Hence, the multi-stage realization can be employed to optimize any state-of-the-art classifier.