 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-hop Fairness: Addressing Disparities in Graph Link Prediction Beyond First-Order Neighborhoods
Mar 04, 2026Link prediction (LP) plays a central role in graph-based applications, particularly in social recommendation. However, real-world graphs often reflect structural biases, most notably homophily, the tendency of nodes with similar attributes to connect. While this property can improve predictive performance, it also risks reinforcing existing social disparities. In response, fairness-aware LP methods have emerged, often seeking to mitigate these effects by promoting inter-group connections, that is, links between nodes with differing sensitive attributes (e.g., gender), following the principle of dyadic fairness. However, dyadic fairness overlooks potential disparities within the sensitive groups themselves. To overcome this issue, we propose $k$-hop fairness, a structural notion of fairness for LP, that assesses disparities conditioned on the distance between nodes in the graph. We formalize this notion through predictive fairness and structural bias metrics, and propose pre- and post-processing mitigation strategies. Experiments across standard LP benchmarks reveal: (1) a strong tendency of models to reproduce structural biases at different $k$-hops; (2) interdependence between structural biases at different hops when rewiring graphs; and (3) that our post-processing method achieves favorable $k$-hop performance-fairness trade-offs compared to existing fair LP baselines.
TopoFair: Linking Topological Bias to Fairness in Link Prediction Benchmarks
Feb 12, 2026Graph link prediction (LP) plays a critical role in socially impactful applications, such as job recommendation and friendship formation. Ensuring fairness in this task is thus essential. While many fairness-aware methods manipulate graph structures to mitigate prediction disparities, the topological biases inherent to social graph structures remain poorly understood and are often reduced to homophily alone. This undermines the generalization potential of fairness interventions and limits their applicability across diverse network topologies. In this work, we propose a novel benchmarking framework for fair LP, centered on the structural biases of the underlying graphs. We begin by reviewing and formalizing a broad taxonomy of topological bias measures relevant to fairness in graphs. In parallel, we introduce a flexible graph generation method that simultaneously ensures fidelity to real-world graph patterns and enables controlled variation across a wide spectrum of structural biases. We apply this framework to evaluate both classical and fairness-aware LP models across multiple use cases. Our results provide a fine-grained empirical analysis of the interactions between predictive fairness and structural biases. This new perspective reveals the sensitivity of fairness interventions to beyond-homophily biases and underscores the need for structurally grounded fairness evaluations in graph learning.
Modeling Musical Genre Trajectories through Pathlet Learning
May 06, 2025The increasing availability of user data on music streaming platforms opens up new possibilities for analyzing music consumption. However, understanding the evolution of user preferences remains a complex challenge, particularly as their musical tastes change over time. This paper uses the dictionary learning paradigm to model user trajectories across different musical genres. We define a new framework that captures recurring patterns in genre trajectories, called pathlets, enabling the creation of comprehensible trajectory embeddings. We show that pathlet learning reveals relevant listening patterns that can be analyzed both qualitatively and quantitatively. This work improves our understanding of users' interactions with music and opens up avenues of research into user behavior and fostering diversity in recommender systems. A dataset of 2000 user histories tagged by genre over 17 months, supplied by Deezer (a leading music streaming company), is also released with the code.
Graph as a feature: improving node classification with non-neural graph-aware logistic regression
Nov 19, 2024Graph Neural Networks (GNNs) and their message passing framework that leverages both structural and feature information, have become a standard method for solving graph-based machine learning problems. However, these approaches still struggle to generalise well beyond datasets that exhibit strong homophily, where nodes of the same class tend to connect. This limitation has led to the development of complex neural architectures that pose challenges in terms of efficiency and scalability. In response to these limitations, we focus on simpler and more scalable approaches and introduce Graph-aware Logistic Regression (GLR), a non-neural model designed for node classification tasks. Unlike traditional graph algorithms that use only a fraction of the information accessible to GNNs, our proposed model simultaneously leverages both node features and the relationships between entities. However instead of relying on message passing, our approach encodes each node's relationships as an additional feature vector, which is then combined with the node's self attributes. Extensive experimental results, conducted within a rigorous evaluation framework, show that our proposed GLR approach outperforms both foundational and sophisticated state-of-the-art GNN models in node classification tasks. Going beyond the traditional limited benchmarks, our experiments indicate that GLR increases generalisation ability while reaching performance gains in computation time up to two orders of magnitude compared to it best neural competitor.
Evaluating graph-based explanations for AI-based recommender systems
Jul 17, 2024



Recent years have witnessed a rapid growth of recommender systems, providing suggestions in numerous applications with potentially high social impact, such as health or justice. Meanwhile, in Europe, the upcoming AI Act mentions \emph{transparency} as a requirement for critical AI systems in order to ``mitigate the risks to fundamental rights''. Post-hoc explanations seamlessly align with this goal and extensive literature on the subject produced several forms of such objects, graphs being one of them. Early studies in visualization demonstrated the graphs' ability to improve user understanding, positioning them as potentially ideal explanations. However, it remains unclear how graph-based explanations compare to other explanation designs. In this work, we aim to determine the effectiveness of graph-based explanations in improving users' perception of AI-based recommendations using a mixed-methods approach. We first conduct a qualitative study to collect users' requirements for graph explanations. We then run a larger quantitative study in which we evaluate the influence of various explanation designs, including enhanced graph-based ones, on aspects such as understanding, usability and curiosity toward the AI system. We find that users perceive graph-based explanations as more usable than designs involving feature importance. However, we also reveal that textual explanations lead to higher objective understanding than graph-based designs. Most importantly, we highlight the strong contrast between participants' expressed preferences for graph design and their actual ratings using it, which are lower compared to textual design. These findings imply that meeting stakeholders' expressed preferences might not alone guarantee ``good'' explanations. Therefore, crafting hybrid designs successfully balancing social expectations with downstream performance emerges as a significant challenge.
Exploring and mining attributed sequences of interactions
Jul 28, 2021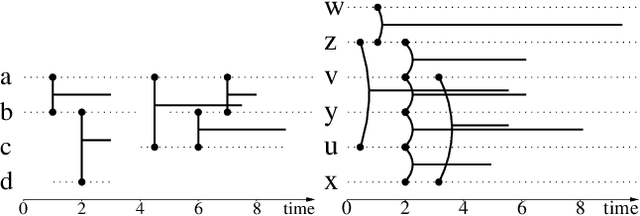
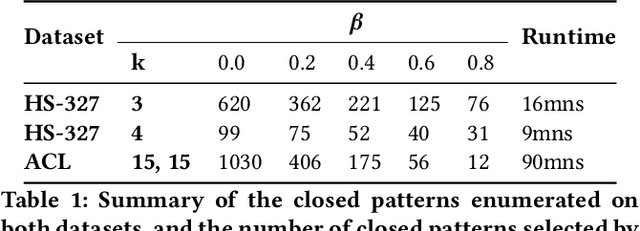
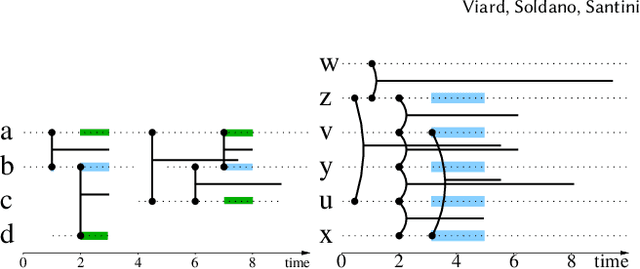
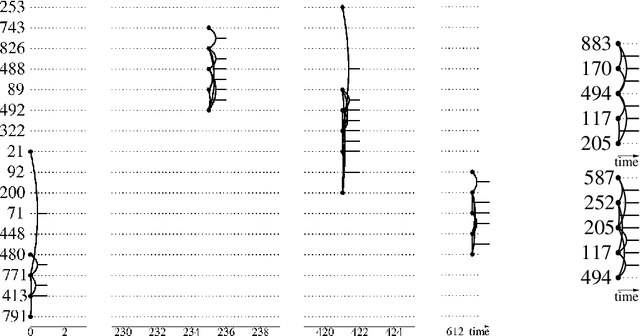
We are faced with data comprised of entities interacting over time: this can be individuals meeting, customers buying products, machines exchanging packets on the IP network, among others. Capturing the dynamics as well as the structure of these interactions is of crucial importance for analysis. These interactions can almost always be labeled with content: group belonging, reviews of products, abstracts, etc. We model these stream of interactions as stream graphs, a recent framework to model interactions over time. Formal Concept Analysis provides a framework for analyzing concepts evolving within a context. Considering graphs as the context, it has recently been applied to perform closed pattern mining on social graphs. In this paper, we are interested in pattern mining in sequences of interactions. After recalling and extending notions from formal concept analysis on graphs to stream graphs, we introduce algorithms to enumerate closed patterns on a labeled stream graph, and introduce a way to select relevant closed patterns. We run experiments on two real-world datasets of interactions among students and citations between authors, and show both the feasibility and the relevance of our method.
Classifying Wikipedia in a fine-grained hierarchy: what graphs can contribute
Jan 22, 2020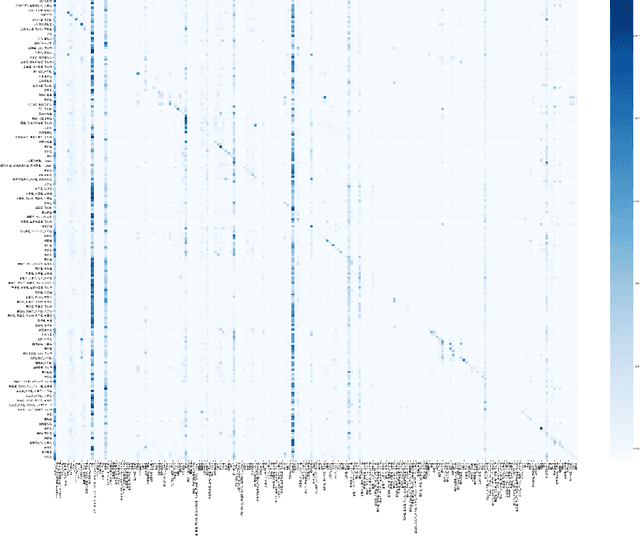
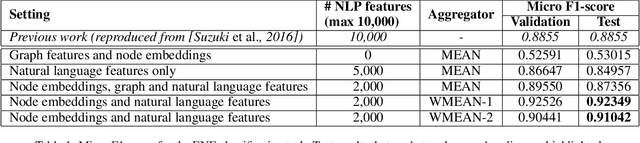
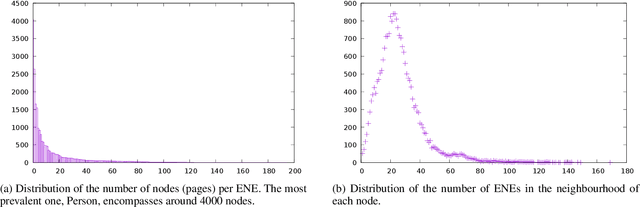
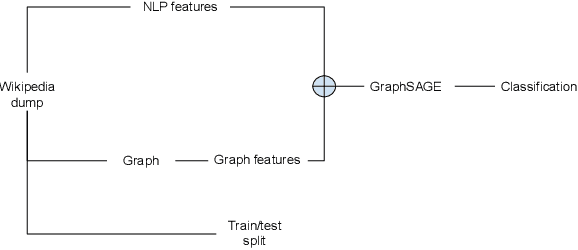
Wikipedia is a huge opportunity for machine learning, being the largest semi-structured base of knowledge available. Because of this, many works examine its contents, and focus on structuring it in order to make it usable in learning tasks, for example by classifying it into an ontology. Beyond its textual contents, Wikipedia also displays a typical graph structure, where pages are linked together through citations. In this paper, we address the task of integrating graph (i.e. structure) information to classify Wikipedia into a fine-grained named entity ontology (NE), the Extended Named Entity hierarchy. To address this task, we first start by assessing the relevance of the graph structure for NE classification. We then explore two directions, one related to feature vectors using graph descriptors commonly used in large-scale network analysis, and one extending flat classification to a weighted model taking into account semantic similarity. We conduct at-scale practical experiments, on a manually labeled subset of 22,000 pages extracted from the Japanese Wikipedia. Our results show that integrating graph information succeeds at reducing sparsity of the input feature space, and yields classification results that are comparable or better than previous works.
Stream Graphs and Link Streams for the Modeling of Interactions over Time
Oct 11, 2017

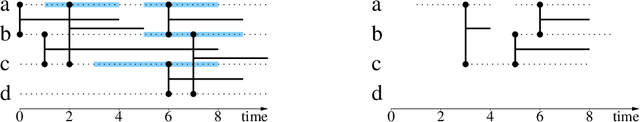
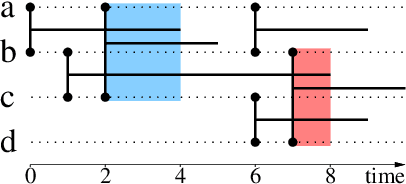
Graph theory provides a language for studying the structure of relations, and it is often used to study interactions over time too. However, it poorly captures the both temporal and structural nature of interactions, that calls for a dedicated formalism. In this paper, we generalize graph concepts in order to cope with both aspects in a consistent way. We start with elementary concepts like density, clusters, or paths, and derive from them more advanced concepts like cliques, degrees, clustering coefficients, or connected components. We obtain a language to directly deal with interactions over time, similar to the language provided by graphs to deal with relations. This formalism is self-consistent: usual relations between different concepts are preserved. It is also consistent with graph theory: graph concepts are special cases of the ones we introduce. This makes it easy to generalize higher-level objects such as quotient graphs, line graphs, k-cores, and centralities. This paper also considers discrete versus continuous time assumptions, instantaneous links, and extensions to more complex cases.