 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Synthesizing Expressive Violin Performances: Approaches and Comparisons
Jun 26, 2024



Expressive music synthesis (EMS) for violin performance is a challenging task due to the disagreement among music performers in the interpretation of expressive musical terms (EMTs), scarcity of labeled recordings, and limited generalization ability of the synthesis model. These challenges create trade-offs between model effectiveness, diversity of generated results, and controllability of the synthesis system, making it essential to conduct a comparative study on EMS model design. This paper explores two violin EMS approaches. The end-to-end approach is a modification of a state-of-the-art text-to-speech generator. The parameter-controlled approach is based on a simple parameter sampling process that can render note lengths and other parameters compatible with MIDI-DDSP. We study these two approaches (in total, three model variants) through objective and subjective experiments and discuss several key issues of EMS based on the results.
MOSA: Music Motion with Semantic Annotation Dataset for Cross-Modal Music Processing
Jun 10, 2024



In cross-modal music processing, translation between visual, auditory, and semantic content opens up new possibilities as well as challenges. The construction of such a transformative scheme depends upon a benchmark corpus with a comprehensive data infrastructure. In particular, the assembly of a large-scale cross-modal dataset presents major challenges. In this paper, we present the MOSA (Music mOtion with Semantic Annotation) dataset, which contains high quality 3-D motion capture data, aligned audio recordings, and note-by-note semantic annotations of pitch, beat, phrase, dynamic, articulation, and harmony for 742 professional music performances by 23 professional musicians, comprising more than 30 hours and 570 K notes of data. To our knowledge, this is the largest cross-modal music dataset with note-level annotations to date. To demonstrate the usage of the MOSA dataset, we present several innovative cross-modal music information retrieval (MIR) and musical content generation tasks, including the detection of beats, downbeats, phrase, and expressive contents from audio, video and motion data, and the generation of musicians' body motion from given music audio. The dataset and codes are available alongside this publication (https://github.com/yufenhuang/MOSA-Music-mOtion-and-Semantic-Annotation-dataset).
Personalized TV Recommendation: Fusing User Behavior and Preferences
Aug 30, 2020
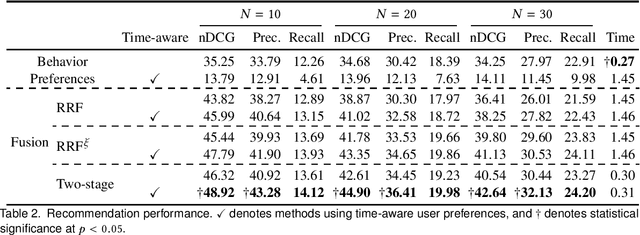
In this paper, we propose a two-stage ranking approach for recommending linear TV programs. The proposed approach first leverages user viewing patterns regarding time and TV channels to identify potential candidates for recommendation and then further leverages user preferences to rank these candidates given textual information about programs. To evaluate the method, we conduct empirical studies on a real-world TV dataset, the results of which demonstrate the superior performance of our model in terms of both recommendation accuracy and time efficiency.
Distributed Training Large-Scale Deep Architectures
Aug 10, 2017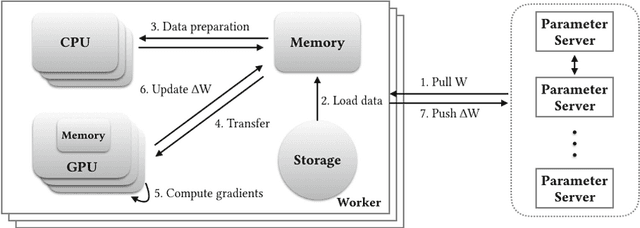
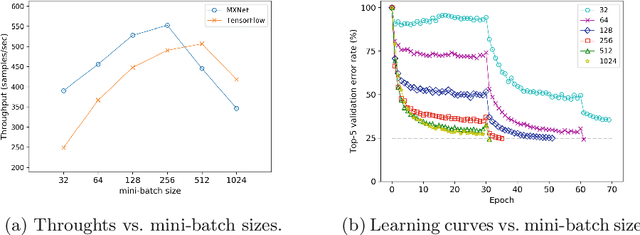
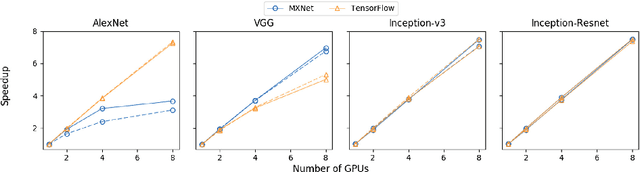
Scale of data and scale of computation infrastructures together enable the current deep learning renaissance. However, training large-scale deep architectures demands both algorithmic improvement and careful system configuration. In this paper, we focus on employing the system approach to speed up large-scale training. Via lessons learned from our routine benchmarking effort, we first identify bottlenecks and overheads that hinter data parallelism. We then devise guidelines that help practitioners to configure an effective system and fine-tune parameters to achieve desired speedup. Specifically, we develop a procedure for setting minibatch size and choosing computation algorithms. We also derive lemmas for determining the quantity of key components such as the number of GPUs and parameter servers. Experiments and examples show that these guidelines help effectively speed up large-scale deep learning training.