 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Binary Events from Continuous Time Series in Rooted Trees using Contrastive Learning
Jan 02, 2024

Broadband infrastructure owners do not always know how their customers are connected in the local networks, which are structured as rooted trees. A recent study is able to infer the topology of a local network using discrete time series data from the leaves of the tree (customers). In this study we propose a contrastive approach for learning a binary event encoder from continuous time series data. As a preliminary result, we show that our approach has some potential in learning a valuable encoder.
Compressing CNN Kernels for Videos Using Tucker Decompositions: Towards Lightweight CNN Applications
Mar 10, 2022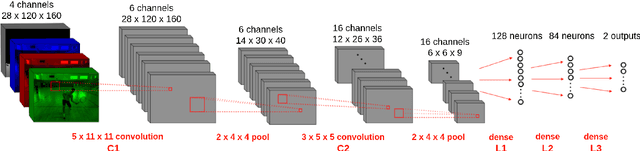
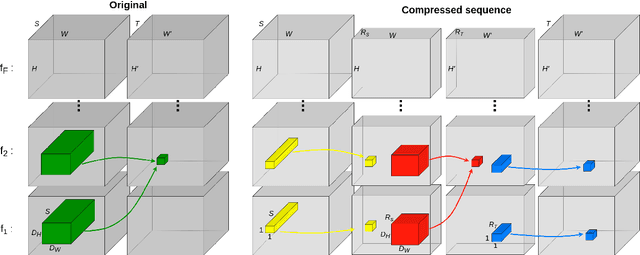
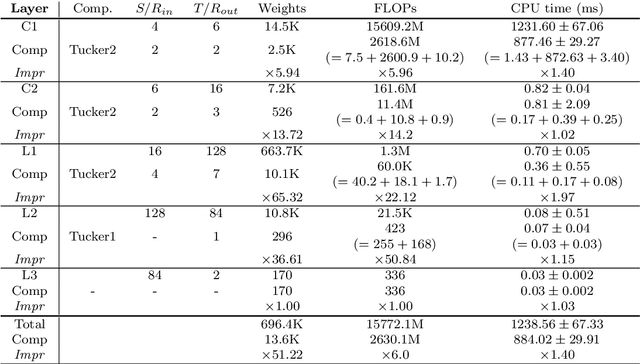
Convolutional Neural Networks (CNN) are the state-of-the-art in the field of visual computing. However, a major problem with CNNs is the large number of floating point operations (FLOPs) required to perform convolutions for large inputs. When considering the application of CNNs to video data, convolutional filters become even more complex due to the extra temporal dimension. This leads to problems when respective applications are to be deployed on mobile devices, such as smart phones, tablets, micro-controllers or similar, indicating less computational power. Kim et al. (2016) proposed using a Tucker-decomposition to compress the convolutional kernel of a pre-trained network for images in order to reduce the complexity of the network, i.e. the number of FLOPs. In this paper, we generalize the aforementioned method for application to videos (and other 3D signals) and evaluate the proposed method on a modified version of the THETIS data set, which contains videos of individuals performing tennis shots. We show that the compressed network reaches comparable accuracy, while indicating a memory compression by a factor of 51. However, the actual computational speed-up (factor 1.4) does not meet our theoretically derived expectation (factor 6).