 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEra Splitting -- Invariant Learning for Decision Trees
Sep 27, 2023Real life machine learning problems exhibit distributional shifts in the data from one time to another or from on place to another. This behavior is beyond the scope of the traditional empirical risk minimization paradigm, which assumes i.i.d. distribution of data over time and across locations. The emerging field of out-of-distribution (OOD) generalization addresses this reality with new theory and algorithms which incorporate environmental, or era-wise information into the algorithms. So far, most research has been focused on linear models and/or neural networks. In this research we develop two new splitting criteria for decision trees, which allow us to apply ideas from OOD generalization research to decision tree models, including random forest and gradient-boosting decision trees. The new splitting criteria use era-wise information associated with each data point to allow tree-based models to find split points that are optimal across all disjoint eras in the data, instead of optimal over the entire data set pooled together, which is the default setting. We describe the new splitting criteria in detail and develop unique experiments to showcase the benefits of these new criteria, which improve metrics in our experiments out-of-sample. The new criteria are incorporated into the a state-of-the-art gradient boosted decision tree model in the Scikit-Learn code base, which is made freely available.
Deep Semi-Supervised Anomaly Detection for Finding Fraud in the Futures Market
Aug 31, 2023Modern financial electronic exchanges are an exciting and fast-paced marketplace where billions of dollars change hands every day. They are also rife with manipulation and fraud. Detecting such activity is a major undertaking, which has historically been a job reserved exclusively for humans. Recently, more research and resources have been focused on automating these processes via machine learning and artificial intelligence. Fraud detection is overwhelmingly associated with the greater field of anomaly detection, which is usually performed via unsupervised learning techniques because of the lack of labeled data needed for supervised learning. However, a small quantity of labeled data does often exist. This research article aims to evaluate the efficacy of a deep semi-supervised anomaly detection technique, called Deep SAD, for detecting fraud in high-frequency financial data. We use exclusive proprietary limit order book data from the TMX exchange in Montr\'eal, with a small set of true labeled instances of fraud, to evaluate Deep SAD against its unsupervised predecessor. We show that incorporating a small amount of labeled data into an unsupervised anomaly detection framework can greatly improve its accuracy.
Neural Options Pricing
May 27, 2021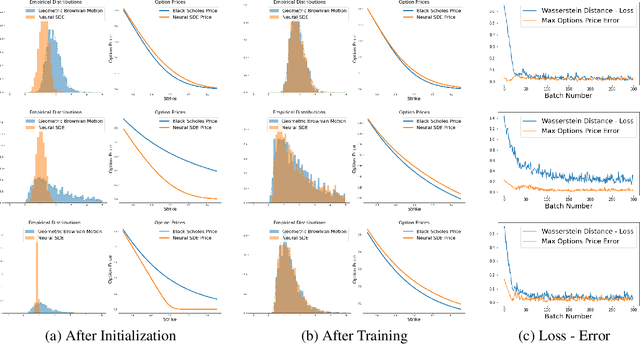
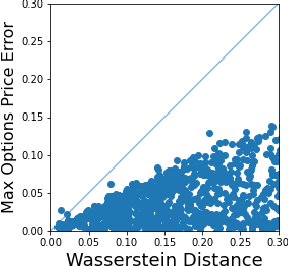
This research investigates pricing financial options based on the traditional martingale theory of arbitrage pricing applied to neural SDEs. We treat neural SDEs as universal It\^o process approximators. In this way we can lift all assumptions on the form of the underlying price process, and compute theoretical option prices numerically. We propose a variation of the SDE-GAN approach by implementing the Wasserstein distance metric as a loss function for training. Furthermore, it is conjectured that the error of the option price implied by the learnt model can be bounded by the very Wasserstein distance metric that was used to fit the empirical data.
Data Segmentation via t-SNE, DBSCAN, and Random Forest
Oct 26, 2020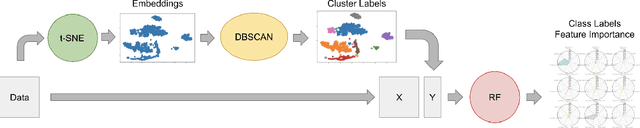
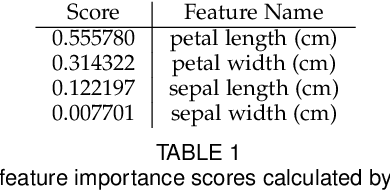
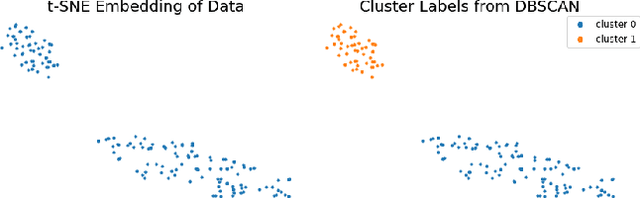
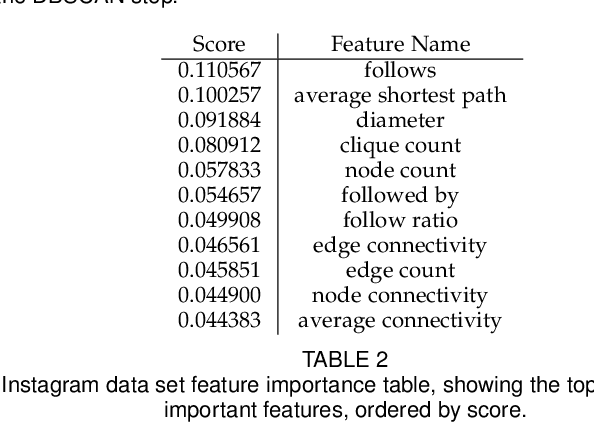
This research proposes a data segmentation technique which is easy to interpret and generalizes well. The technique combines t-SNE, DBSCAN, and Random Forest classifier algorithms to form an end-to-end pipeline that separates data into natural clusters and produces a characteristic profile of each cluster based on the most important features. Out-of-sample cluster labels can be inferred, and the technique generalizes well on real data sets. We describe the algorithm and provide case studies using the Iris and MNIST data sets, as well as real social media site data from Instagram. The main contributions of this work are the explicit identification of clusters from a t-SNE embedding, the cluster profiles, and the treatment of how these clusters generalize to out-of-sample data.