 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixel-based Domain-Knowledge Infusion in Computer Vision
May 20, 2021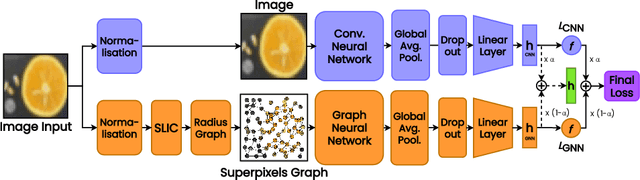

Superpixels are higher-order perceptual groups of pixels in an image, often carrying much more information than raw pixels. There is an inherent relational structure to the relationship among different superpixels of an image. This relational information can convey some form of domain information about the image, e.g. relationship between superpixels representing two eyes in a cat image. Our interest in this paper is to construct computer vision models, specifically those based on Deep Neural Networks (DNNs) to incorporate these superpixels information. We propose a methodology to construct a hybrid model that leverages (a) Convolutional Neural Network (CNN) to deal with spatial information in an image, and (b) Graph Neural Network (GNN) to deal with relational superpixel information in the image. The proposed deep model is learned using a generic hybrid loss function that we call a `hybrid' loss. We evaluate the predictive performance of our proposed hybrid vision model on four popular image classification datasets: MNIST, FMNIST, CIFAR-10 and CIFAR-100. Moreover, we evaluate our method on three real-world classification tasks: COVID-19 X-Ray Detection, LFW Face Recognition, and SOCOFing Fingerprint Identification. The results demonstrate that the relational superpixel information provided via a GNN could improve the performance of standard CNN-based vision systems.
Incorporating Domain Knowledge into Deep Neural Networks
Mar 15, 2021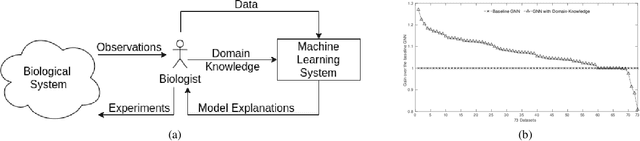
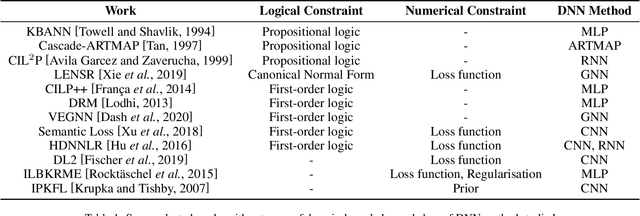
We present a survey of ways in which domain-knowledge has been included when constructing models with neural networks. The inclusion of domain-knowledge is of special interest not just to constructing scientific assistants, but also, many other areas that involve understanding data using human-machine collaboration. In many such instances, machine-based model construction may benefit significantly from being provided with human-knowledge of the domain encoded in a sufficiently precise form. This paper examines two broad approaches to encode such knowledge--as logical and numerical constraints--and describes techniques and results obtained in several sub-categories under each of these approaches.
LRG at SemEval-2021 Task 4: Improving Reading Comprehension with Abstract Words using Augmentation, Linguistic Features and Voting
Feb 24, 2021
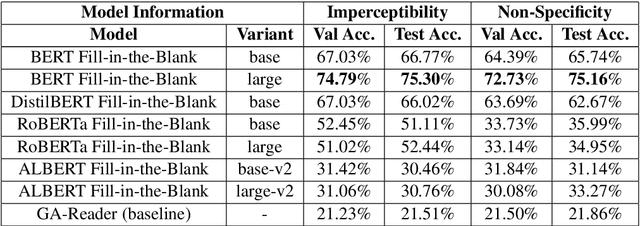
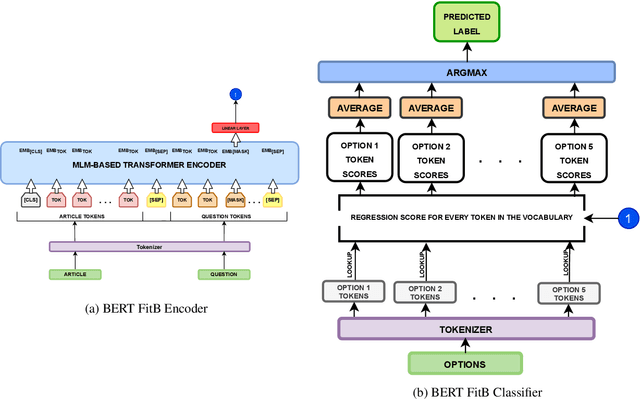
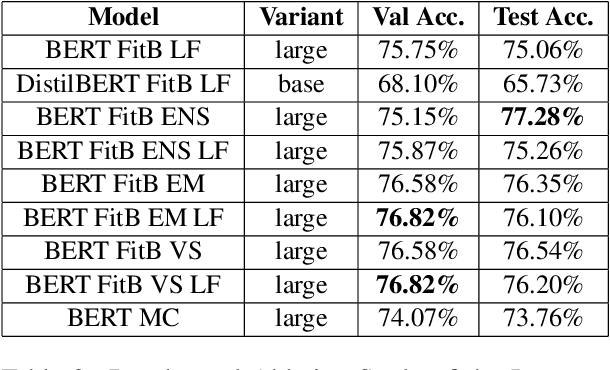
In this article, we present our methodologies for SemEval-2021 Task-4: Reading Comprehension of Abstract Meaning. Given a fill-in-the-blank-type question and a corresponding context, the task is to predict the most suitable word from a list of 5 options. There are three sub-tasks within this task: Imperceptibility (subtask-I), Non-Specificity (subtask-II), and Intersection (subtask-III). We use encoders of transformers-based models pre-trained on the masked language modelling (MLM) task to build our Fill-in-the-blank (FitB) models. Moreover, to model imperceptibility, we define certain linguistic features, and to model non-specificity, we leverage information from hypernyms and hyponyms provided by a lexical database. Specifically, for non-specificity, we try out augmentation techniques, and other statistical techniques. We also propose variants, namely Chunk Voting and Max Context, to take care of input length restrictions for BERT, etc. Additionally, we perform a thorough ablation study, and use Integrated Gradients to explain our predictions on a few samples. Our best submissions achieve accuracies of 75.31% and 77.84%, on the test sets for subtask-I and subtask-II, respectively. For subtask-III, we achieve accuracies of 65.64% and 62.27%.
Constructing and Evaluating an Explainable Model for COVID-19 Diagnosis from Chest X-rays
Dec 19, 2020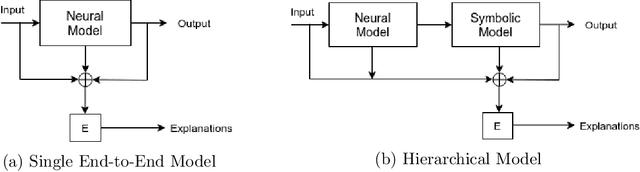
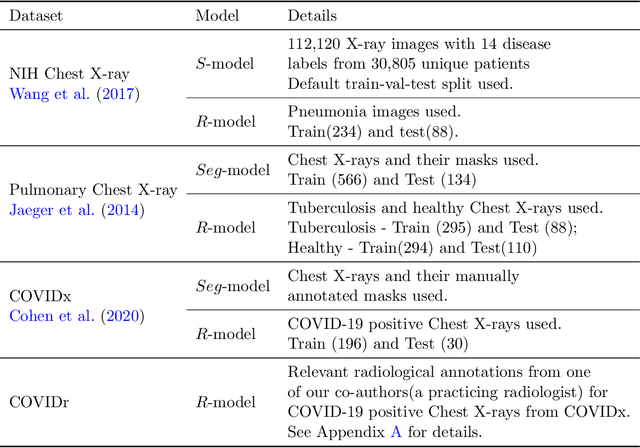
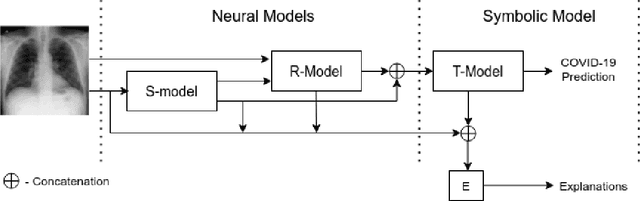
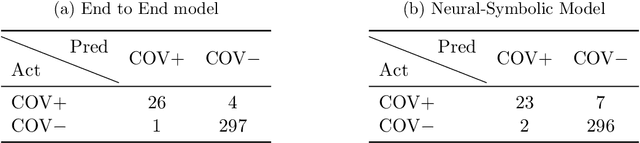
In this paper, our focus is on constructing models to assist a clinician in the diagnosis of COVID-19 patients in situations where it is easier and cheaper to obtain X-ray data than to obtain high-quality images like those from CT scans. Deep neural networks have repeatedly been shown to be capable of constructing highly predictive models for disease detection directly from image data. However, their use in assisting clinicians has repeatedly hit a stumbling block due to their black-box nature. Some of this difficulty can be alleviated if predictions were accompanied by explanations expressed in clinically relevant terms. In this paper, deep neural networks are used to extract domain-specific features(morphological features like ground-glass opacity and disease indications like pneumonia) directly from the image data. Predictions about these features are then used to construct a symbolic model (a decision tree) for the diagnosis of COVID-19 from chest X-rays, accompanied with two kinds of explanations: visual (saliency maps, derived from the neural stage), and textual (logical descriptions, derived from the symbolic stage). A radiologist rates the usefulness of the visual and textual explanations. Our results demonstrate that neural models can be employed usefully in identifying domain-specific features from low-level image data; that textual explanations in terms of clinically relevant features may be useful; and that visual explanations will need to be clinically meaningful to be useful.
Incorporating Symbolic Domain Knowledge into Graph Neural Networks
Oct 23, 2020
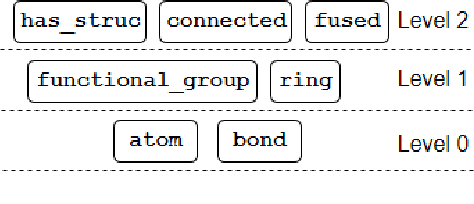
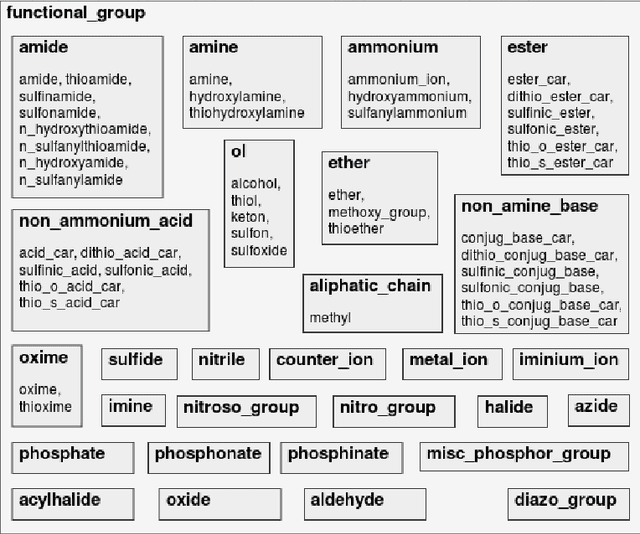
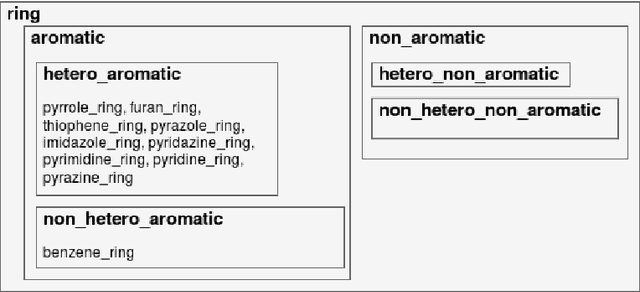
Our interest is in scientific problems with the following characteristics: (1) Data are naturally represented as graphs; (2) The amount of data available is typically small; and (3) There is significant domain-knowledge, usually expressed in some symbolic form. These kinds of problems have been addressed effectively in the past by Inductive Logic Programming (ILP), by virtue of 2 important characteristics: (a) The use of a representation language that easily captures the relation encoded in graph-structured data, and (b) The inclusion of prior information encoded as domain-specific relations, that can alleviate problems of data scarcity, and construct new relations. Recent advances have seen the emergence of deep neural networks specifically developed for graph-structured data (Graph-based Neural Networks, or GNNs). While GNNs have been shown to be able to handle graph-structured data, less has been done to investigate the inclusion of domain-knowledge. Here we investigate this aspect of GNNs empirically by employing an operation we term "vertex-enrichment" and denote the corresponding GNNs as "VEGNNs". Using over 70 real-world datasets and substantial amounts of symbolic domain-knowledge, we examine the result of vertex-enrichment across 5 different variants of GNNs. Our results provide support for the following: (a) Inclusion of domain-knowledge by vertex-enrichment can significantly improve the performance of a GNN. That is, the performance VEGNNs is significantly better than GNNs across all GNN variants; (b) The inclusion of domain-specific relations constructed using ILP improves the performance of VEGNNs, across all GNN variants. Taken together, the results provide evidence that it is possible to incorporate symbolic domain knowledge into a GNN, and that ILP can play an important role in providing high-level relationships that are not easily discovered by a GNN.
Performance evaluation of deep neural networks for forecasting time-series with multiple structural breaks and high volatility
Nov 14, 2019
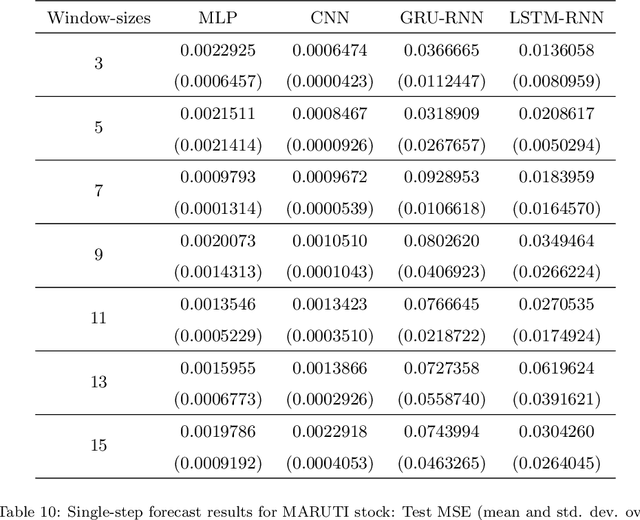
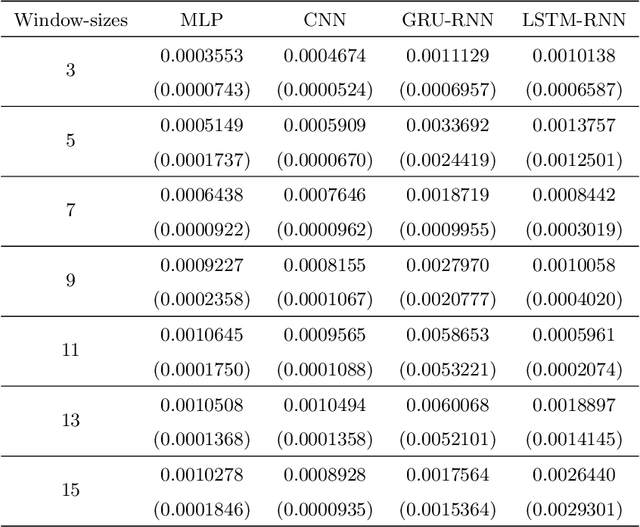
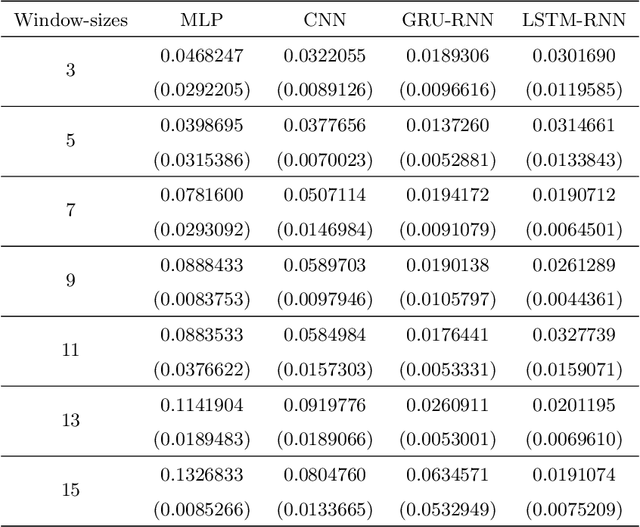
The problem of automatic forecasting of time-series data has been a long-standing challenge for the machine learning and forecasting community. The problem is relatively simple when the series is stationary. However, the majority of the real-world time-series problems have non-stationary characteristics making the understanding of the trend and seasonality very complex. Further, it is assumed that the future response is dependent on the past data and, therefore, can be modeled using a function approximator. Our interest in this paper is to study the applicability of the popular deep neural networks (DNN) comprehensively as function approximators for non-stationary time-series forecasting. We employ the following DNN models: Multi-layer Perceptron (MLP), Convolutional Neural Network (CNN), and RNN with Long-Short Term Memory (LSTM-RNN) and RNN with Gated-Recurrent Unit (GRU-RNN). These powerful DNN methods have been evaluated over popular Indian financial stocks data comprising of five stocks from National Stock Exchange Nifty-50 (NSE-Nifty50), and five stocks from Bombay Stock Exchange 30 (BSE-30). Further, the performance evaluation of these DNNs in terms of their predictive power has been done using two fashions: (1) single-step forecasting, (2) multi-step forecasting. Our extensive simulation experiments on these ten datasets report that the performance of these DNNs for single-step forecasting is pretty convincing as the predictions are found to follow the truely observed values closely. However, we also find that all these DNN models perform miserably in the case of multi-step time-series forecasting, based on the datasets used by us. Consequently, we observe that none of these DNN models are reliable for multi-step time-series forecasting.
A study on the use of Boundary Equilibrium GAN for Approximate Frontalization of Unconstrained Faces to aid in Surveillance
Sep 14, 2018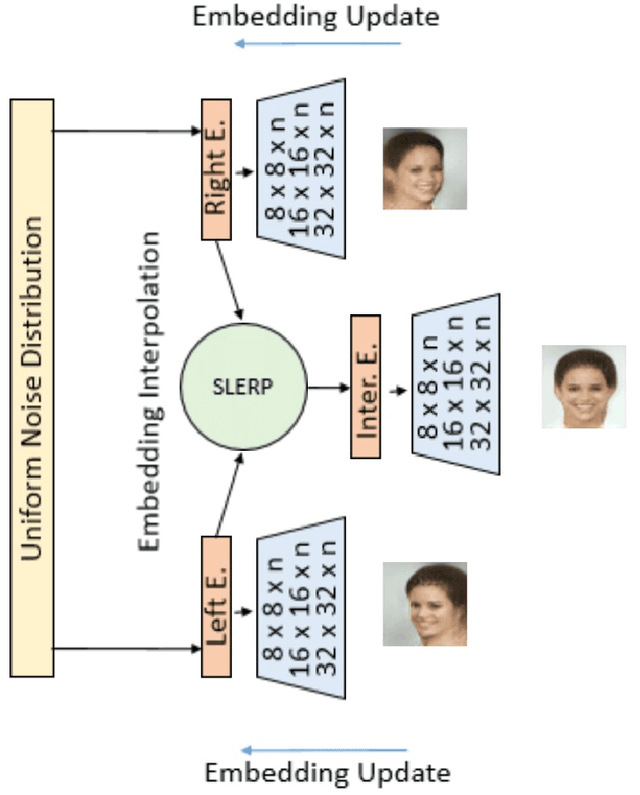

Face frontalization is the process of synthesizing frontal facing views of faces given its angled poses. We implement a generative adversarial network (GAN) with spherical linear interpolation (Slerp) for frontalization of unconstrained facial images. Our special focus is intended towards the generation of approximate frontal faces of the side posed images captured from surveillance cameras. Specifically, the present work is a comprehensive study on the implementation of an auto-encoder based Boundary Equilibrium GAN (BEGAN) to generate frontal faces using an interpolation of a side view face and its mirrored view. To increase the quality of the interpolated output we implement a BEGAN with Slerp. This approach could produce a promising output along with a faster and more stable training for the model. The BEGAN model additionally has a balanced generator-discriminator combination, which prevents mode collapse along with a global convergence measure. It is expected that such an approximate face generation model would be able to replace face composites used in surveillance and crime detection.
Reliable Evaluation of Neural Network for Multiclass Classification of Real-world Data
Nov 30, 2016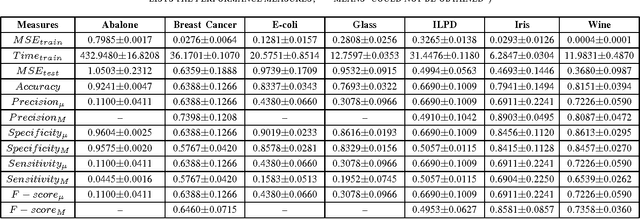
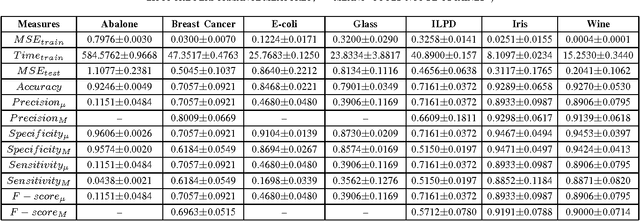
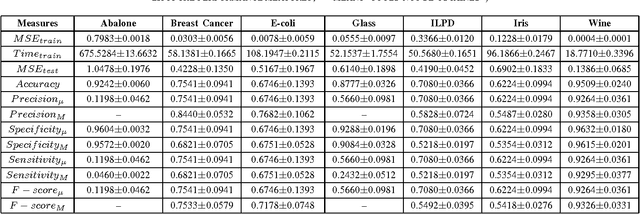
This paper presents a systematic evaluation of Neural Network (NN) for classification of real-world data. In the field of machine learning, it is often seen that a single parameter that is 'predictive accuracy' is being used for evaluating the performance of a classifier model. However, this parameter might not be considered reliable given a dataset with very high level of skewness. To demonstrate such behavior, seven different types of datasets have been used to evaluate a Multilayer Perceptron (MLP) using twelve(12) different parameters which include micro- and macro-level estimation. In the present study, the most common problem of prediction called 'multiclass' classification has been considered. The results that are obtained for different parameters for each of the dataset could demonstrate interesting findings to support the usability of these set of performance evaluation parameters.
A Fuzzy MLP Approach for Non-linear Pattern Classification
Sep 19, 2015

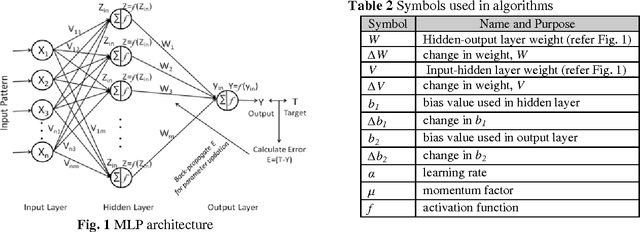
In case of decision making problems, classification of pattern is a complex and crucial task. Pattern classification using multilayer perceptron (MLP) trained with back propagation learning becomes much complex with increase in number of layers, number of nodes and number of epochs and ultimate increases computational time [31]. In this paper, an attempt has been made to use fuzzy MLP and its learning algorithm for pattern classification. The time and space complexities of the algorithm have been analyzed. A training performance comparison has been carried out between MLP and the proposed fuzzy-MLP model by considering six cases. Results are noted against different learning rates ranging from 0 to 1. A new performance evaluation factor 'convergence gain' has been introduced. It is observed that the number of epochs drastically reduced and performance increased compared to MLP. The average and minimum gain has been found to be 93% and 75% respectively. The best gain is found to be 95% and is obtained by setting the learning rate to 0.55.
* The final version of this paper has been published in "International Conference on Communication and Computing (ICC-2014)" [http://www.elsevierst.com/conference_book_download_chapter.php?cbid=86#chapter41]
Non-Correlated Character Recognition using Artificial Neural Network
Jun 19, 2013This paper investigates a method of Handwritten English Character Recognition using Artificial Neural Network (ANN). This work has been done in offline Environment for non correlated characters, which do not possess any linear relationships among them. We test that whether the particular tested character belongs to a cluster or not. The implementation is carried out in Matlab environment and successfully tested. Fifty-two sets of English alphabets are used to train the ANN and test the network. The algorithms are tested with 26 capital letters and 26 small letters. The testing result showed that the proposed ANN based algorithm showed a maximum recognition rate of 85%.
* appeared in: proceedings of National Conference on Dynamics and Prospects of Data Mining: Theory and Practices (DPDM)-2012; September 30, 2012, India; Publisher: OITS-BLS, Balasore Chapter; Proceeding ISBN: 987-93-81361-31-6, pp. 79-83